📝 Paper Summary
Memory organization
Modularized RAG pipeline
MemoRAG processes long contexts by forming a compressed global memory that generates draft answer clues to guide retrieval, enabling handling of tasks with implicit or fuzzy information needs.
Core Problem
Standard RAG fails on long-context tasks where search intent is implicit (hard to formulate a clear query) or knowledge is unstructured (hard to index), while full-context LLMs are too computationally expensive.
Why it matters:
- Standard retrieval relies on semantic matching, which breaks when the query doesn't lexically overlap with the answer (e.g., 'summarize relationships').
- Directly processing ultra-long contexts (e.g., 100k+ tokens) is prohibitively slow and memory-intensive for many applications.
- Current methods struggle with 'fuzzy' tasks like summarization or high-level analysis where a specific keyword query cannot be easily formulated.
Concrete Example:
In a task asking 'What are the mutual relationships between the main characters?' for a novel, standard RAG cannot retrieve relevant chunks because the query is too broad. MemoRAG first recalls high-level character interactions from global memory to form specific clues (e.g., 'Alice interacts with Bob in Chapter 1'), which then guide precise retrieval.
Key Novelty
Dual-System Global Memory-Augmented Retrieval
- Uses a lightweight 'memory model' to compress the entire long context into compact memory tokens, forming a global overview.
- Instead of retrieving immediately, the memory model generates 'clues' (draft answers) from this global memory to bridge the gap between abstract queries and specific documents.
- Optimizes memory via Reinforcement Learning with Generation Feedback (RLGF), rewarding the memory module only when its clues lead to better final answers.
Architecture
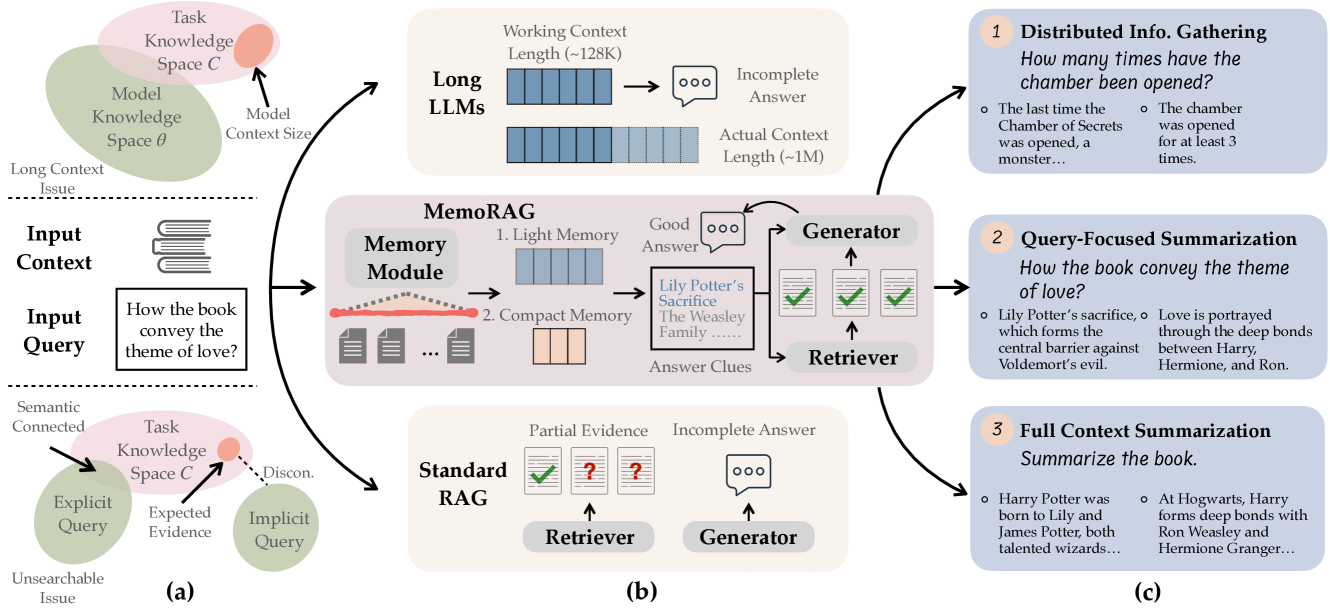
The MemoRAG architecture featuring the memory module and retrieval process.
Evaluation Highlights
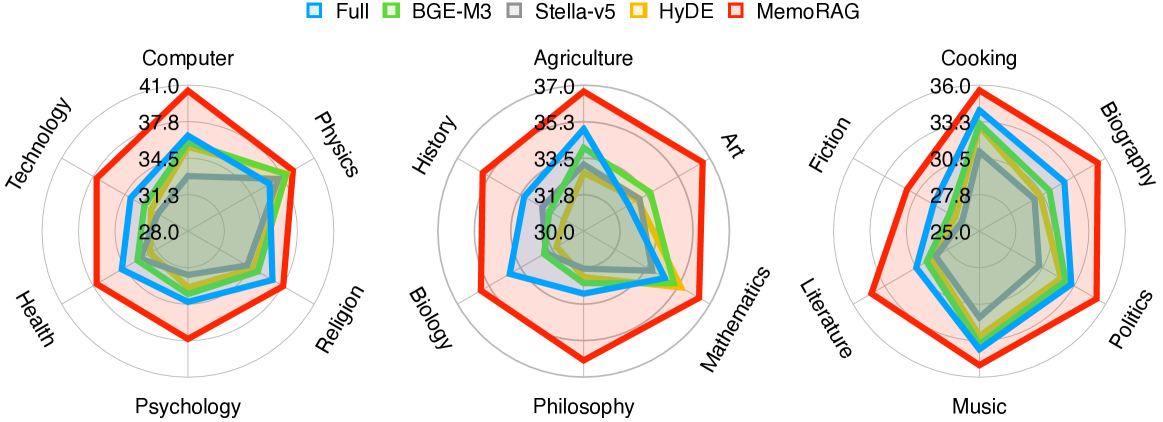
- Outperforms standard RAG and long-context models on InfiniteBench: MemoRAG achieves 55.48% (En.MC) vs. 23.32% for standard RAG and 22.89% for GPT-4-128k.
- Achieves 55.88% on LongBench (En.Sum), surpassing GPT-4o-128k (25.17%) and GraphRAG (21.71%) by a large margin on summarization tasks.
- Demonstrates high efficiency: 3-10x faster inference than full-context models like Llama-3-8B-1M-Context while maintaining superior accuracy.
Breakthrough Assessment
8/10
Significantly advances RAG by solving the 'fuzzy query' problem via global memory. Strong empirical gains over both RAG and full-context methods, though relies on a specific dual-model architecture.