📝 Paper Summary
LLM Inference Optimization
GPU Memory Management
vAttention uses CUDA Virtual Memory Management APIs to retain contiguous virtual memory for LLM KV caches while allocating physical memory on demand, enabling the use of unmodified high-performance attention kernels.
Core Problem
PagedAttention, the standard for dynamic KV cache management, fragments virtual memory, forcing complex kernel rewrites and incurring runtime overheads for address translation and metadata management.
Why it matters:
- Rewriting kernels for PagedAttention (PA) is difficult, causing production systems to lag behind state-of-the-art research (e.g., FlashAttention-3 did not initially support PA).
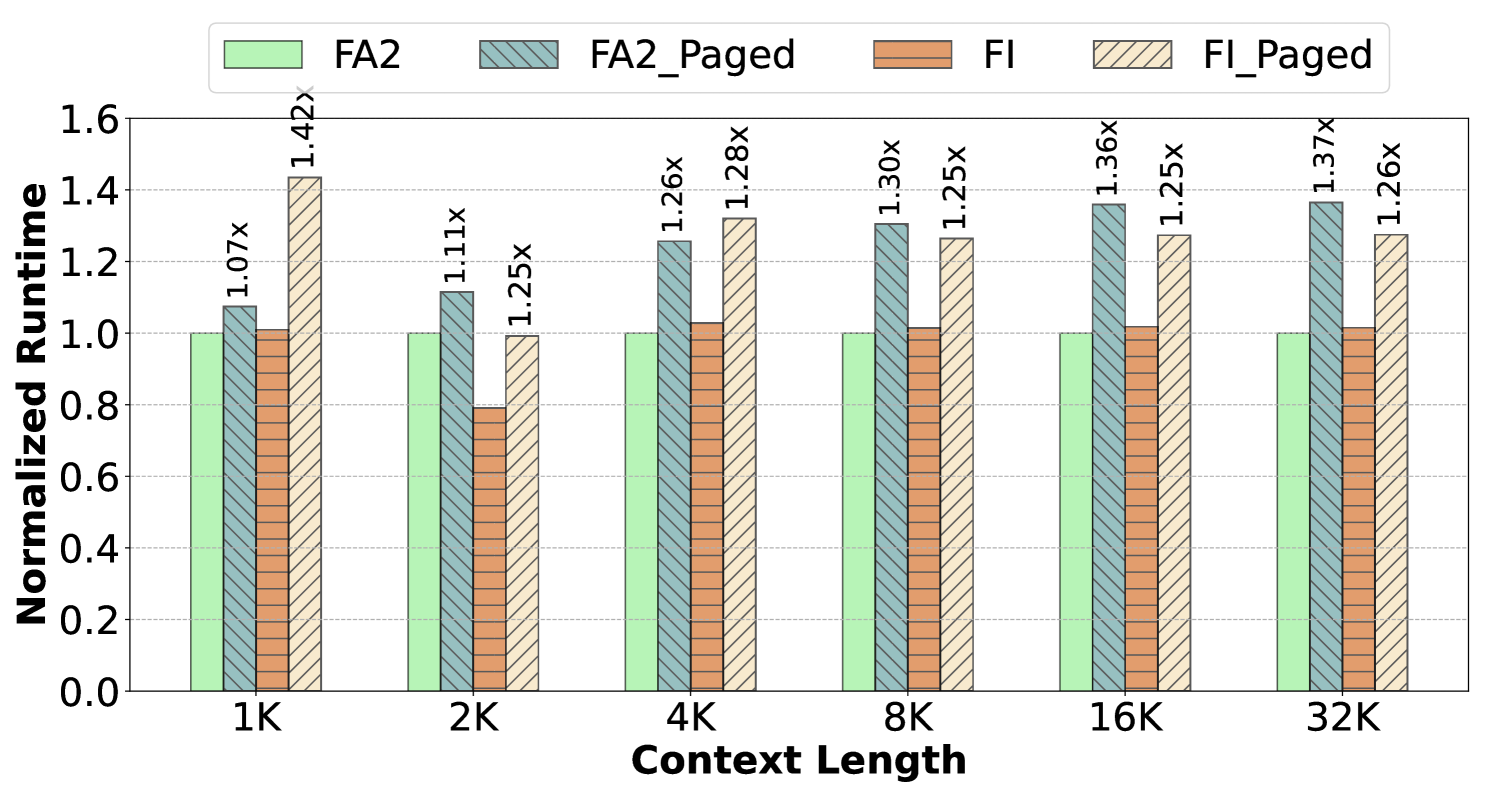
- PA introduces overhead in the critical path: vLLM's paged kernels are up to 2.8x slower than standard FlashAttention-2 kernels.
