📝 Paper Summary
Video Generation
Visual Personalization
Video Alchemist generates videos with multiple specific subjects and backgrounds by binding reference image embeddings to specific text entities within a dual-stream Diffusion Transformer, eliminating the need for test-time optimization.
Core Problem
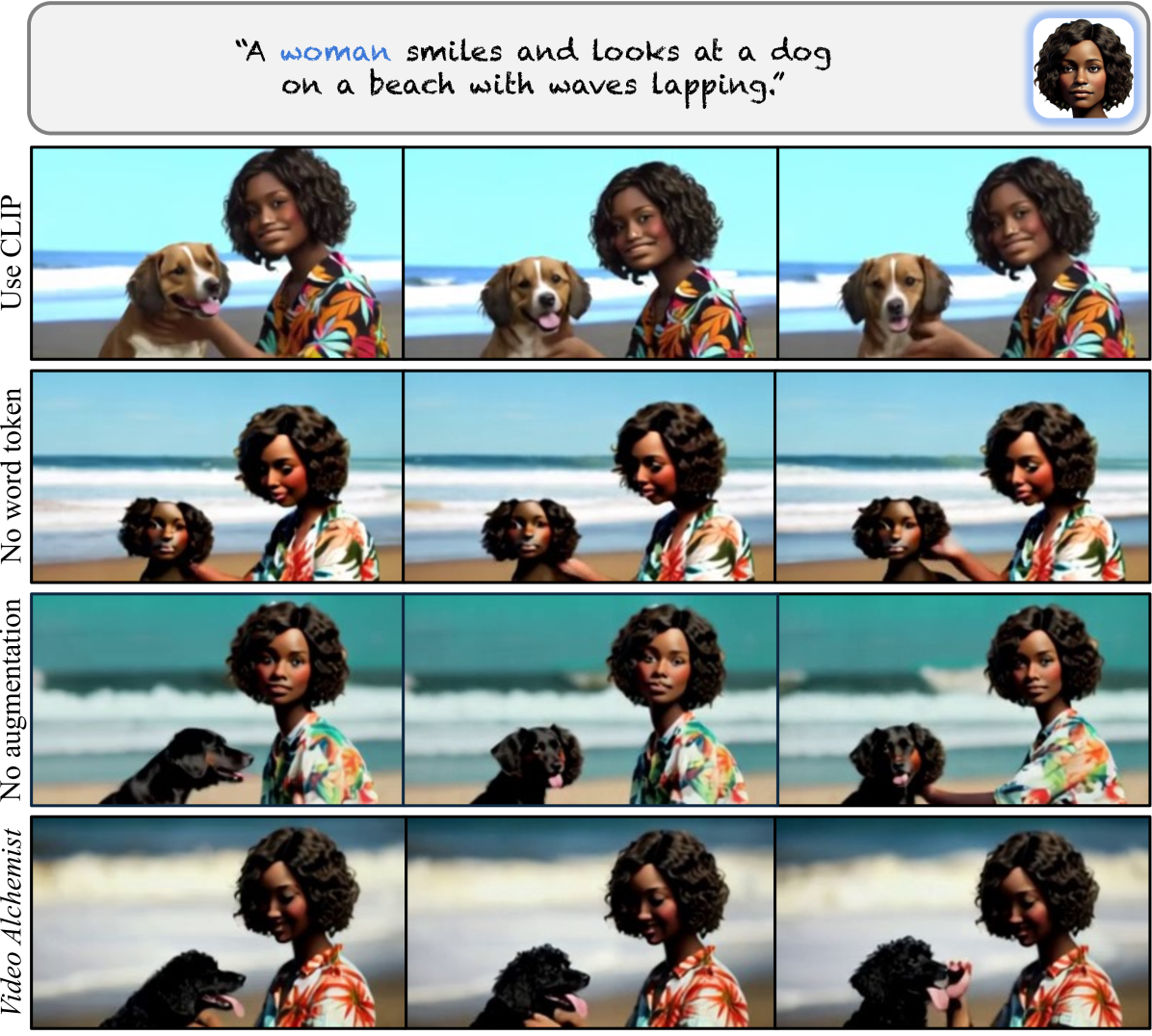
Existing video personalization methods are limited to single subjects, require slow test-time optimization, or suffer from the 'copy-and-paste' effect where the model reconstructs the reference image rather than generating new motion/contexts.
Why it matters:
- Current methods struggle to handle interactions between multiple personalized subjects (e.g., a specific person and a specific pet)
- Optimization-based methods (fine-tuning per subject) are too slow for interactive applications
- Reconstruction-based overfitting prevents models from generating diverse lighting, poses, or backgrounds, limiting creative control
Concrete Example:
When using IP-Adapter to generate a video of a person and a dog, the model often fails to bind the correct face to the correct body (e.g., placing the human face on the dog) or simply pastes the static reference image into the video without animating it.
