📝 Paper Summary
Model-Heterogeneous Personalized Federated Learning (MHPFL)
Mixture of Experts (MoE)
pFedMoE improves personalized federated learning by combining a shared small expert (for general features) and a private heterogeneous expert (for personal features) via a lightweight gating network, balancing knowledge at the individual data sample level.
Core Problem
Existing Model-Heterogeneous Personalized Federated Learning (MHPFL) methods struggle to balance generalized and personalized knowledge at a fine-grained data level while maintaining model privacy and low communication costs.
Why it matters:
- Clients often have heterogeneous devices and models, making standard model-homogeneous FL impossible.
- Data is non-IID (non-independent and identically distributed) across clients, meaning a single global model fits poorly.
- Prior methods using knowledge distillation or mutual learning incur high computational costs or fail to adapt dynamically to specific data samples.
Concrete Example:
In a medical imaging scenario, one hospital uses a large ResNet while a clinic uses a small MobileNet. Standard FL fails due to architecture mismatch. Existing MHPFL methods might force them to distill knowledge via public data (privacy risk) or fix ensemble weights for all images, ignoring that some images contain unique local features needing the local expert more than the global one.
Key Novelty
Heterogeneous Local MoE with Shared Small Expert
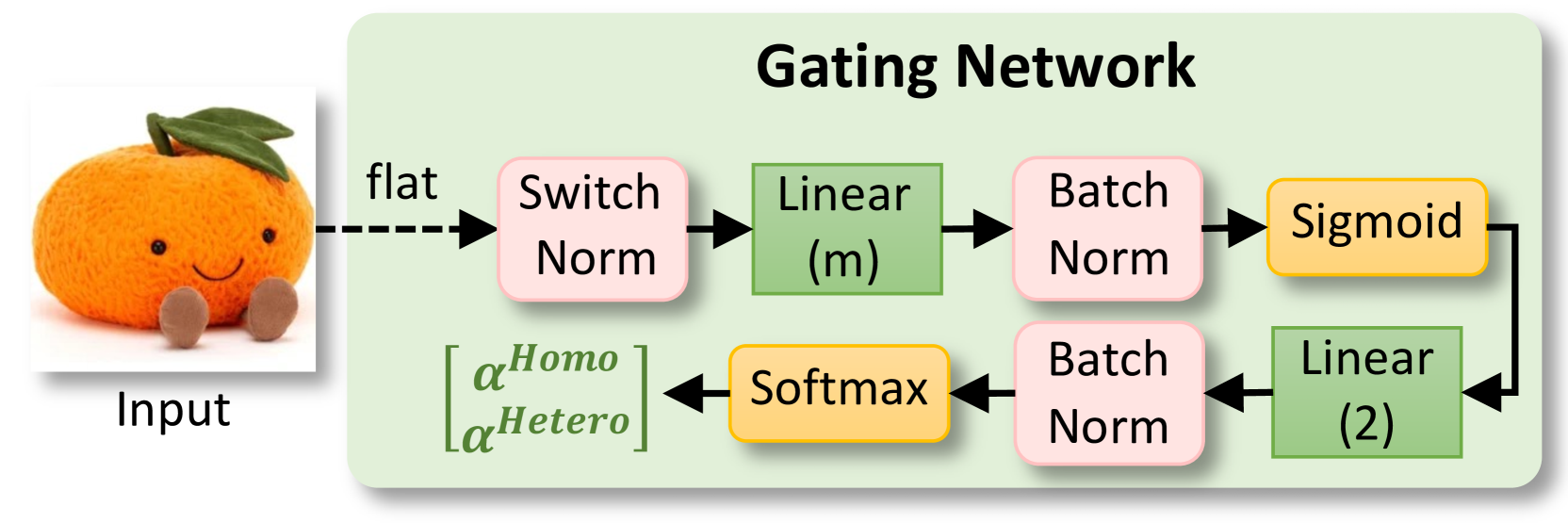
- Constructs a local Mixture of Experts (MoE) on each client comprising: (1) a private heterogeneous feature extractor (local expert), (2) a shared homogeneous small feature extractor (global expert), and (3) a gating network.
- The gating network dynamically weights the contribution of local vs. global experts for *each specific data sample*, achieving data-level personalization rather than just client-level.
- Only the small shared expert is transmitted to the server, preserving privacy and supporting completely different local model architectures.
