📝 Paper Summary
RAG-based personalization
User modeling
Persona-DB improves LLM personalization by transforming raw user logs into hierarchical abstract personas and retrieving context from similar users to handle sparse data and reduce context window usage.
Core Problem
Retrieval-augmented personalization typically relies on raw, noisy user logs, which are inefficient for the context window and fail for users with sparse history (lurkers).
Why it matters:
- Standard retrieval requires large amounts of scattered log data to infer simple user preferences, inflating inference costs
- Users with minimal history (cold-start) receive poor personalization because they lack sufficient self-data to retrieve
- Existing methods do not leverage the 'collaborative' knowledge that users with similar mindsets tend to make similar decisions
Concrete Example:
A 'lurker' user who cares about the environment but has zero posts about renewable energy asks about a solar initiative. A standard retriever finds nothing relevant in their empty history. Persona-DB finds similar users who are also environmentalists, retrieves their positive opinions on solar energy, and correctly infers the lurker would support the initiative.
Key Novelty
Persona-DB (Hierarchical + Collaborative RAG)
- Hierarchical Refinement: Uses an LLM to pre-process raw logs into 'Distilled' (facts) and 'Induced' (abstract traits) personas, creating denser features that are more retrieval-efficient than raw logs
- Collaborative Refinement (JOIN): Implements a retrieval mechanism analogous to a SQL JOIN, where the system identifies similar users via persona embeddings and retrieves relevant context from *their* databases to augment the current user's prompt
Architecture
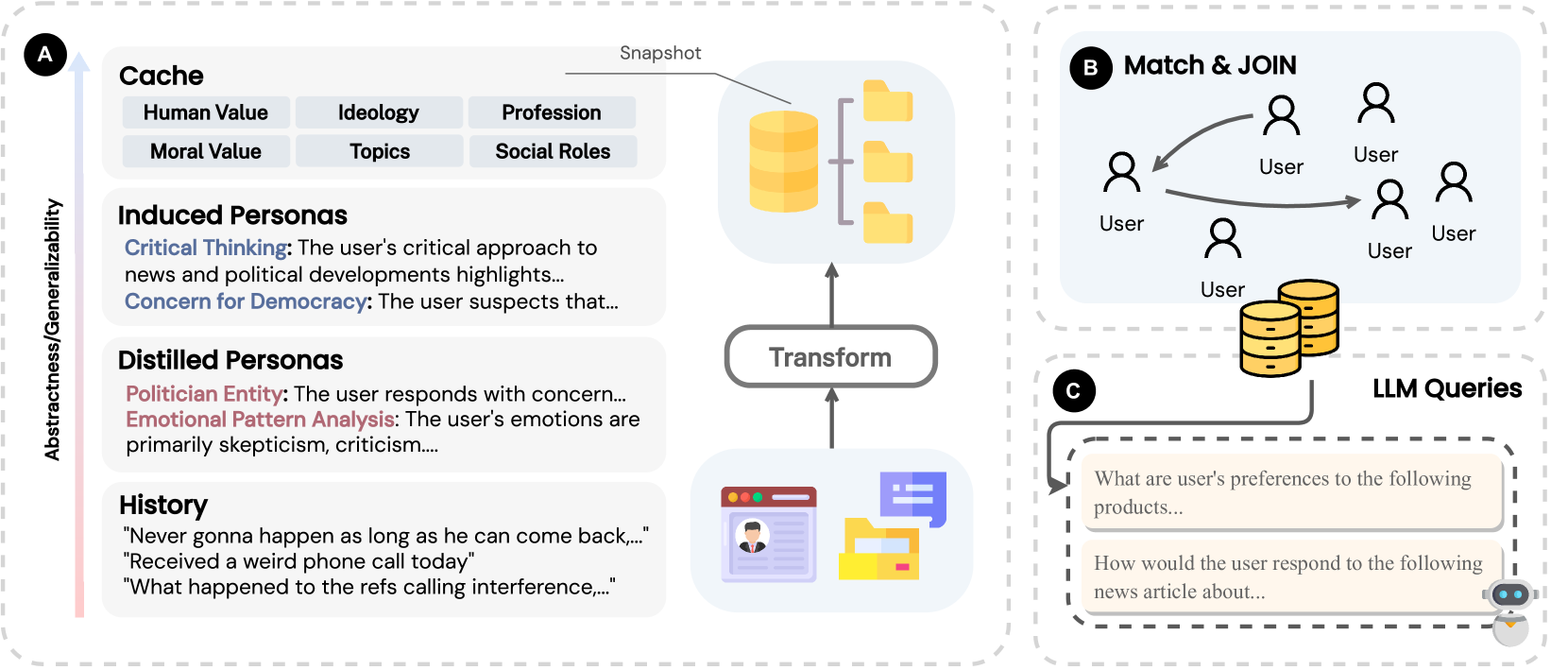
Figure 1 shows the hierarchical database construction (History -> Distilled -> Induced). Figure 2 shows the JOIN retrieval process.
