📝 Paper Summary
Conversational personalization
Preference Optimization
FSPO treats personalization as a meta-learning problem where models learn to infer a user's reward function from few-shot synthetic preference data, enabling transfer to real users.
Core Problem
Standard preference optimization (like RLHF) aggregates feedback into a single reward function, marginalizing minority viewpoints and failing to adapt to individual user preferences.
Why it matters:
- Aggregating preferences neglects minority viewpoints and embeds systematic biases by optimizing for the 'average' user.
- Collecting personalized preference data from real humans at scale is difficult, expensive, and time-consuming.
- Existing personalization methods often struggle with open-ended generation or require expensive test-time interventions.
Concrete Example:
In a movie review task, one user might prefer concise, negative reviews while another prefers verbose, positive ones. A standard RLHF model trained on aggregated data would likely regress to a generic mean, failing to satisfy either user's specific stylistic constraints.
Key Novelty
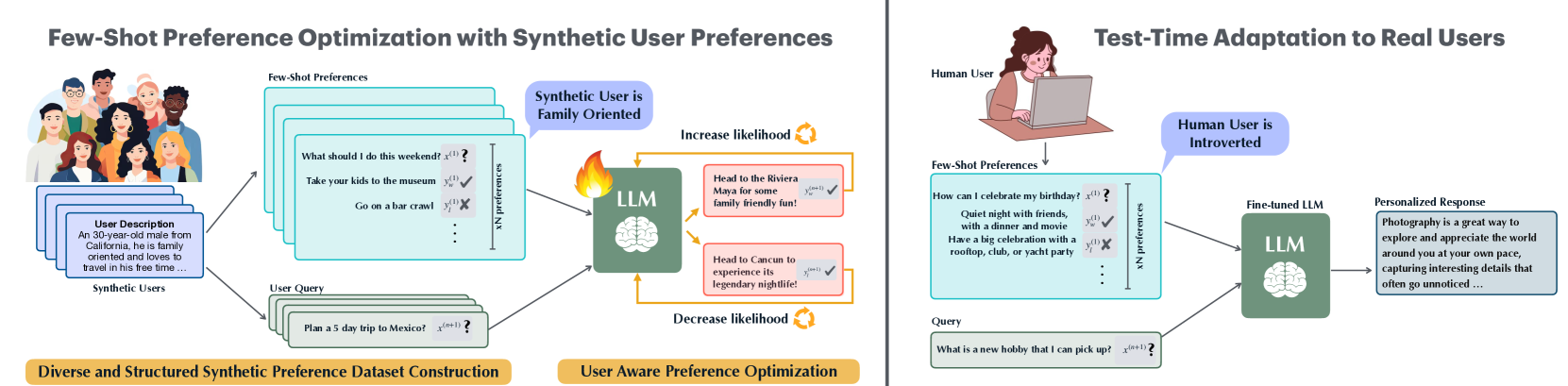
Few-Shot Preference Optimization (FSPO)
- Reframes reward modeling as a meta-learning problem where the model learns to identify a specific user's reward function from a short sequence of their past preference choices.
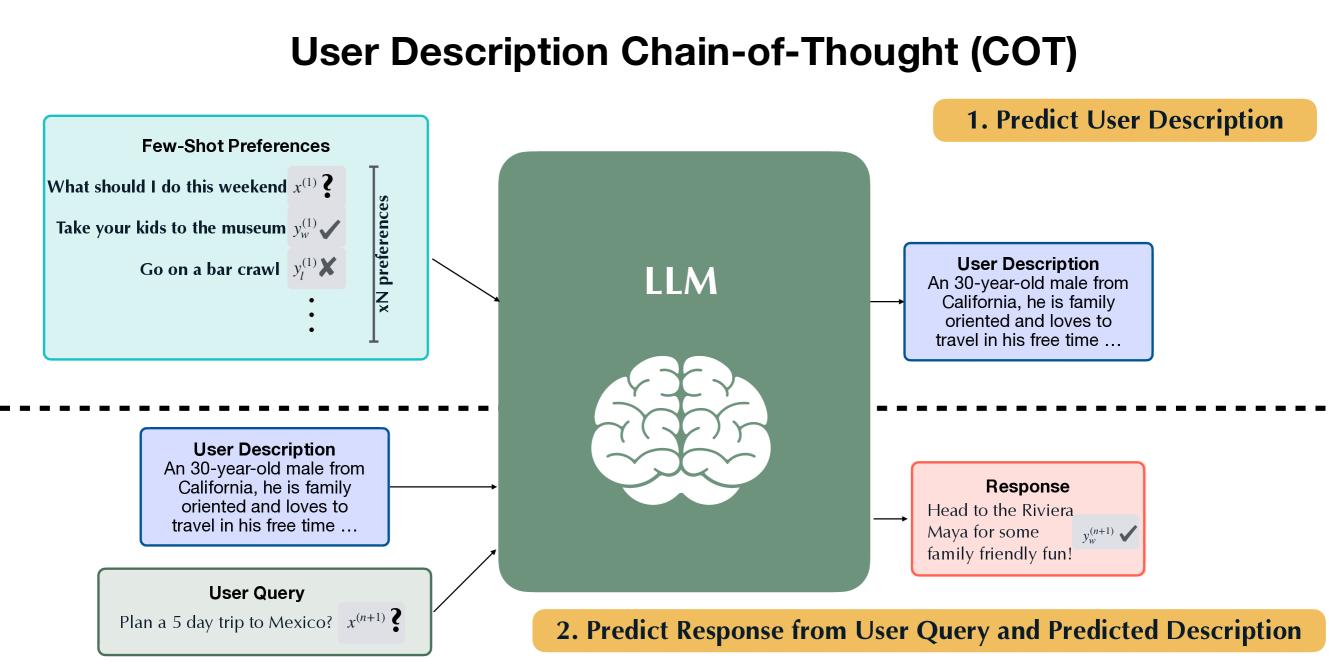
- Uses 'User Description Chain-of-Thought' (COT) to explicitly generate a natural language summary of the user's persona before generating the final response, improving steerability.
- Constructs large-scale synthetic datasets with structured diversity (e.g., varying education levels, specific demographic traits) to train the meta-learner, avoiding the need for massive real-user data.
Architecture
Overview of the FSPO framework during inference.
Evaluation Highlights
- FSPO achieves an 87% average winrate against unpersonalized models on synthetic benchmarks (Reviews, ELIX, Roleplay) using Alpaca Eval.
- In a controlled human study, FSPO achieves a 72% winrate over unpersonalized models in open-ended question answering.
- Successfully transfers from synthetic training data to real users across diverse domains like pedagogical adaptation and roleplay.
Breakthrough Assessment
8/10
Strong empirical evidence that synthetic data meta-learning transfers to real users for personalization. The framework is general and addresses the key bottleneck of data scarcity in personalization.