📝 Paper Summary
Personalization (P13N)
Reward Modeling
Proposes two frameworks for RLHF with heterogeneous users: learning personalized reward models via shared representations, and aggregating probabilistic preferences via an incentive-compatible mechanism that ensures truthful reporting.
Core Problem
Standard RLHF assumes human preferences are homogeneous and honest, but real user populations have diverse, conflicting preferences and may strategically misreport feedback to manipulate the model.
Why it matters:
- Assuming a single reward model for diverse populations leads to misalignment and poor performance for minority groups or specific user contexts.
- Individual users often provide insufficient data to train standalone reward models, creating a 'cold start' problem for personalization.
- Strategic users (e.g., in online rating systems) may provide extreme feedback to disproportionately influence the aggregate model, distorting the AI's alignment.
Concrete Example:
In an online rating system, a user might rate a decent response as 'terrible' (extreme feedback) not because they hate it, but to drag the overall average closer to their personal preference, manipulating the aggregated reward model.
Key Novelty
Principled Personalization and Strategic-Aware Aggregation
- Personalization: Uses representation learning to find a shared structure across all users, then learns individual 'heads' (parameters) for each user or cluster, trading off bias and variance.
- Strategic Aggregation: Models feedback collection as a mechanism design problem. By using 'probabilistic opinion' feedback and specific cost mechanisms, it makes truthful reporting the optimal strategy for users.
Architecture
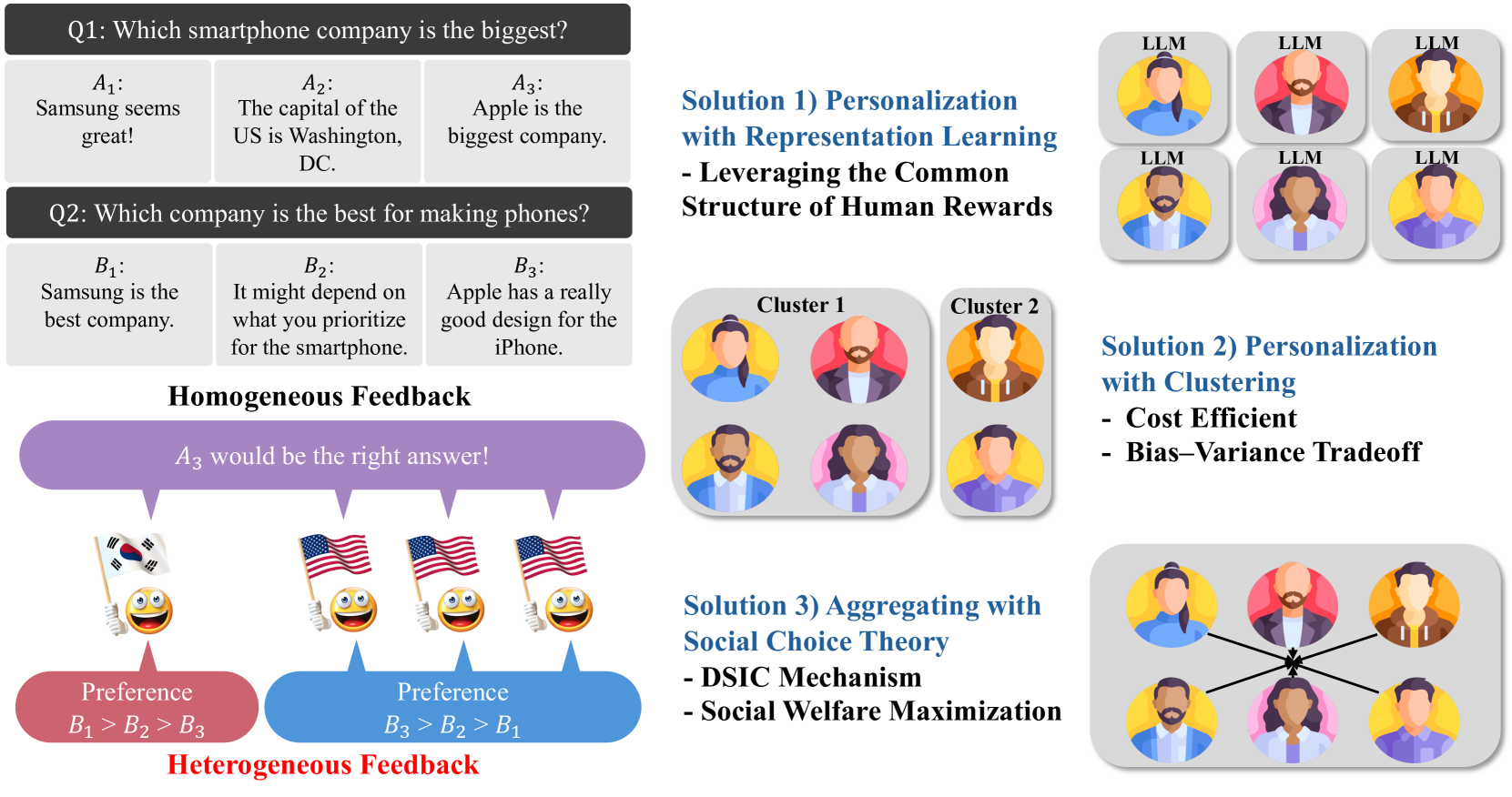
Conceptual illustration of the challenge of heterogeneous user preferences in RLHF (inferred from text description)
Evaluation Highlights
- Establishes sample complexity guarantees for personalized reward learning using shared representations across heterogeneous users.
- Proves that the proposed probabilistic opinion aggregation rule maximizes social welfare functions.
- Demonstrates that the proposed feedback mechanism is Dominant Strategic Incentive-Compatible (DSIC), ensuring truthful preference reporting.
Breakthrough Assessment
7/10
Significant theoretical contribution introducing mechanism design and social choice theory to RLHF. Addresses the critical but overlooked problems of preference heterogeneity and strategic manipulation.