📝 Paper Summary
Personalized Text-to-Image Generation
Identity Preservation
Infinite-ID decouples identity and text processing in diffusion models by using separate training paths and a mixed attention mechanism to merge them during inference, improving both identity fidelity and semantic consistency.
Core Problem
Existing methods entangle reference image identity features with text prompt features, forcing a trade-off where improving identity fidelity degrades prompt adherence (semantic consistency) and vice versa.
Why it matters:
- Methods like PhotoMaker compress image features into text space, weakening identity details
- Methods like IP-Adapter inject strong image features directly into the U-Net, often overpowering text prompts and ignoring semantic instructions
- Current tuning-free personalization struggles to generate high-fidelity portraits in complex, novel scenes described by text
Concrete Example:
When prompted with 'a man in a superman costume' using an image of Elon Musk, prior methods might produce a generic Superman (losing Elon's face) or a photo of Elon in a suit (ignoring the 'superman costume' text). Infinite-ID aims to produce Elon's exact face in the correct costume.
Key Novelty
ID-Semantics Decoupling Paradigm
- Trains the model to recognize identity using only image inputs (ignoring text) via a specialized image cross-attention module, preventing text from interfering with identity learning
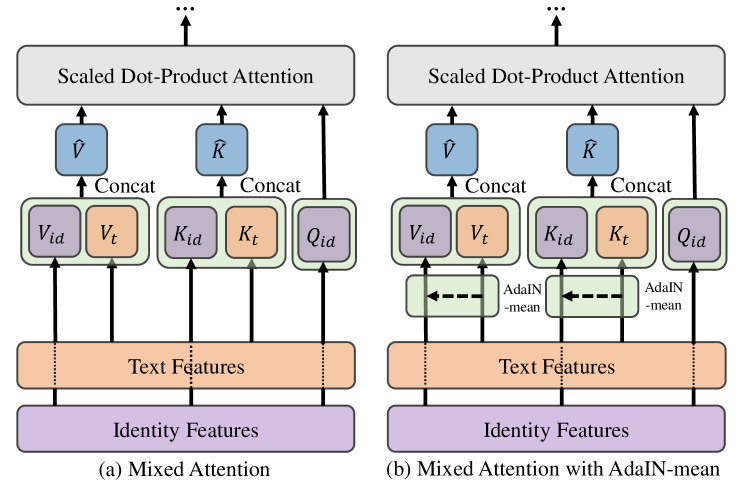
- Reintroduces text during inference using a separate 'Mixed Attention' mechanism that fuses features from the text-driven self-attention and identity-driven cross-attention layers
- Uses an AdaIN-mean operation to normalize feature statistics, allowing precise style control without retraining
Architecture
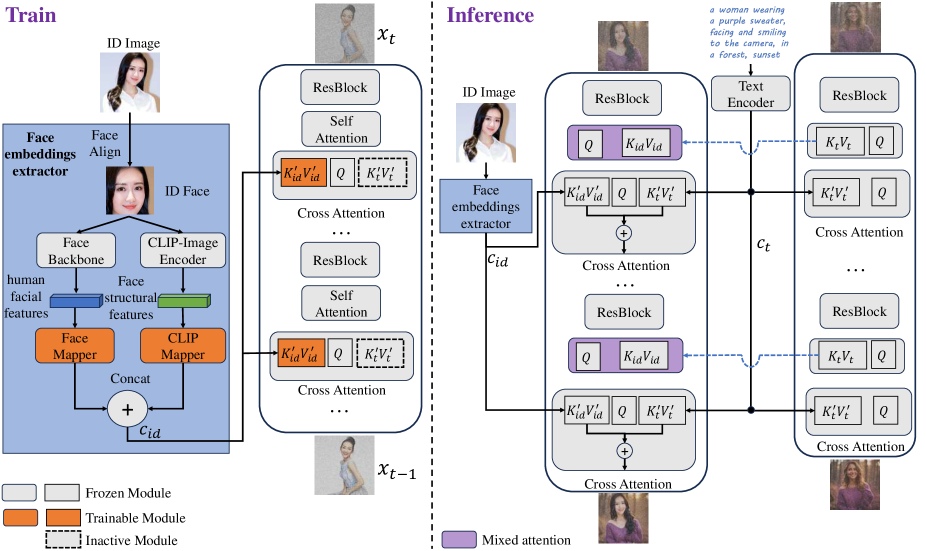
The training pipeline of Infinite-ID.
Evaluation Highlights
- Achieves highest ID fidelity (0.83 DINO score) compared to PhotoMaker (0.76) and IP-Adapter (0.78) on evaluation benchmarks
- Maintains strong semantic consistency (0.28 CLIP-T score), outperforming IP-Adapter (0.26) while matching the text-focused PhotoMaker
- Demonstrates superior qualitative performance in style transfer tasks compared to StyleAligned and InstantStyle
Breakthrough Assessment
7/10
Strong methodological contribution in decoupling ID/text streams to solve the fidelity-consistency trade-off. Results show clear quantitative improvement over popular baselines like IP-Adapter.