Evaluation Highlights
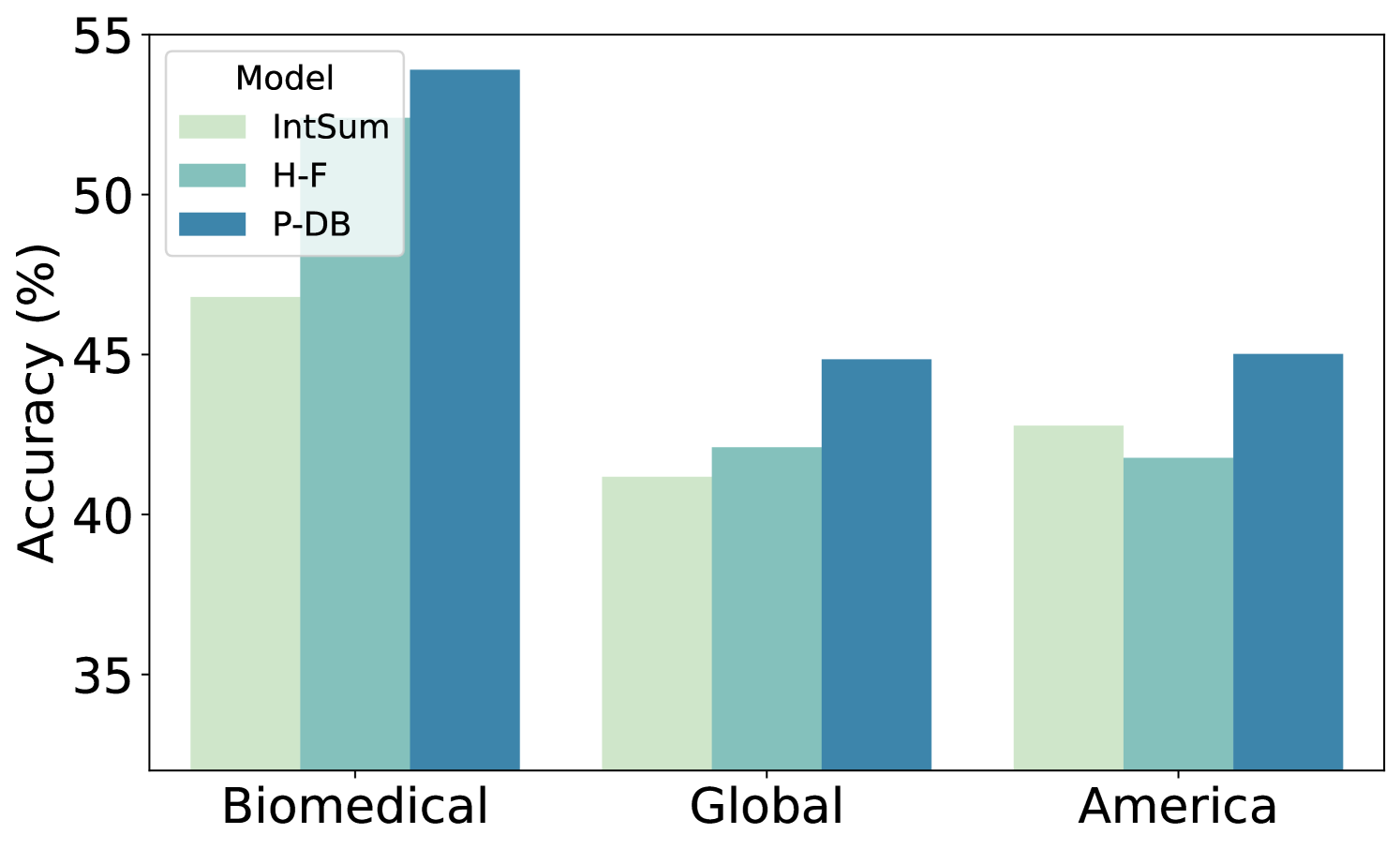
- +11% Pearson correlation improvement over baselines for 'Lurkers' (users with sparse history) on the RFPN benchmark
- Achieves superior accuracy compared to standard retrieval baselines even when the retrieval size is reduced by 10x (high context efficiency)
- Consistently outperforms baseline methods (H-Retrieval, H-Recency) across Response Forecasting and OpinionQA tasks
Breakthrough Assessment
7/10
Strong engineering contribution to RAG-based personalization. Effectively addresses the critical cold-start problem using collaborative filtering concepts within a RAG framework, though the underlying models are standard APIs.