📝 Paper Summary
Conversational personalization
User-profile based personalization
Contextualized counterspeech, generated by providing an LLM with community style, conversation history, and user summaries, significantly improves adequacy and persuasiveness compared to generic one-size-fits-all responses.
Core Problem
Current AI counterspeech is 'one-size-fits-all,' relying solely on the toxic input message, which fails to account for the specific user or community context required for effective persuasion.
Why it matters:
- Online toxicity causes severe social/economic costs and psychological distress, but manual moderation is unscalable and emotionally taxing for humans
- Generic automated interventions lack the nuance to actually persuade users or de-escalate conflicts, often failing to address the specific root of the toxicity
- Existing evaluation metrics (like BLEU or ROUGE) correlate poorly with human perceptions of persuasiveness in moderation contexts
Concrete Example:
A toxic comment in a political thread might be dismissed by a generic bot with a platitude about kindness. However, a contextualized model utilizing the user's history (showing they value logic over emotion) and thread context (a debate on policy) generates a counter-argument citing specific logical inconsistencies, which is more likely to engage the user civilly.
Key Novelty
Contextualized & Personalized Counterspeech Generation
- Injects three types of context into the generation prompt: Community norms (political subreddit style), Conversation history (previous thread messages), and User history (past comments or summaries)
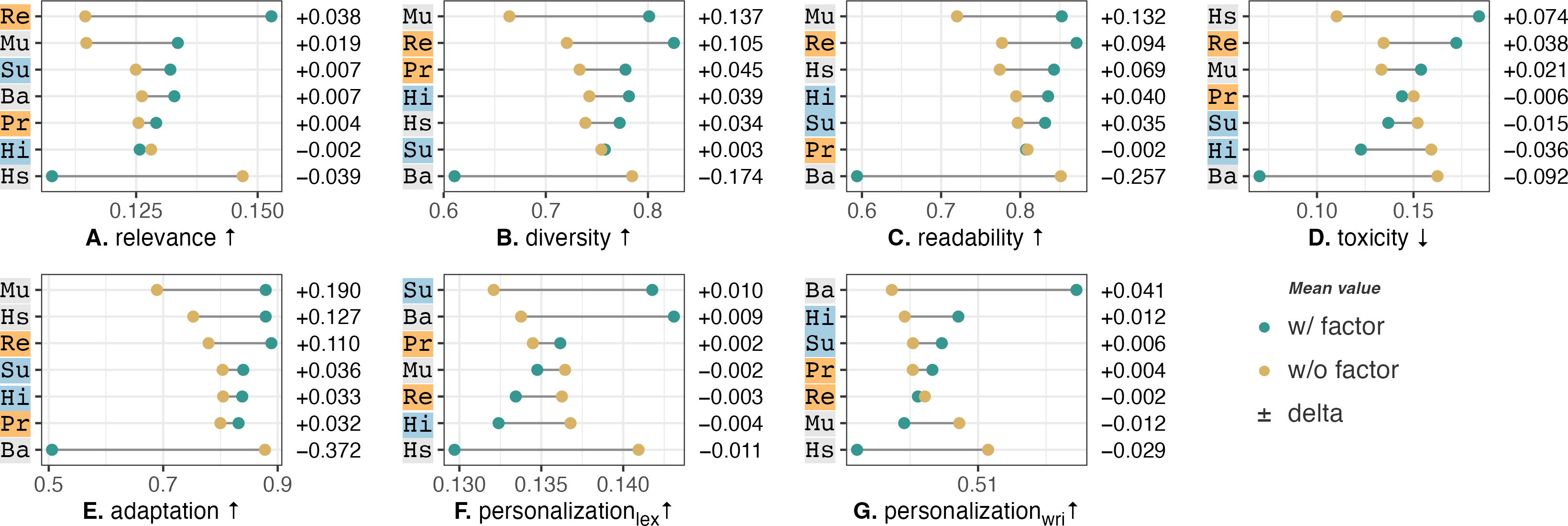
- Evaluates the specific contribution of adaptation (community/conversation) vs. personalization (user history) using a mixed-design human evaluation
- Demonstrates a stark divergence between automated metrics (ROUGE, toxicity scores) and human judgments of persuasiveness and adequacy
Architecture
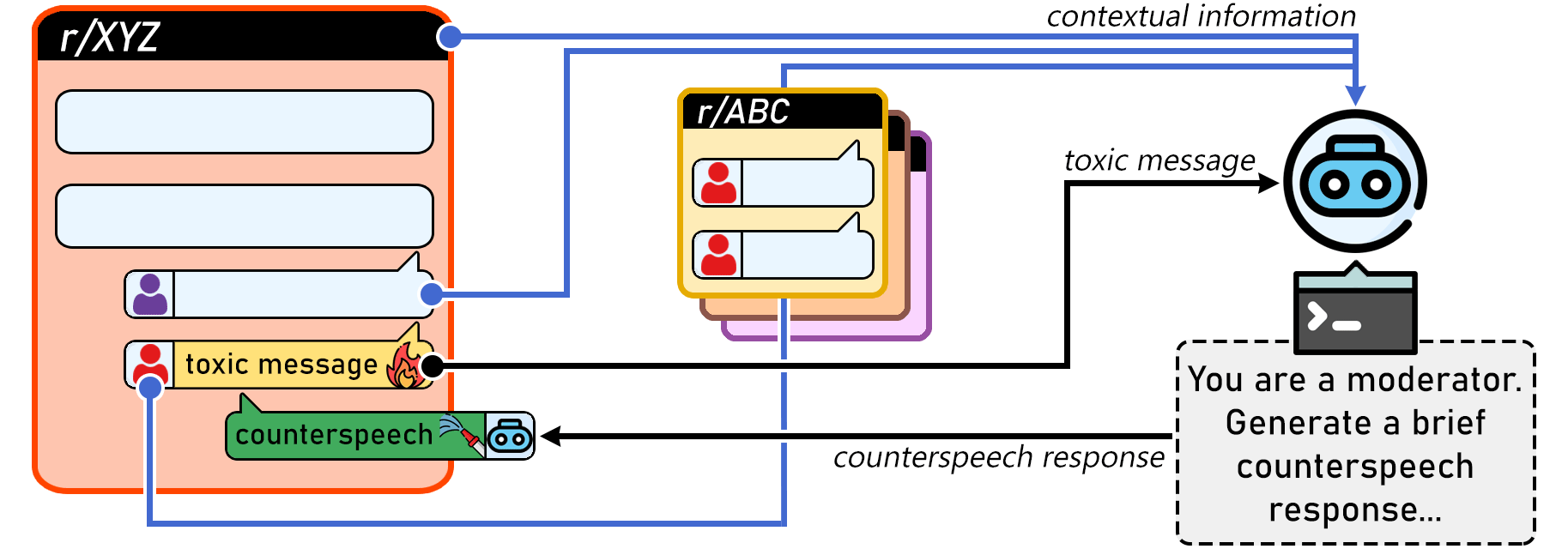
Conceptual workflow of the contextualized counterspeech generation system.
Evaluation Highlights
- Contextualized counterspeech outperforms the generic baseline in human-rated Adequacy (rank biserial correlation = 0.59) and Persuasiveness (rank biserial correlation = 0.38)
- Strategies combining adaptation (community style) and personalization (user summaries) achieved the highest human ratings across relevance and truthfulness
- Automated metrics failed to predict human preference: the configuration with the highest automated diversity/relevance scores often received lower human ratings
Breakthrough Assessment
7/10
Strong contribution in applying personalization to the specific domain of counterspeech, with a rigorous human evaluation exposing the failure of standard metrics. It doesn't propose a new architecture, but effectively applies existing LLMs to a novel, high-impact workflow.