📝 Paper Summary
Memory organization
Inference acceleration
DMC retrofits pre-trained LLMs to dynamically compress the Key-Value cache at inference time by learning to accumulate token representations via weighted averaging rather than appending every token.
Core Problem
The Key-Value (KV) cache in Transformers grows linearly with sequence length and batch size, making auto-regressive generation memory-bound and limiting throughput for long contexts.
Why it matters:
- High Bandwidth Memory (HBM) bottlenecks dominate generation latency, as most time is spent moving weights and KV states rather than computing.
- Existing solutions like eviction (H2O, TOVA) or token merging often degrade downstream performance significantly at high compression ratios.
- Linear memory growth prevents large batch sizes and long contexts on fixed hardware budgets (e.g., H100 GPUs).
Concrete Example:
In a standard Transformer generating a story, every single token (e.g., 'the', 'a') adds a new entry to the memory cache. Over 4000 tokens, this cache becomes massive, forcing the GPU to fetch 4000 vectors for every new prediction, slowing generation to a crawl even if the GPU has compute power to spare.
Key Novelty
Dynamic Memory Compression (DMC)
- Replaces the standard 'always append' cache update with a learned decision: either append the new token or merge it into the previous cache slot via weighted averaging.
- Uses 'retrofitting' (continued pre-training on ~2-8% of original data) to teach the model how to compress its own memory without adding new parameters.
- Learns different compression rates for different attention heads and layers, adapting to the model's internal information flow.
Architecture
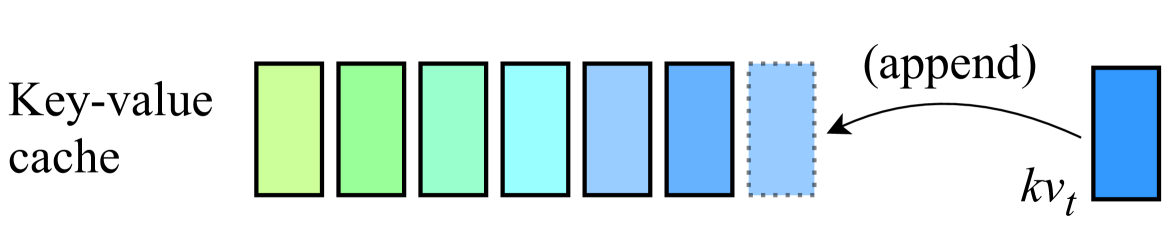
Conceptual operation of Dynamic Memory Compression at a single time step.
Evaluation Highlights
- Increases inference throughput by 350% to 390% for Llama 2 7B and 13B on NVIDIA H100 GPUs using 4x compression.
- Achieves up to 700% throughput gain with 8x compression (approx 5% MMLU drop) compared to uncompressed baselines.
- Combines with Grouped Query Attention (GQA) for compounded gains: Llama 2 70B (GQA 8x) + DMC 2x yields 16x total compression.
Breakthrough Assessment
8/10
Offers a practical, hardware-aware solution to the KV cache bottleneck that outperforms eviction baselines and requires no architectural changes (no new parameters), making it highly deployable.