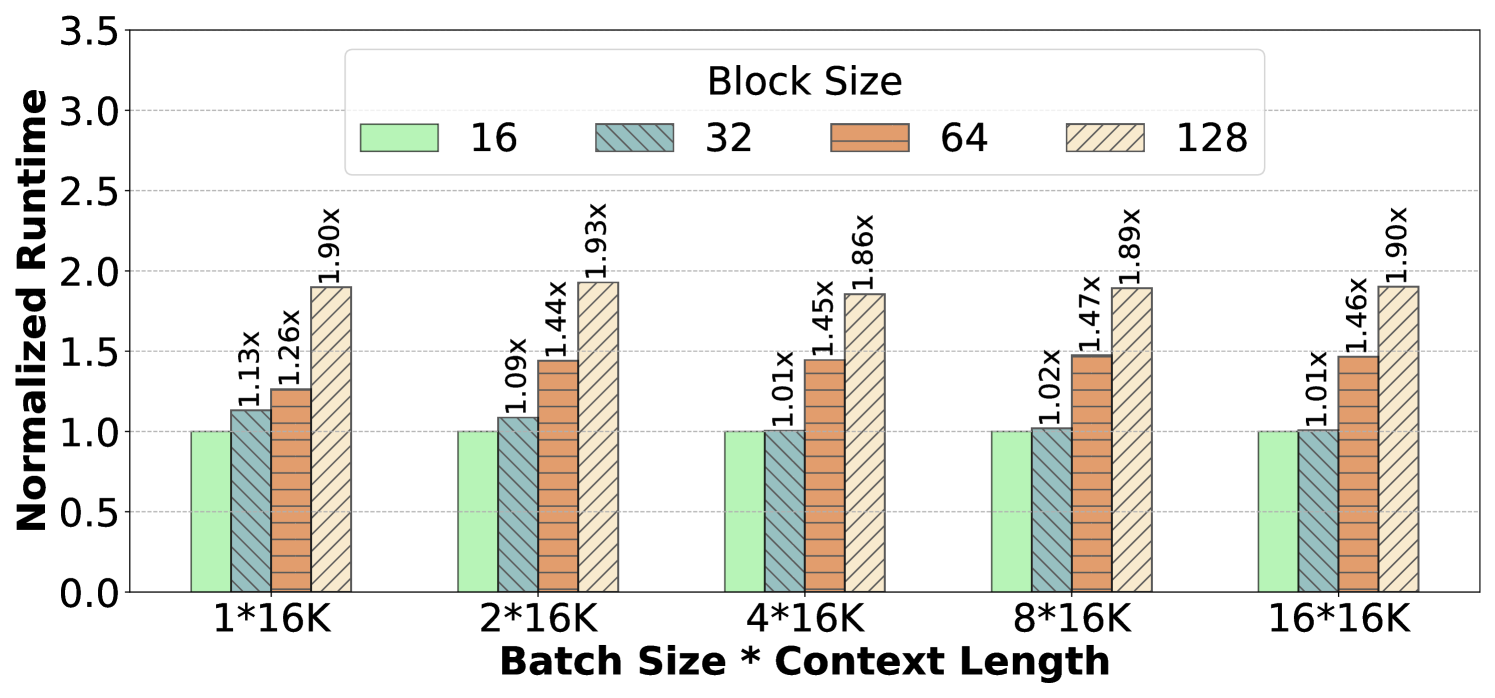
- Managing block tables adds CPU overhead, contributing up to 30% latency in decode iterations in some configurations.
Concrete Example:
When a request grows dynamically, PagedAttention allocates non-contiguous memory blocks. To compute attention, the kernel must manually traverse a software-managed 'Block Table' to find data, unlike standard kernels that simply access a contiguous array. This software translation slows down execution and complicates kernel code.
