📝 Paper Summary
Personalization of MLLMs
Retrieval-Augmented Generation (RAG)
RAP enables multimodal LLMs to recognize and chat about user-specific visual concepts (like a specific pet) by retrieving from an external database rather than fine-tuning the model for each new concept.
Core Problem
Existing Multimodal LLMs lack user-specific knowledge (e.g., the name of a user's pet) and require computationally expensive fine-tuning or extensive data collection to learn new personal concepts.
Why it matters:
- Personalized assistants must recognize specific user entities (pets, items) to be useful in daily life
- Fine-tuning for every new concept is impractical for on-device use and raises privacy concerns
- Current methods like MyVLM require multiple images and negative samples per concept, making data collection difficult for users
Concrete Example:
When a user asks 'What is <Lala> doing?' about their dog, a standard MLLM sees just 'a dog' and cannot identify it as 'Lala' or recall its habits. Previous personalization methods would need 5-10 labeled photos of Lala to train a new embedding, whereas RAP needs just one reference image.
Key Novelty
Retrieval-Augmented Personalization (RAP)
- Decouples concept storage from model weights: stores personal concepts (images + names) in an external key-value database rather than training new tokens
- Uses a 'Remember-Retrieve-Generate' workflow where a generic object detector finds potential concepts in an image, retrieves their specific identity from the database, and feeds this context to the MLLM
- Constructs a large-scale personalized training dataset using automated pipelines (Gemini 1.5) to teach MLLMs how to utilize retrieved context
Architecture
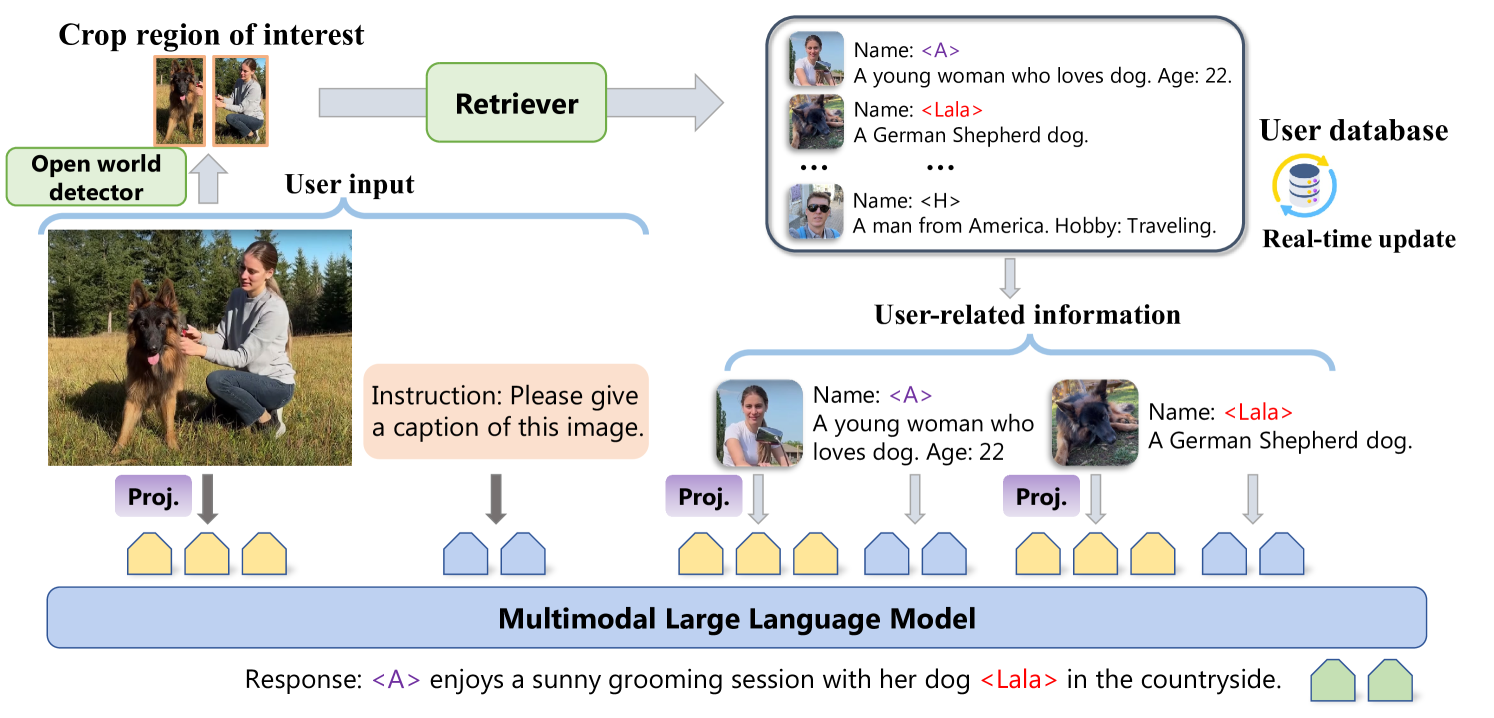
The RAP framework workflow: Remember, Retrieve, and Generate.
Evaluation Highlights
- Achieves 84.1 CIDEr score on personalized image captioning, outperforming MyVLM (76.8) and Yo'LLaVA (73.5)
- Requires only 1 reference image per concept compared to ~5-15 images needed by fine-tuning baselines
- Zero-shot generalization to new concepts: adding a concept to the database instantly enables the model to recognize it without any parameter updates
Breakthrough Assessment
8/10
Significantly lowers the barrier for MLLM personalization by removing the need for per-user fine-tuning. The dataset construction pipeline is a valuable contribution for the field.