📝 Paper Summary
User-profile based personalization
Alignment via Preference Tuning
The authors improve LLM personalization by using abductive reasoning to infer user personas from preference datasets (explaining why specific users might prefer rejected responses) and training models to tailor outputs to these personas.
Core Problem
Standard preference tuning assumes 'chosen' responses are universally better, discarding 'rejected' responses and failing to model why different users might legitimately prefer distinct outputs.
Why it matters:
- Minority user needs (e.g., users wanting logistics over recipes) are ignored by models trained on aggregate preferences
- Rejected responses in datasets often contain valid content for specific subgroups, but this signal is currently wasted
- Current personalization lacks training data where personas are explicitly paired with preferred responses
Concrete Example:
In a prompt about bringing brownies to a sale, most users prefer a recipe (Chosen). However, a 'practical' user might prefer the rejected response discussing packaging logistics. Standard DPO suppresses the logistics response entirely, failing to serve the practical user.
Key Novelty
Persona Inference (PI) and Persona Tailoring (PT)
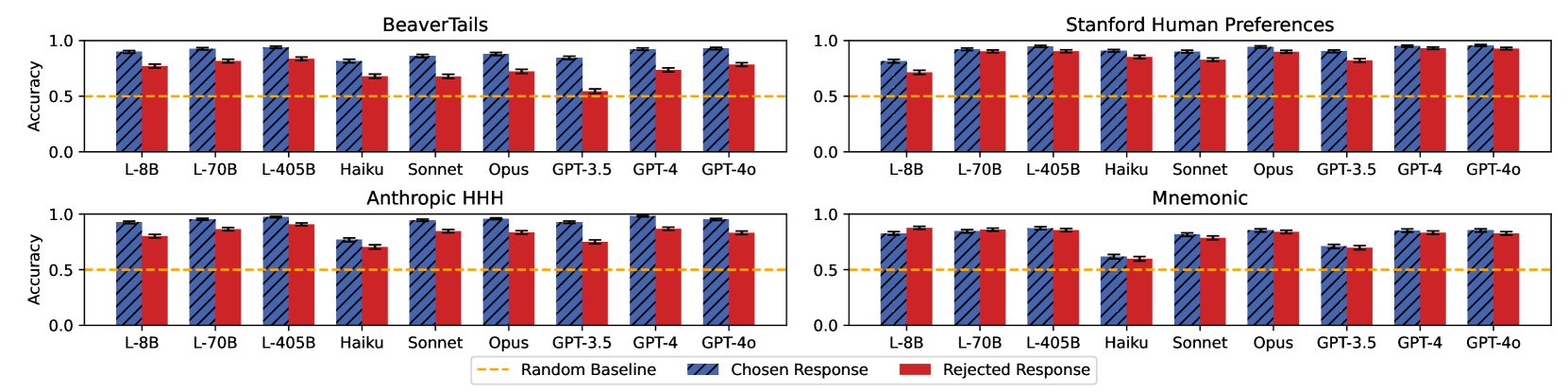
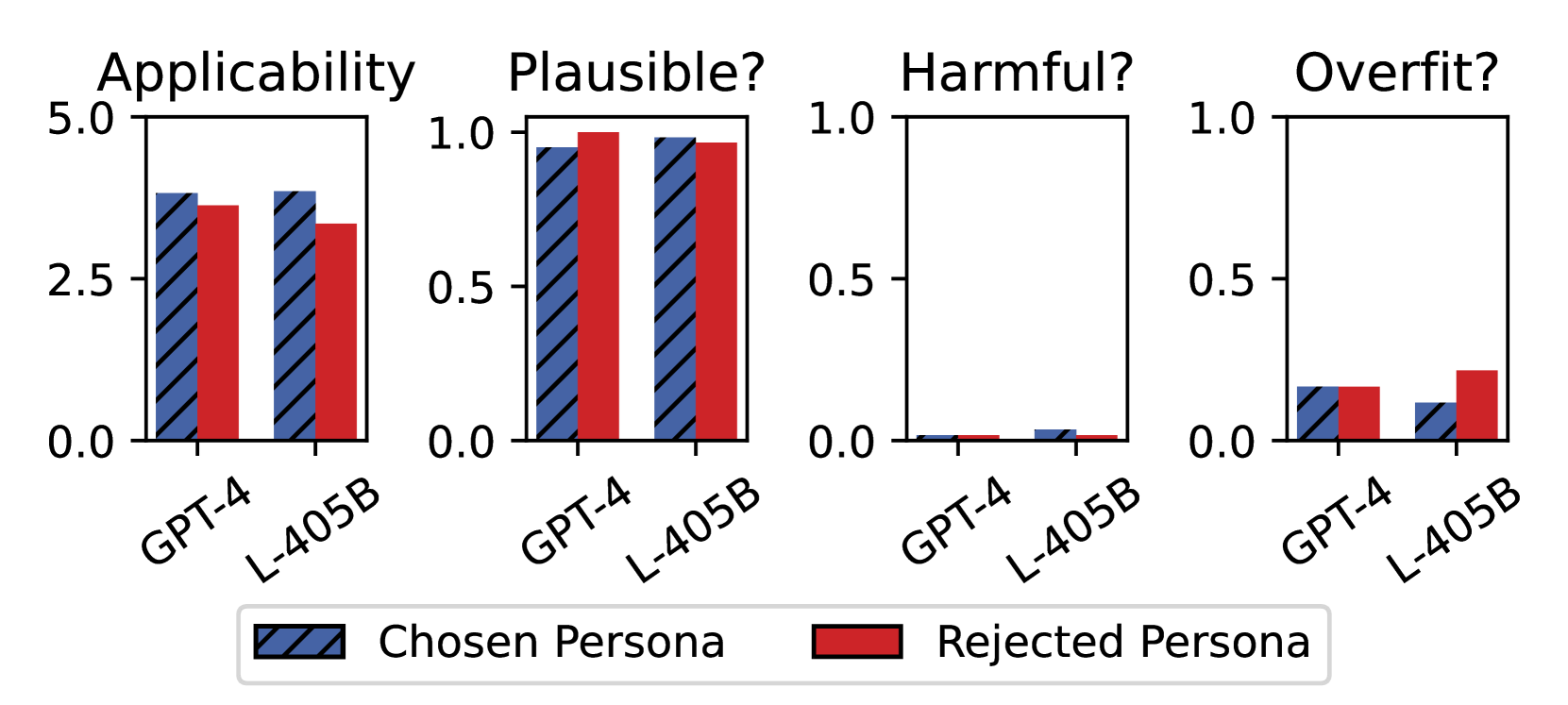
- Apply abductive reasoning to existing preference pairs to infer a 'persona' (user description) that explains why a user would prefer the chosen response and a different persona for the rejected response
- Augment preference datasets with these inferred personas and train models (via DPO or SFT) to condition their generation on the provided persona, enabling the model to serve diverse needs
Architecture
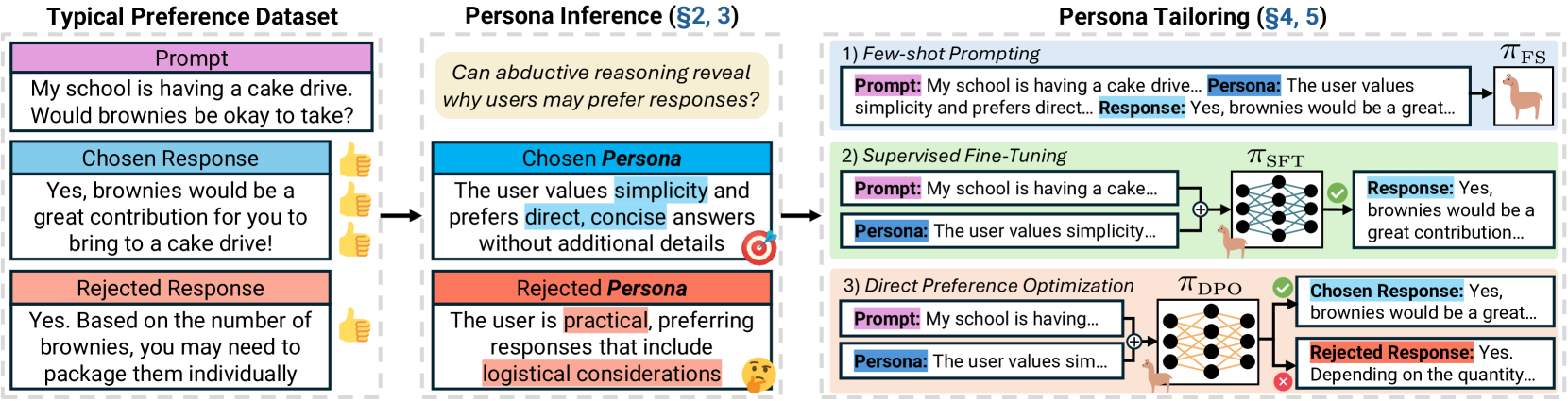
The two-step process: Persona Inference (PI) and Persona Tailoring (PT).
Evaluation Highlights
- Llama-3.1-405B achieves 91% accuracy in Persona Inference (PI), correctly identifying which persona matches a preferred response as judged by GPT-4o
- PT-DPO (Persona Tailoring via DPO) yields a 66% average improvement in personalization scores on 'rejected' response personas compared to standard DPO
- PT-DPO generalizes to real human interactions, effectively personalizing to 144 diverse personas written by 8 actual users
Breakthrough Assessment
7/10
Clever use of abductive reasoning to extract value from 'rejected' data. Demonstrates that alignment data contains hidden personalization signals. Strong empirical gains on specific user needs.