📝 Paper Summary
Memory internalization
Conversational personalization
PLUM replaces external retrieval systems by injecting conversation history directly into LLM parameters via Low-Rank Adaptation (LoRA) finetuning on synthetic question-answer pairs.
Core Problem
Retrieval Augmented Generation (RAG) for personalization requires managing external storage and context window limits, while existing finetuning methods struggle to update models with sequential conversation history efficiently.
Why it matters:
- RAG-based methods deteriorate in performance as context windows grow and require maintaining complex external databases
- Personalization requires remembering holistic conversation history, not just static user facts or style preferences
- Prior work lacks a streamlined approach for parametric knowledge injection that respects the sequential nature of user interactions
Concrete Example:
If a user previously discussed 'travel plans to Japan', a standard model might forget this in a new session. RAG would retrieve the raw logs. PLUM instead generates questions like 'Did we discuss Japan?' (Yes) and finetunes the model to answer correctly without accessing the old logs.
Key Novelty
Pipeline for Learning User Conversations (PLUM)
- Augments conversation data by generating synthetic positive (factual) and negative (out-of-scope) question-answer pairs using a teacher LLM
- Injects these memories into the model using LoRA adapters trained with a custom weighted cross-entropy loss that emphasizes question and answer tokens over instructions
Architecture
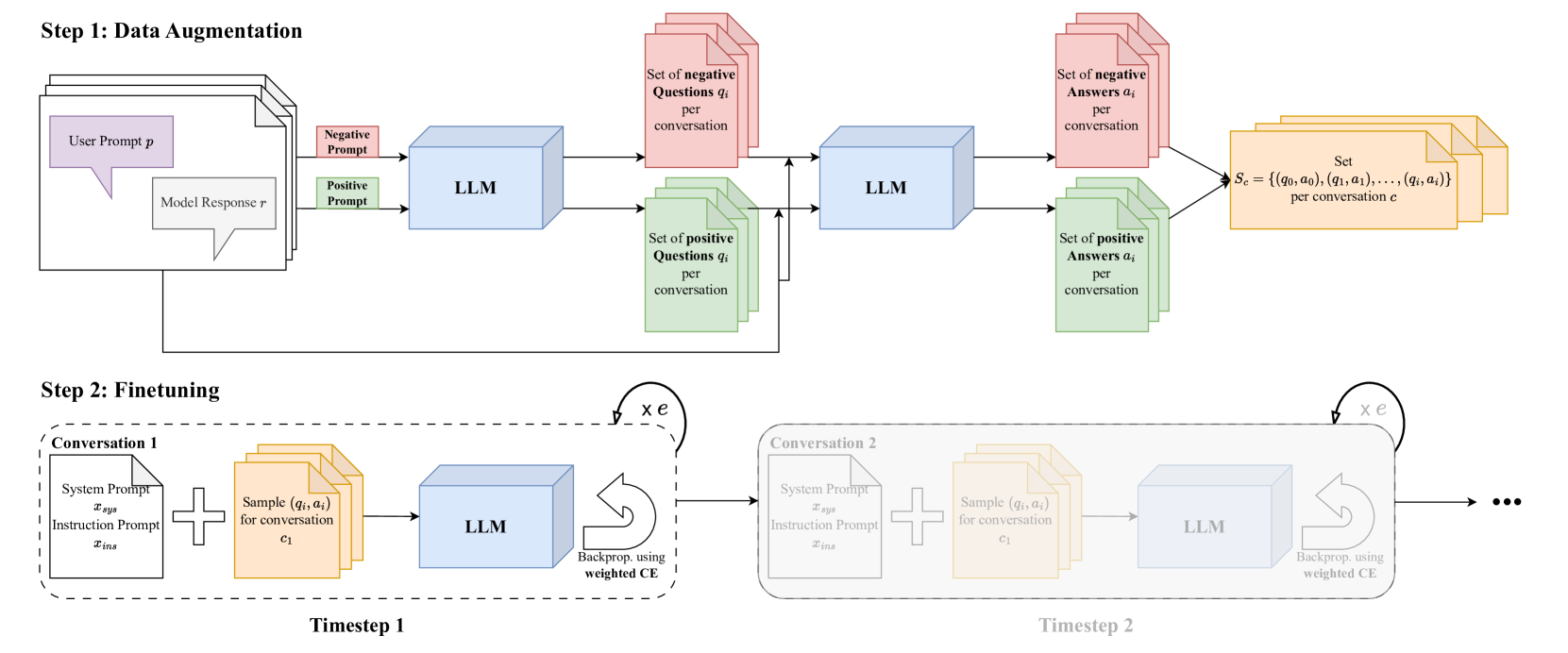
The PLUM pipeline: extracting Q/A pairs from a conversation and using them to finetune a LoRA adapter
Evaluation Highlights
- Achieves 81.5% accuracy on memorizing 100 conversations, comparable to the 83.5% accuracy of a standard BM25 RAG baseline
- Maintains general capabilities with negligible degradation on MMLU (65.65% base vs. 64.93% PLUM 5-shot)
- Demonstrates that parametric memory can perform competitively with non-parametric retrieval methods in controlled settings
Breakthrough Assessment
6/10
A strong proof-of-concept for parametric memory as an alternative to RAG. While performance is slightly below RAG, it eliminates external storage requirements, marking a meaningful step toward internalized LLM memory.