📝 Paper Summary
Knowledge Unlearning
Multilingual LLMs
Most unlearning methods fail to remove facts across languages, but subspace-projection succeeds by targeting a shared interlingua structure within the model's weight space.
Core Problem
Standard unlearning methods developed for monolingual settings fail to consistently remove factual knowledge across different languages in multilingual models, often leaving residual knowledge in non-target languages or causing collateral damage.
Why it matters:
- Multilingual models share semantic subspaces, meaning removing a fact in one language doesn't guarantee its removal in others, risking safety and compliance violations (e.g., GDPR)
- Current methods rely on surface-level loss signals that don't generalize to the shared geometric structure of multilingual representations
- Incomplete unlearning creates security vulnerabilities where 'forgotten' information can be recovered by querying the model in a different language
Concrete Example:
When a fact about a fictional author is unlearned in English using Gradient Ascent, the model may successfully forget it in English but still output the original fact when queried in Spanish or Hindi.
Key Novelty
Subspace-Projection for Cross-Lingual Unlearning
- Identifies that multilingual models store facts in a shared 'interlingua' subspace (language-independent) and language-specific subspaces
- Uses subspace projection to explicitly remove the directions in weight space corresponding to the shared interlingua, ensuring the fact is inaccessible across all languages
- Operates directly on weight geometry rather than just optimizing loss on specific tokens, preventing the 'overfitting' to a single language seen in other methods
Architecture
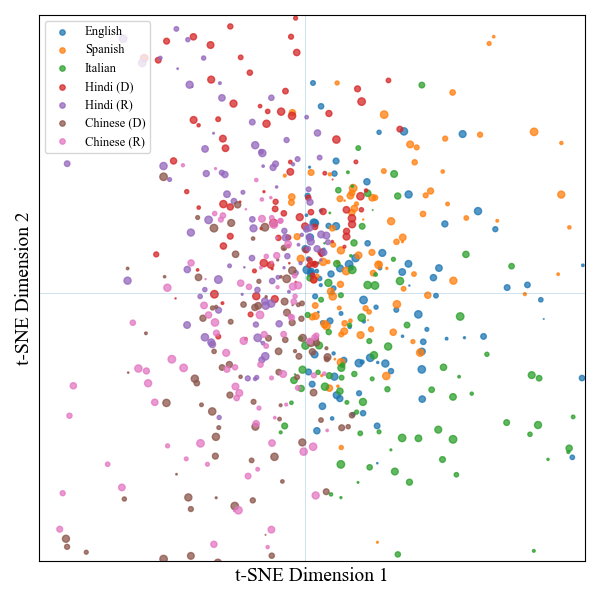
t-SNE visualization of task-specific subspaces across languages.
Evaluation Highlights
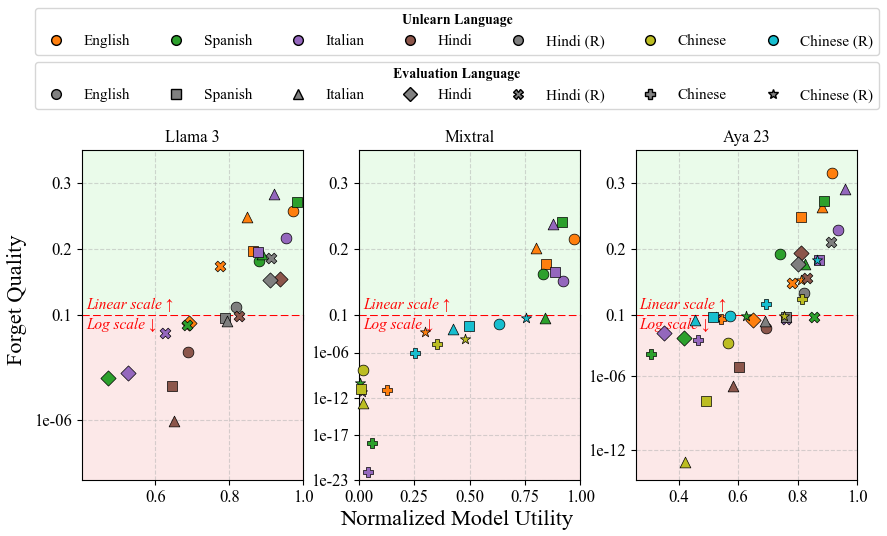
- Subspace-projection (UNLEARN) is the only method to achieve statistically significant forgetting (p > 0.1) across all language pairs while maintaining model utility near 1.0
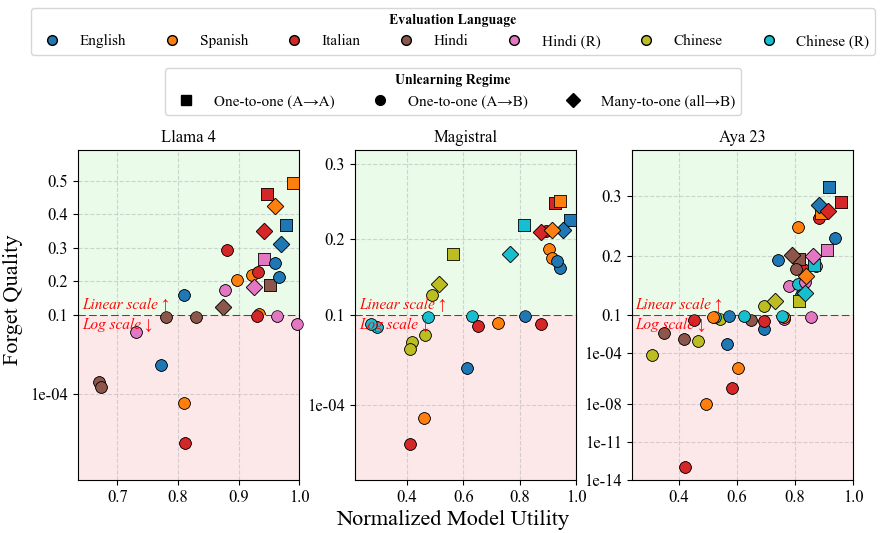
- Joint many-to-one unlearning (using multiple languages to unlearn) improves forget quality on held-out languages compared to one-to-one settings
- Transliteration experiments show that English unlearning transfers better to romanized Hindi than Devanagari Hindi, confirming script dependence in knowledge storage
Breakthrough Assessment
8/10
First comprehensive evaluation of cross-lingual unlearning revealing fundamental failures in existing methods. Identifies and successfully manipulates the 'interlingua' subspace for robust multilingual forgetting.