📝 Paper Summary
Conversational personalization
PReF personalizes language models by decomposing rewards into shared base functions and user-specific weights, enabling rapid adaptation to new users via uncertainty-based active learning.
Core Problem
Standard RLHF learns a single universal preference model that ignores individual variations, while training separate models for each user requires prohibitive amounts of data and compute.
Why it matters:
- User preferences vary drastically (e.g., professional assistant vs. virtual friend), making 'average' alignment suboptimal for everyone
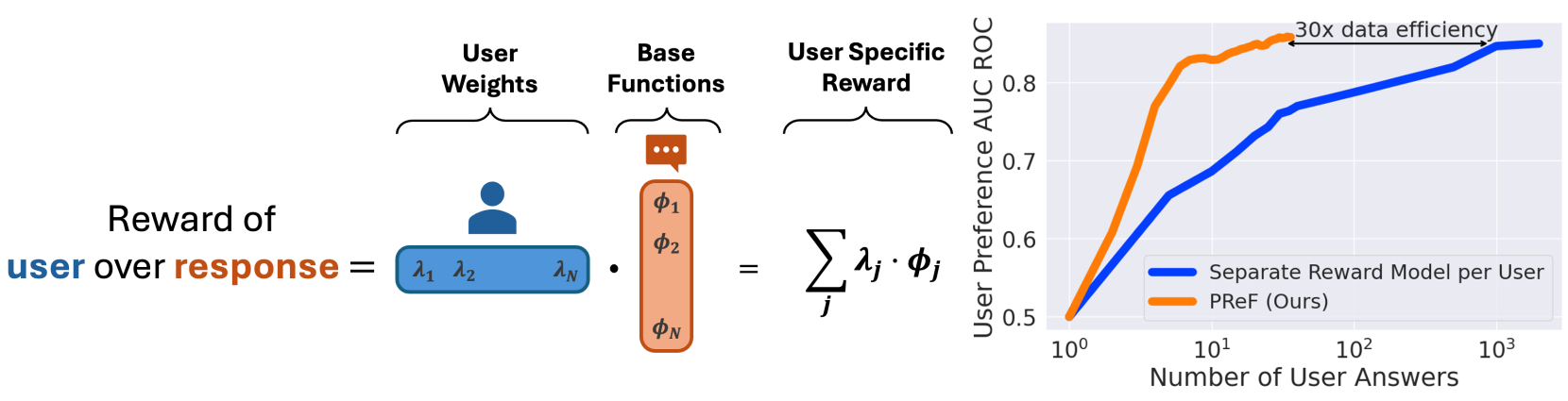
- Existing personalization methods require thousands of user-specific data points, which is infeasible for scaling to millions of users
- Naively maintaining separate LLMs for every user creates unsustainable computational and storage costs
Concrete Example:
One user might prefer concise, professional answers for work, while another wants empathetic, verbose responses for companionship. A standard RLHF model averages these into a generic tone that satisfies neither. PReF adapts to the specific user using just ~10 pairwise comparisons.
Key Novelty
Personalization via Reward Factorization (PReF)
- Hypothesizes that user rewards lie on a low-dimensional manifold, representable as a linear combination of learned 'base' reward functions
- Initializes these base functions via Singular Value Decomposition (SVD) of preference matrices to handle data sparsity and non-convex optimization
- Uses active learning (logistic bandits) to efficiently infer a new user's specific combination weights by selecting query pairs that maximize uncertainty
Architecture
Conceptual flow of the PReF framework: Offline Learning -> Online Adaptation -> Inference.
Evaluation Highlights
- Achieves a 67% win rate against default GPT-4o responses in human evaluations after alignment
- Surpasses the performance of a standard (non-personalized) reward model using only 5 feedback samples from a new user (synthetic experiments)
- Infers robust user-specific reward coefficients using only 10-20 active learning questions
Breakthrough Assessment
7/10
Clever application of matrix factorization and active learning to RLHF. Significantly reduces the data barrier for personalization, though reliance on inference-time alignment (vs training) limits scope.