📝 Paper Summary
LLM-based Recommendation
Prompt Optimization
RPP optimizes prompts for individual users by employing multi-agent reinforcement learning to dynamically select sentence-level patterns for role-playing, history, reasoning, and formatting.
Core Problem
Most LLM recommenders use fixed 'task-wise' prompts shared across all users, which fails to capture individual dynamic preferences and sensitivities to prompt phrasing.
Why it matters:
- Fixed templates (e.g., fixed history length) ignore that some users have short-term interests while others have long-term preferences
- LLM performance is highly sensitive to prompt expression; a one-size-fits-all approach sacrifices potential performance gains from tailored wording
- Manual prompt engineering is labor-intensive, while supervised learning lacks 'optimal prompt' labels for training
Concrete Example:
A user preferring science fiction based on movies from two weeks ago needs a long history context, while a user preferring comedy based on the last two films needs a short history context. A fixed task-wise prompt with a static history length fails to serve both.
Key Novelty
Reinforced Prompt Personalization (RPP/RPP+)
- Frames prompt generation as a Multi-Agent Reinforcement Learning (MARL) problem where four agents collaboratively select sentences for different prompt patterns (Role, History, Reasoning, Format)
- Reduces search space by optimizing at the sentence level rather than token level, ensuring generated prompts are coherent and grammatically correct
- RPP+ introduces a dynamic 'refine' block where an LLM polishes the selected actions (sentences) during iterations to improve flexibility
Architecture
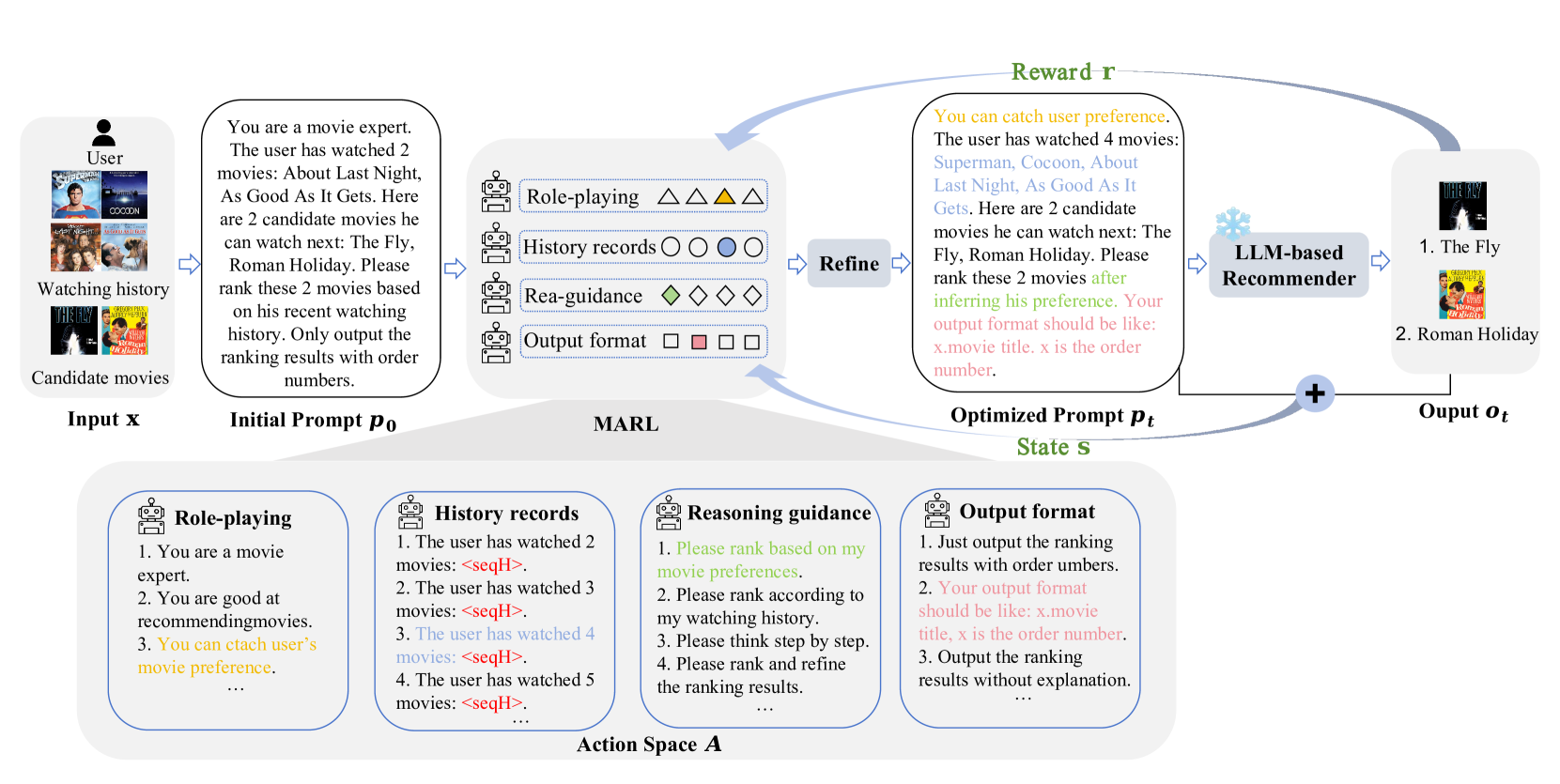
The RPP framework overview illustrating the Multi-Agent RL process.
Breakthrough Assessment
7/10
Novel application of MARL to personalize prompts per user instance (not just per task). Addresses the search space issue of RL-based prompting effectively.