📝 Paper Summary
LLM Alignment
Controlled Decoding
Personalization
VAS aligns LLMs by guiding decoding using a separately trained value function to weight next-token probabilities, achieving high reward without modifying the base model's weights.
Core Problem
Existing alignment methods force a trade-off: Best-of-N search offers high performance but is computationally expensive, while PPO is efficient at inference but suffers from unstable bi-level optimization and lower performance.
Why it matters:
- Standard RLHF methods (like PPO) often degrade model capabilities due to optimization instability and 'alignment tax'
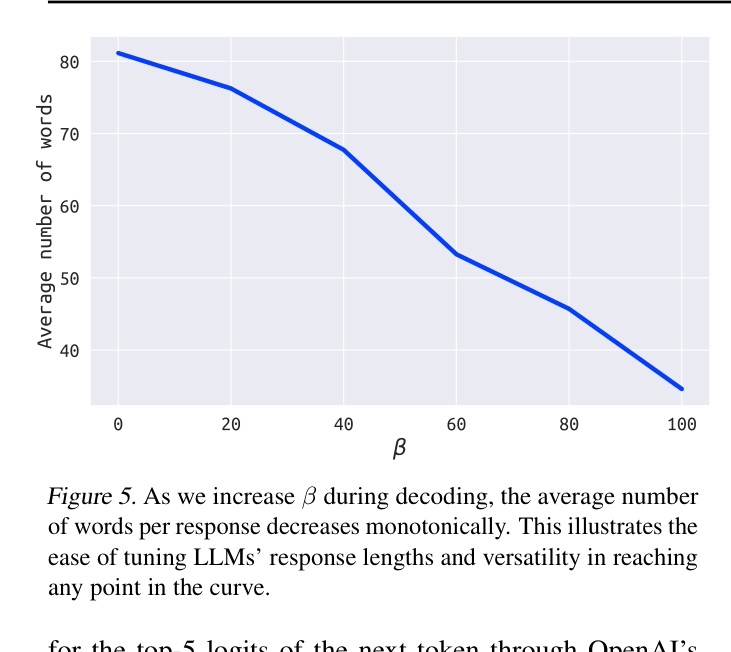
- Real-world deployment requires fine-grained control and personalization (e.g., adjusting verbosity on the fly), which is impossible with static fine-tuned policies
- Users increasingly rely on black-box API models (like GPT-4) where weights are inaccessible, making traditional fine-tuning impossible
Concrete Example:
When aligning a model for conciseness using PPO, the model might learn to be short but lose information (reward hacking). Alternatively, using Best-of-128 generates 128 full responses to find a good one, which is too slow for real-time chat.
Key Novelty
Value Augmented Sampling (VAS)
- Instead of retraining the LLM policy, train a separate Value estimator that predicts the expected future reward from the current state
- At inference time, use the frozen base LLM to propose tokens, but re-weight their probabilities using the Value estimator to steer towards high-reward outcomes
- Bypass the unstable actor-critic loop entirely by using the optimal closed-form solution for KL-constrained reinforcement learning
Architecture
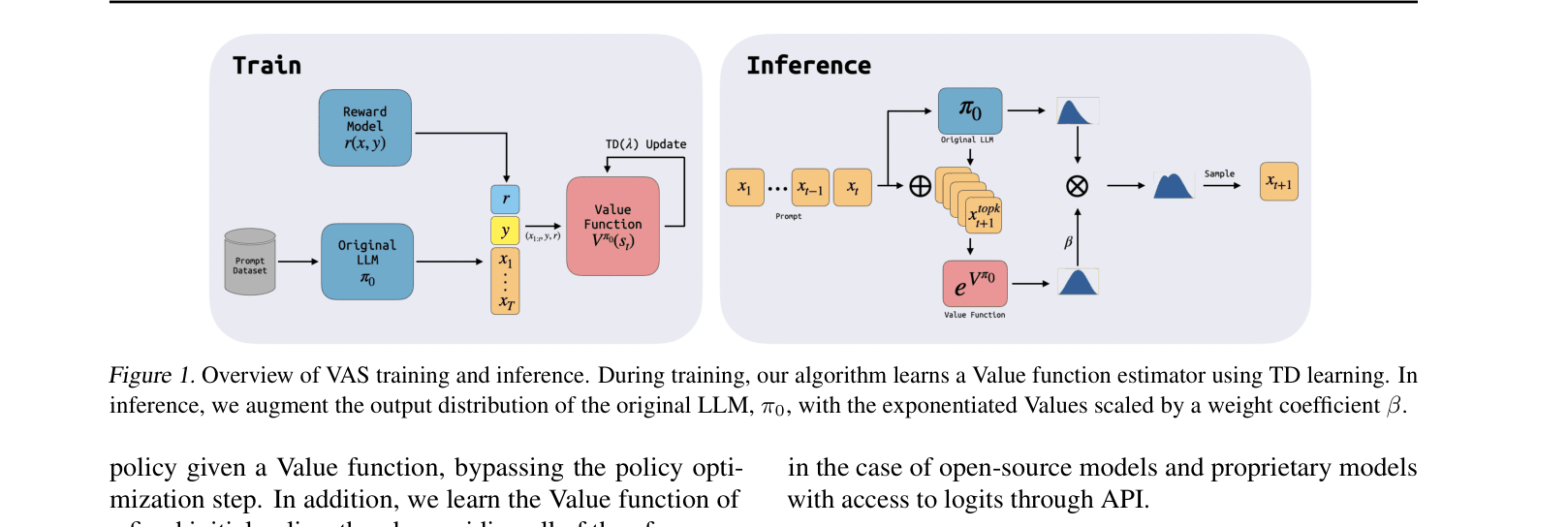
Overview of VAS training and inference workflow.