Key Novelty
Subject-Level Identity-Text Binding in Diffusion Transformers
- Explicitly binds reference image embeddings to their corresponding textual entity words (e.g., linking the embedding of a specific dog image to the word 'dog' in the prompt) to prevent identity mixing.
- Uses a specialized Diffusion Transformer block with two separate cross-attention layers: one for global text context and a second dedicated specifically to personalization features.
- Introduces an aggressive data augmentation pipeline (shearing, blurring, color jitter) on reference images during training to force the model to learn high-level identity features rather than pixel-level reconstruction.
Architecture
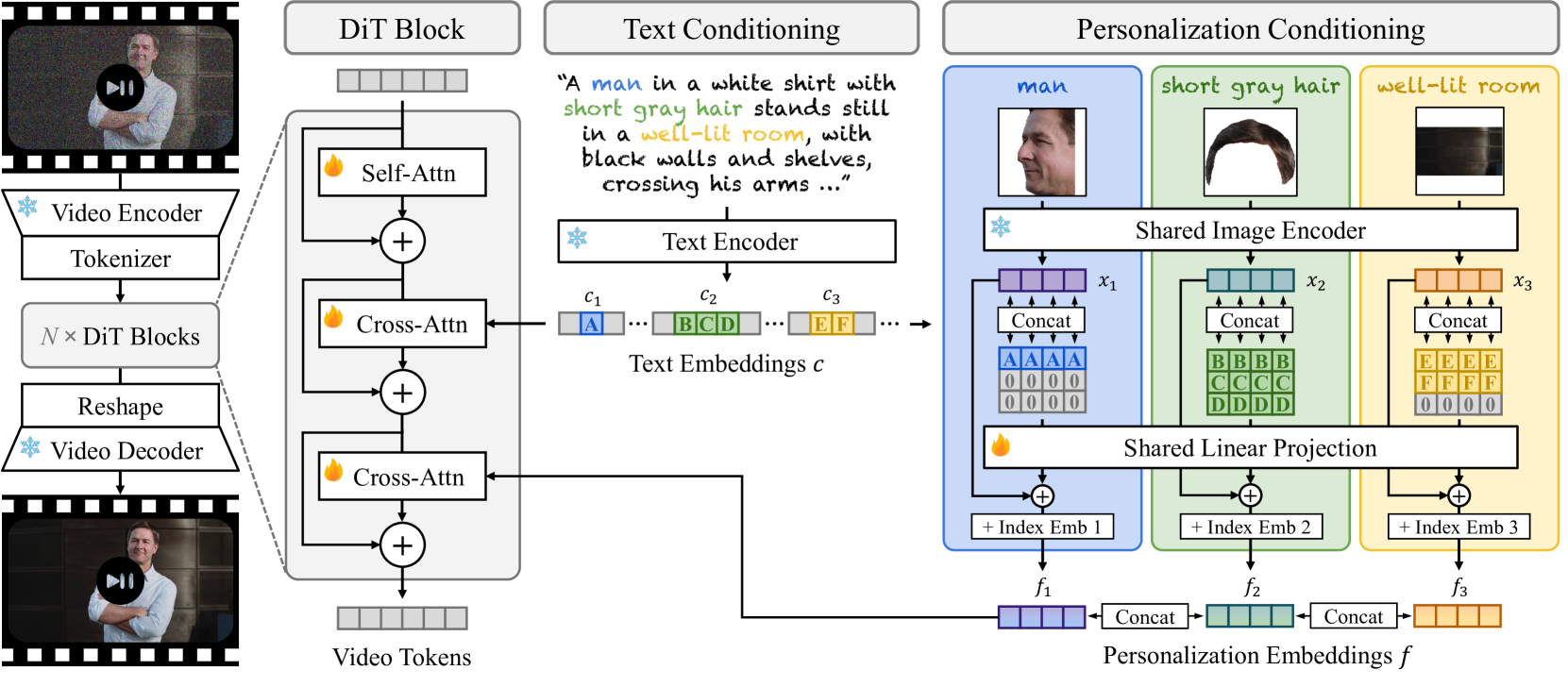
The Video Alchemist architecture, specifically the DiT block design and the token binding mechanism.
Evaluation Highlights
- +23.2% relative improvement in subject similarity (0.748 vs 0.607) compared to VideoBooth on the new MSRVTT-Personalization benchmark.
- +11.3% relative improvement in face similarity (0.755 vs 0.678) compared to IP-Adapter-FaceID+, demonstrating superior facial fidelity without optimization.
- Achieves highest dynamic degree (32.2) compared to baselines like VideoBooth (16.5) and DreamVideo (18.1), indicating better motion generation vs. static reconstruction.
Breakthrough Assessment
8/10
Significant advance in multi-subject video personalization without fine-tuning. Successfully addresses the 'binding' problem (who is who) and the 'copy-paste' overfitting problem common in prior encoder-based methods.