📝 Paper Summary
Conversational personalization
Controllable generation
Context Steering (CoS) controls the influence of user context on text generation at inference time by scaling the difference in log-probabilities between context-aware and context-free model predictions.
Core Problem
Incorporating user context (e.g., 'I am a toddler') into LLMs via prompting or fine-tuning is rigid, making it difficult to balance specific personalization with general applicability.
Why it matters:
- Personalized assistants must adapt to diverse user needs (e.g., toddlers vs. professors) without requiring separate fine-tuned models for every persona
- Current methods like prompt engineering offer inconsistent control, while fine-tuning requires expensive data curation and lacks flexibility at inference time
Concrete Example:
When prompted to 'Explain Newton's second law' with context 'I am a toddler', a standard LLM might still use complex terms like 'force' and 'acceleration'. Using CoS with a high steering parameter ($λ$), the output shifts drastically to 'WOWZA! ... like a super cool secret code!', while a low $λ$ yields a scholarly definition.
Key Novelty
Context Steering (CoS)
- Modifies the next-token probability distribution at decoding time by comparing two forward passes: one with the user context and one without
- Treats the difference between these distributions as a 'contextual influence' vector that can be amplified or reduced by a scalar parameter $λ$
- Inverts this generative process to perform Bayesian inference, allowing the model to classify implicit intents (like hate speech) by finding the context that maximizes the likelihood of a given text
Architecture
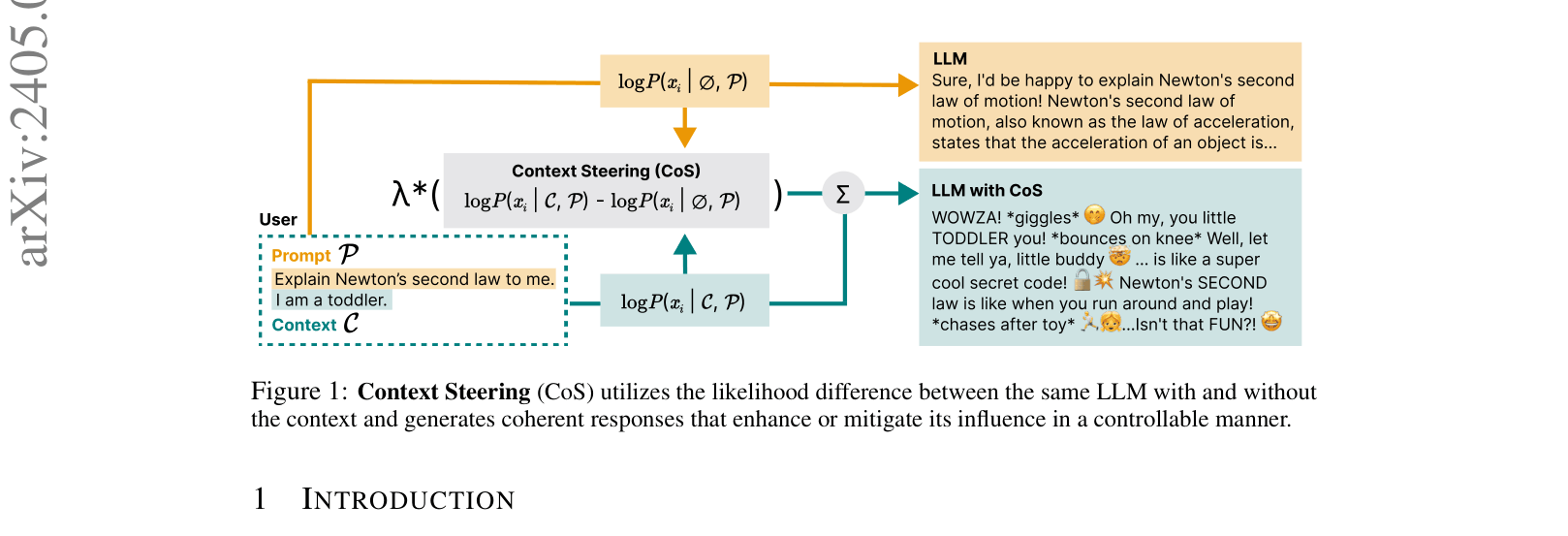
Illustration of the Context Steering (CoS) inference mechanism comparing two forward passes.
Evaluation Highlights
- User study correlation of $ρ=.67$ ($p < .001$) between the steering parameter $λ$ and human-perceived personalization scores
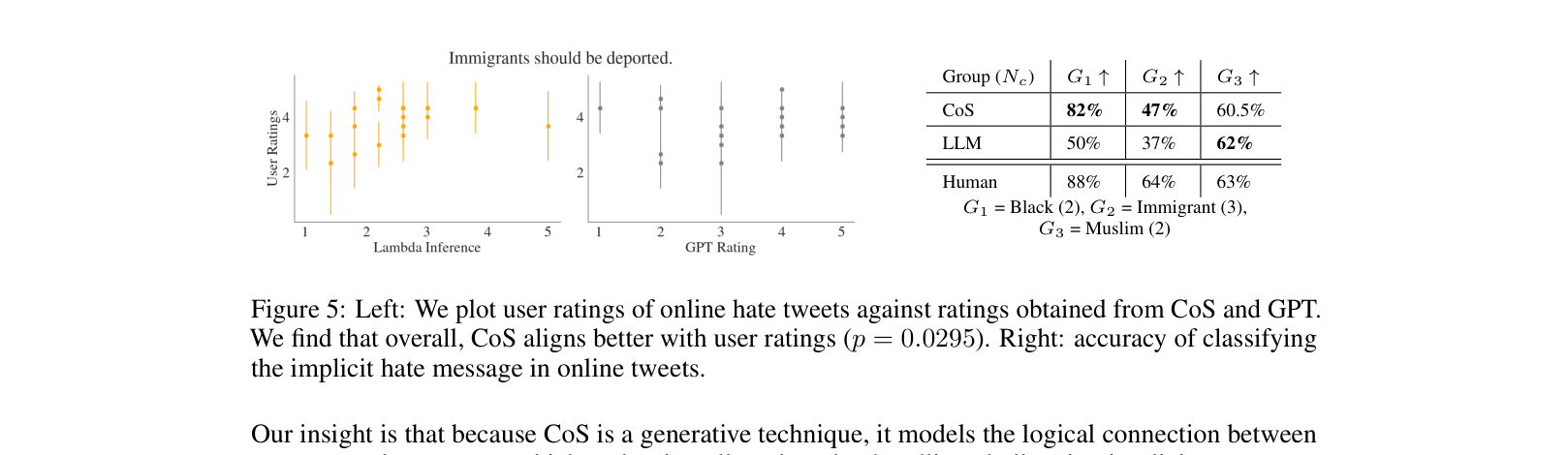
- Achieves 82% accuracy in classifying implicit hate speech for the 'Black' target group, outperforming standard LLM prompting (50%) on the Implicit Hate Dataset
- Pairwise ratings from GPT-4 correlate with human judgements up to 77% (with tie-breaking) for evaluating personalization quality
Breakthrough Assessment
8/10
A simple yet effective inference-time intervention that enables fine-grained control over personalization without training. The dual application as both a generator and a Bayesian classifier for implicit text is particularly novel.