Evaluation Highlights
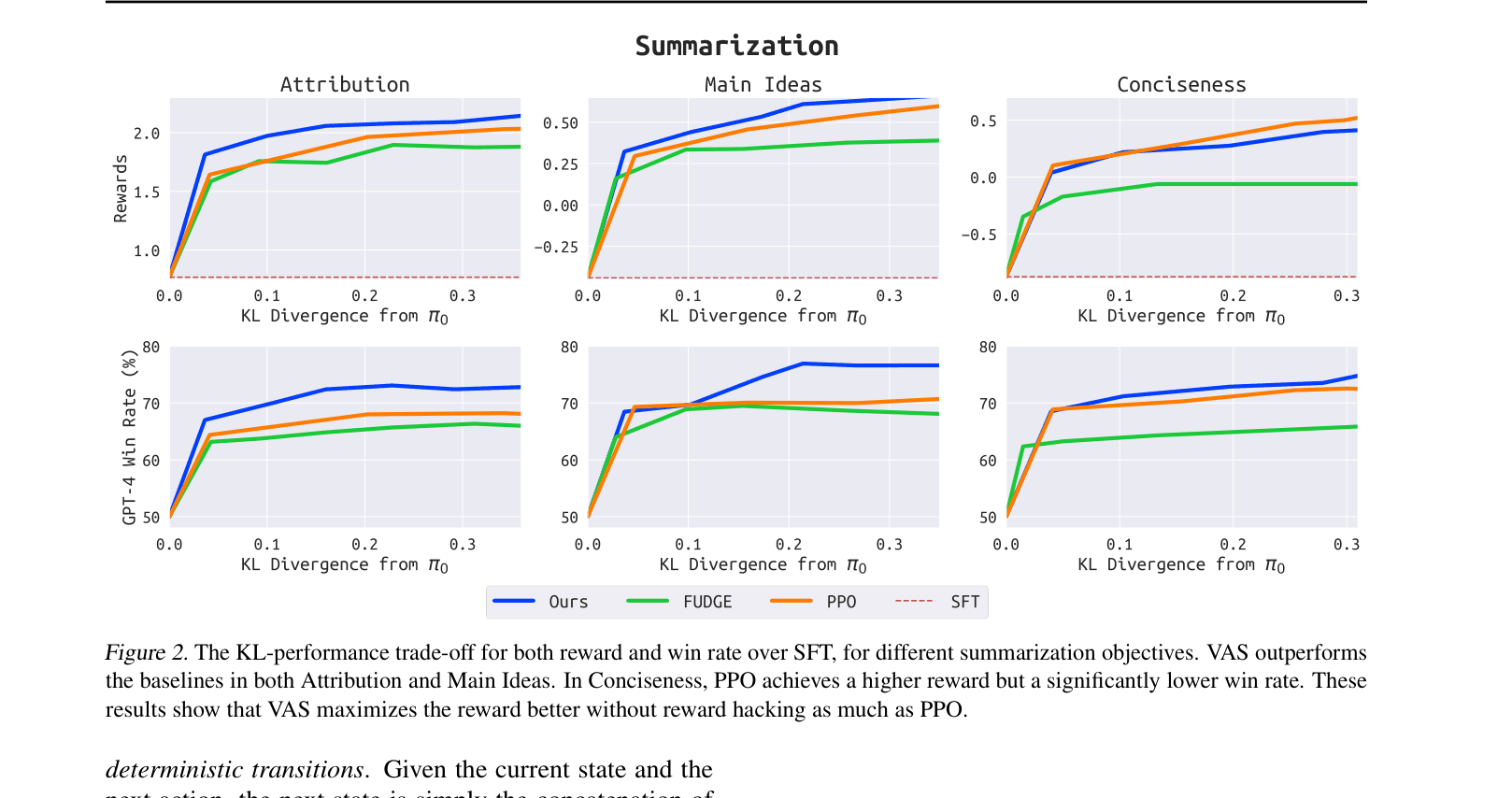
- Outperforms PPO and DPO on summarization (Seahorse dataset) and chat dialogue (Anthropic HH), achieving a 55% win rate against DPO on dialogue
- Matches the performance of Best-of-128 search while being at least 6x more computationally efficient in terms of FLOPS
- Enables teaching tool-use to a frozen GPT-3.5 (black-box) model, improving success rate from 62.8% to 84.5% in a one-shot setting
Breakthrough Assessment
8/10
Offers a mathematically grounded, compute-efficient alternative to PPO that enables personalization and black-box adaptation. Solves the stability issues of RLHF while retaining the flexibility of search-based methods.