📝 Paper Summary
Conversational personalization
RAG-based personalization
HYDRA personalizes black-box LLMs by training a decomposed reranker and adapter—splitting shared knowledge from user-specific preferences—to select optimal history and align generated outputs without accessing model weights.
Core Problem
Black-box LLMs (like GPT-3.5) cannot be fine-tuned directly for personalization, while prompt-based RAG methods struggle to capture shared group knowledge and optimal history simultaneously.
Why it matters:
- Direct fine-tuning or RLHF requires white-box access, which is impossible for powerful commercial models like GPT-4
- Standard RAG handles users independently, failing to learn global patterns shared across the user base
- Including entire user histories in prompts is costly and hits context limits, while random sampling misses crucial preference signals
Concrete Example:
When a user asks for a movie recommendation, a standard RAG system might retrieve 'relevant' but outdated reviews that don't reflect their current taste shift. HYDRA's personalized reranker identifies the 'useful' history, and its adapter rejects generic LLM outputs in favor of those matching the user's specific stylistic or content preferences.
Key Novelty
Hydra-like Model Factorization for Reranking and Adapting
- Decomposes the personalization module (both reranker and adapter) into a shared base model and multiple user-specific heads, resembling a Hydra
- The shared base captures global knowledge applicable to all users, while lightweight user-specific heads capture individual preference patterns
- Applies this factorization to two stages: prioritizing retrieved history (reranking) and selecting the best black-box generation (adapting/rejection sampling)
Architecture
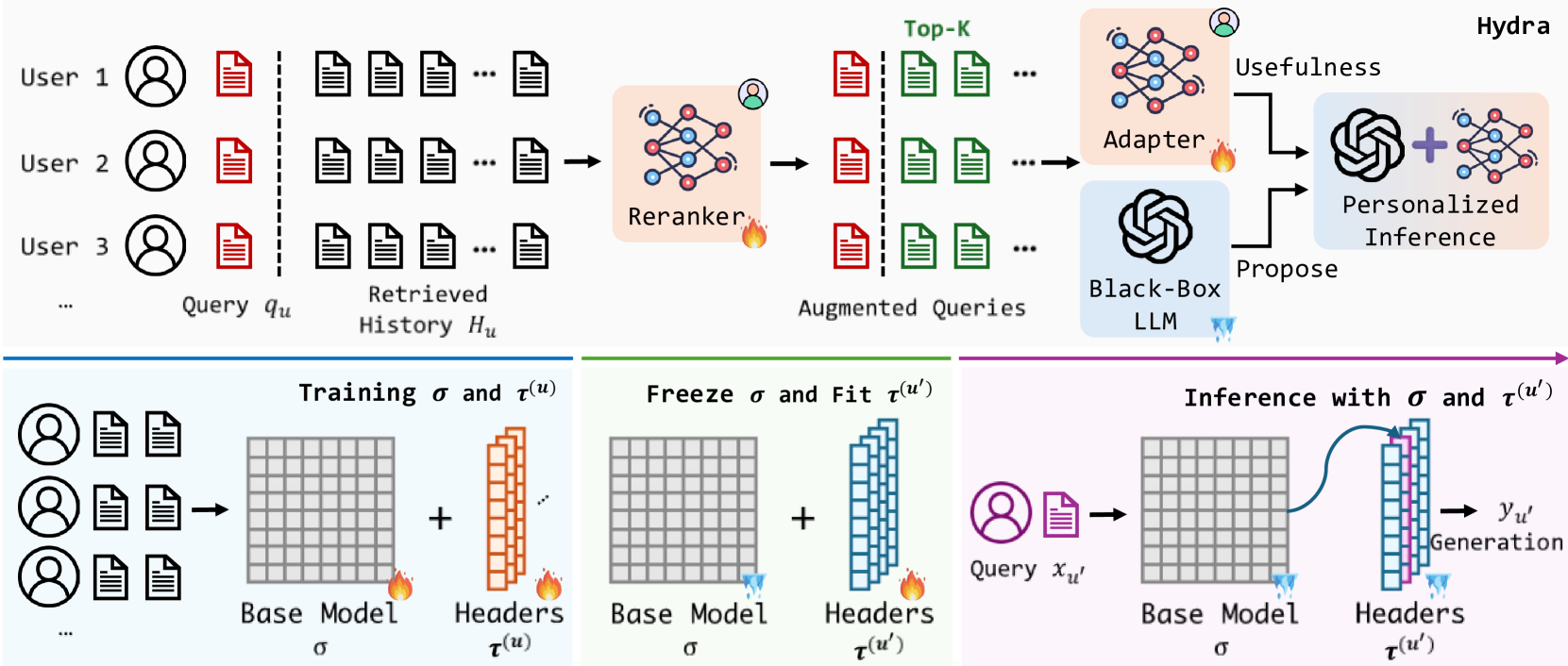
The HYDRA framework workflow, illustrating the retrieve-then-rerank process and the adapter-based generation selection.
Evaluation Highlights
- +9.01% average relative improvement over state-of-the-art prompt-based methods across five diverse tasks in the LaMP benchmark
- +4.8% average improvement over the best-performing baselines across all five tasks (absolute gains vary by task)
- Outperforms retrieval-augmented baselines like standard RAG and profile-augmented generation on text classification and generation tasks
Breakthrough Assessment
7/10
Novel architectural approach to 'personalizing' black-box models via external modules. Strong empirical results on LaMP, though it relies on training auxiliary models rather than the LLM itself.