📝 Paper Summary
LLM Personalization
LLM Role-Playing
This survey unifies disjoint research on LLM persona into two distinct streams: Role-Playing (LLMs acting as specific characters) and Personalization (LLMs adapting to user profiles), providing a comprehensive taxonomy and evaluation review.
Core Problem
Research on leveraging personas in LLMs is disorganized and lacks a systematic taxonomy, causing confusion between methods where LLMs adopt a persona versus methods where LLMs adapt to a user's persona.
Why it matters:
- Current literature conflates 'persona' as a model attribute (role-playing) with 'persona' as a user attribute (personalization), hindering clear methodological development.
- Lack of unified terminology makes it difficult for researchers to identify relevant prior work across fields like dialogue systems, recommendation, and agentic simulation.
Concrete Example:
In a gaming context, an LLM might need to role-play a merchant (Role-Playing) while simultaneously adjusting its negotiation strategy based on the player's past purchasing history (Personalization). Without a clear taxonomy, these distinct adaptation mechanisms are often conflated.
Key Novelty
Unified Persona Taxonomy
- Distinguishes 'LLM Role-Playing' (persona belongs to the LLM to adapt to an environment) from 'LLM Personalization' (persona belongs to the user to meet individualized needs).
- Categorizes role-playing into emergent behaviors (voluntary, conformity, destructive) and schemas (single-agent vs. multi-agent).
- Categorizes personalization across domains: Dialogue, Healthcare, Education, Search, and Recommendation.
Architecture
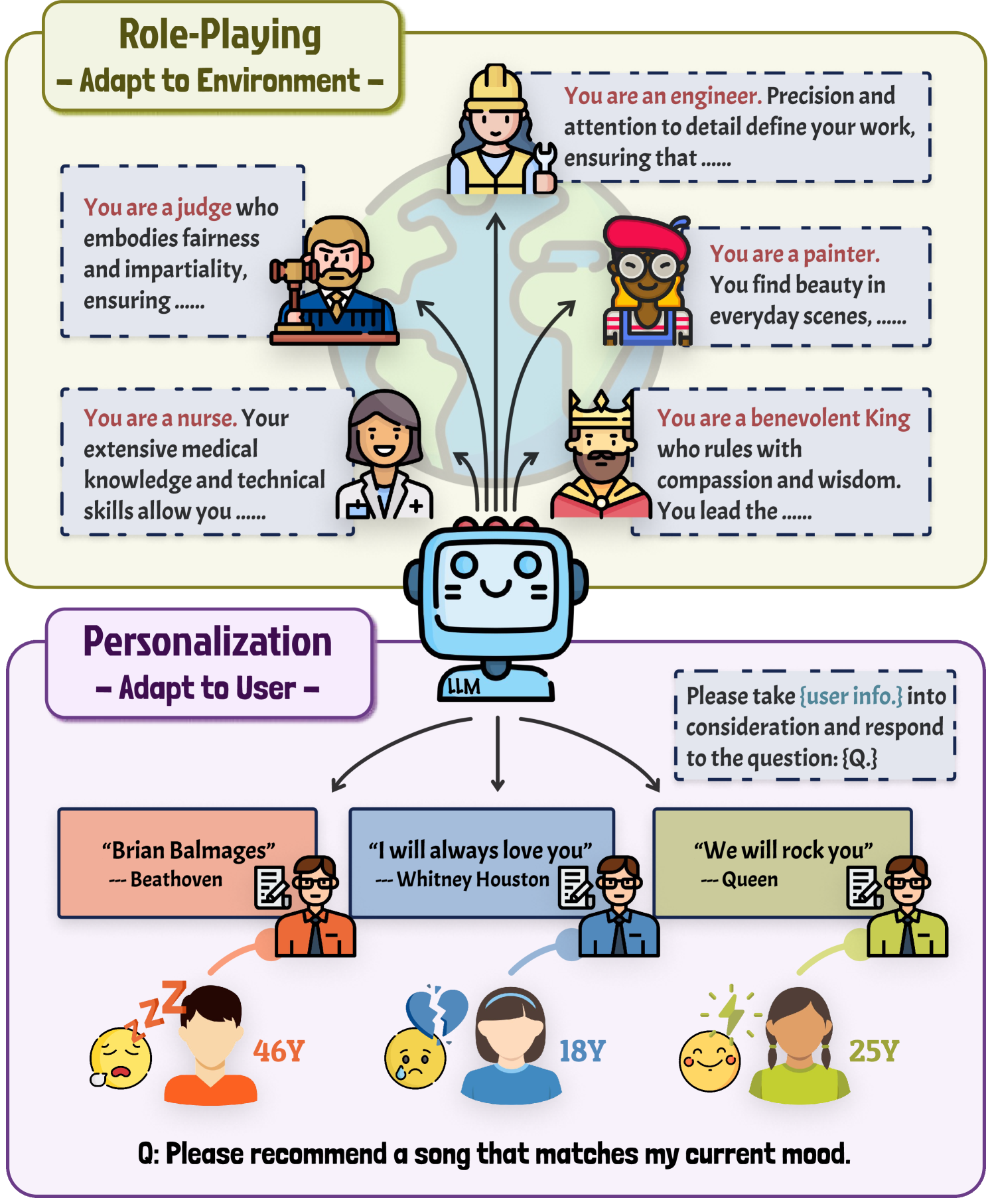
A conceptual diagram contrasting the two tales of persona: Role-Playing vs. Personalization.
Evaluation Highlights
- Identifies that LLM personality evaluation relies heavily on psychological frameworks like Big Five and MBTI (Myers-Briggs Type Indicator).
- Highlights PsychoBench as a key evaluation platform for assessing personality traits in LLMs.
- Notes that role-playing evaluation often focuses on task success (e.g., code generation rates in MetaGPT), whereas personalization evaluation focuses on user satisfaction and alignment.
Breakthrough Assessment
7/10
While a survey paper (no new model proposed), it provides a critical structural definition to a chaotic field, clearly distinguishing between agentic role-play and user-centric personalization.