Architecture
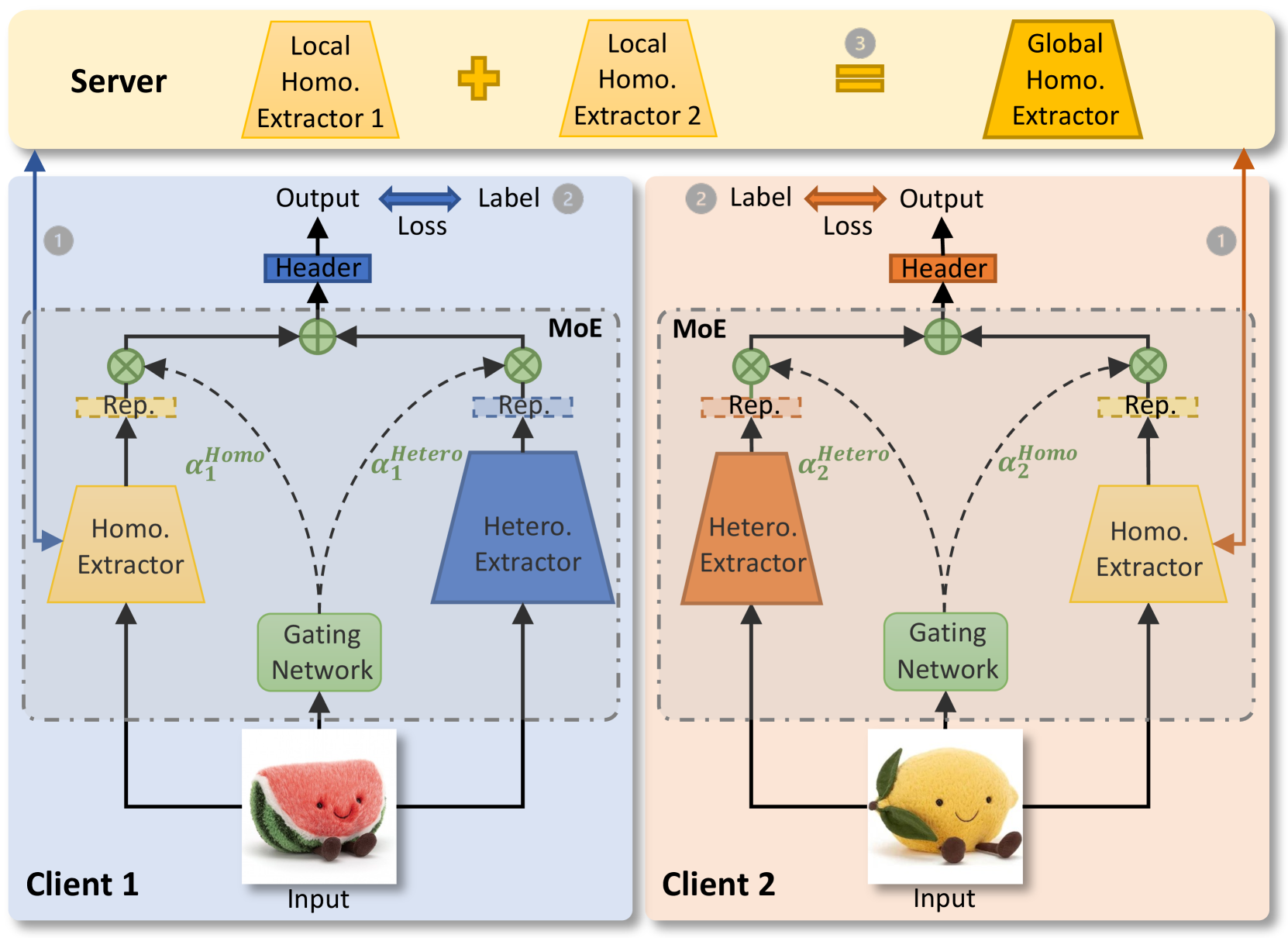
The workflow of pFedMoE, illustrating the local MoE structure and the interaction with the server.
Evaluation Highlights
- Achieves up to 2.80% higher test accuracy compared to the state-of-the-art (FedAPEN) on benchmark datasets.
- Outperforms the best baseline in the same category (model mixture methods) by up to 22.16% in specific non-IID settings.
- Significantly reduces communication costs compared to methods that transmit large models or generators, exchanging only small feature extractors.
Breakthrough Assessment
7/10
Strong conceptual advance in applying MoE to heterogeneous FL for fine-grained personalization. Results show solid improvements over SOTA, though the approach of sharing a small model is an evolution of existing split-learning/mutual-learning ideas.