Key Novelty
Decoupled Virtual/Physical Allocation (vAttention)
- Reserves a large contiguous range of virtual memory for the KV cache upfront but delays physical memory allocation until needed, mimicking OS-level demand paging on the GPU.
- Leverages low-level CUDA VMM (Virtual Memory Management) APIs to map physical pages to the pre-reserved virtual addresses on the fly, keeping the buffer contiguous to the application.
- Hides the high latency of OS-level memory allocation by overlapping allocation with computation and opportunistically pre-allocating pages for future tokens.
Architecture
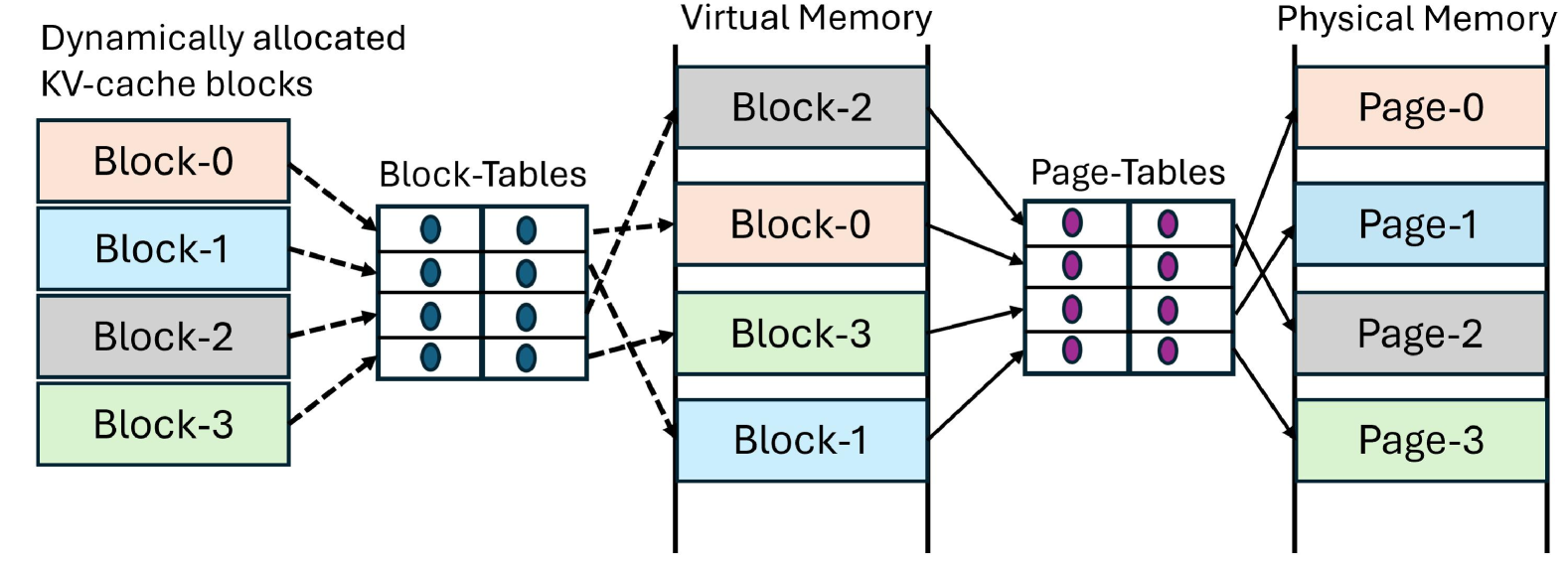
Conceptual comparison of memory layouts between PagedAttention and vAttention
Evaluation Highlights
- Improves end-to-end serving throughput by up to 1.23x compared to PagedAttention-based FlashInfer on Llama-3-8B.
- Outperforms vLLM's decode throughput by up to 1.99x when using vAttention with the standard FlashAttention-2 kernel.
- Enables immediate support for FlashAttention-3 (FA3) without code changes, yielding 1.26x-1.5x higher throughput over PagedAttention-based FlashAttention-2 (since FA3 lacks native PA support).
Breakthrough Assessment
8/10
Significant systems contribution that solves a major fragmentation pain point without the software complexity of PagedAttention. Restores compatibility with standard kernels, likely simplifying future LLM serving stacks.