📝 Paper Summary
LLM Serving Systems
Memory Management
Distributed Inference
MemServe introduces a unified memory pool (MemPool) that enables LLM serving systems to simultaneously support both context caching (inter-request optimization) and disaggregated inference (intra-request optimization) for the first time.
Core Problem
Existing LLM serving systems cannot simultaneously apply inter-request optimizations (context caching) and intra-request optimizations (disaggregated inference) because they lack mechanisms to manage and transfer KV cache data across distributed instances flexibly.
Why it matters:
- Current systems treat KV cache as intermediate data scoped to a single request/instance, preventing reuse in distributed settings like disaggregated inference.
- Missing mechanisms mean high-efficiency techniques like splitting prefill/decode phases cannot benefit from caching shared prompts, wasting compute and increasing latency.
- Existing schedulers (load-based or session-based) fail to maximize KV cache reuse across loosely coupled sessions in distributed environments.
Concrete Example:
In disaggregated inference, a request is split into prefill and decode phases on different GPUs. Current context caching methods cannot reuse the KV cache generated during the decode phase back at the prefill instance for future requests, nor efficiently transfer historical cache between them, preventing the combined benefits of both techniques.
Key Novelty
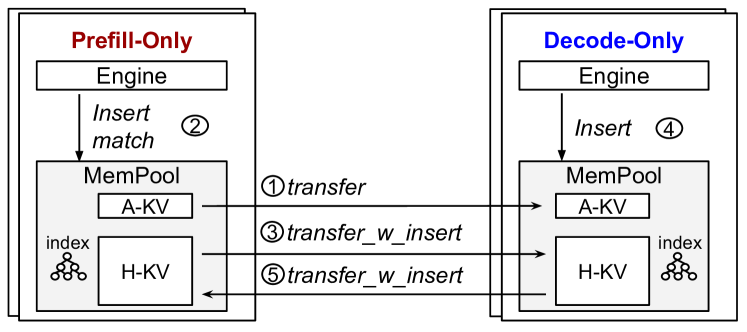
MemPool: An Elastic Memory Pool for Distributed KV Cache
- Decouples memory management from the inference engine by introducing a unified substrate (MemPool) that manages all cluster memory (GPU HBM and CPU DRAM).
- Provides a unified API for identifying, indexing, and transferring KV cache data across different physical instances, enabling data flow between prefill and decode nodes.
- Uses a global prompt tree scheduler to route requests to instances holding relevant cached data, maximizing cache hits even in distributed settings.
Architecture
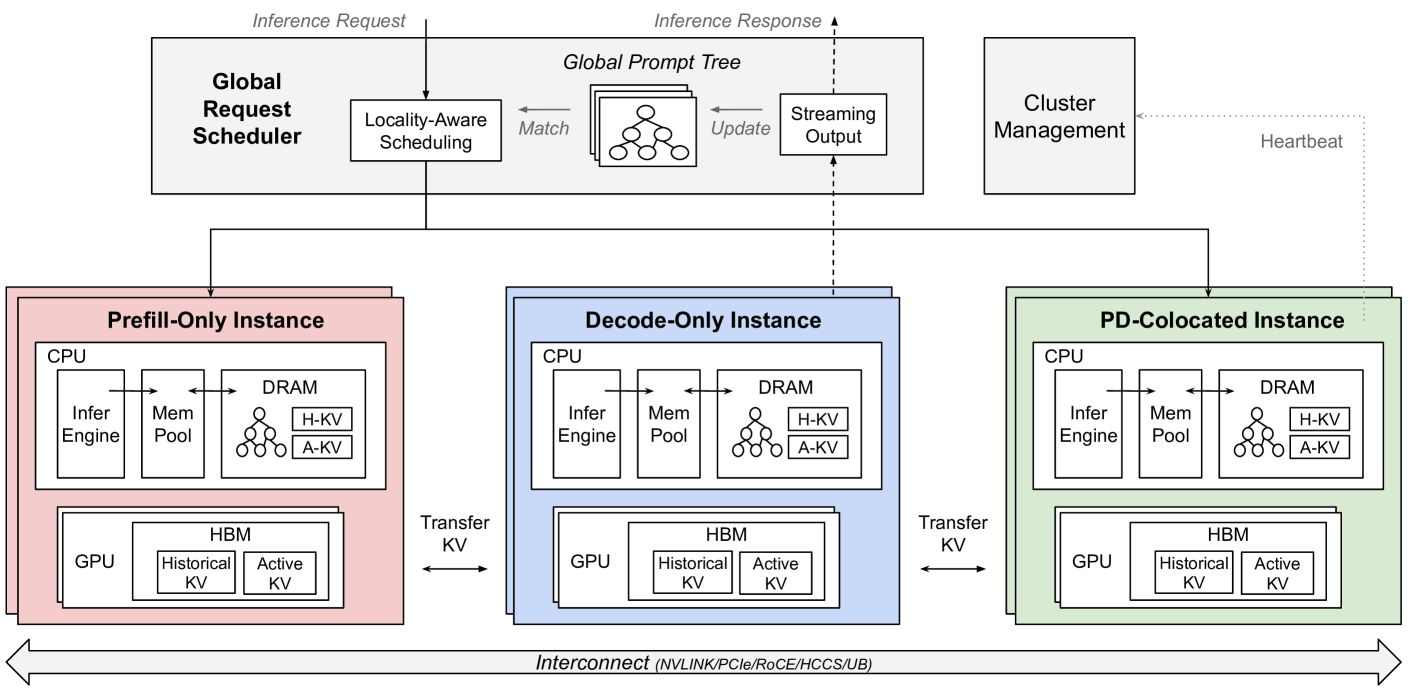
The overall architecture of MemServe, showing the interaction between the Global Scheduler, Inference Instances (Prefill/Decode), and the unified MemPool.
Evaluation Highlights
- MemPool-based disaggregated inference improves Job Completion Time (JCT) by up to 42% compared to standard colocated serving (PD-colocated) on ShareGPT workloads.
- Enhancing disaggregated inference with context caching further improves JCT by 29% over the non-cached disaggregated baseline.
- On the LooGLE dataset (long prompts), combining disaggregated inference with context caching improves JCT by 26.9% compared to disaggregated inference alone.
Breakthrough Assessment
8/10
Strong systems contribution. Effectively solves the 'either-or' problem between two critical LLM optimizations (caching vs. disaggregation) via a novel memory abstraction, with significant performance gains.