📝 Paper Summary
Memory recall
Agentic RAG pipeline
ReadAgent extends effective LLM context length by compressing text into sequential gist memories and allowing the model to interactively retrieve full-text pages only when necessary.
Core Problem
LLMs struggle with very long documents due to context window limits and performance degradation ('lost in the middle') when processing massive amounts of raw text, unlike humans who use fuzzy memory and lookup.
Why it matters:
- Current methods either truncate text (losing info) or use retrieval (RAG) which lacks global context, causing failures in reasoning over books or long meeting transcripts
- LLMs become inefficient and prone to hallucination when forced to consume tens of thousands of tokens of raw text for simple queries
Concrete Example:
In the QMSum dataset (meeting transcripts), a standard LLM might fail to answer 'Why did John object?' because the relevant detail is buried in a 20,000-word transcript. ReadAgent summarizes the meeting first, then uses the summary to decide to specifically look up 'Page 7' where the objection occurred.
Key Novelty
Human-Inspired Interactive Gist Memory
- Mimics human reading by first creating short, fuzzy summaries ('gists') of text chunks to maintain a global narrative flow within the context window
- Uses an interactive lookup mechanism where the LLM reads the gists and explicitly requests to expand specific 'pages' into raw text to verify details
Architecture
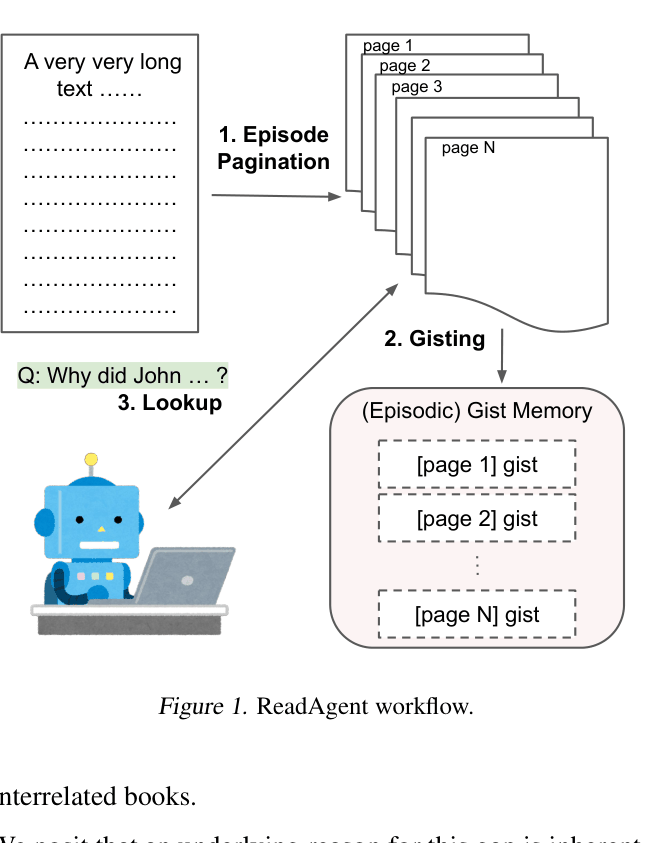
The ReadAgent workflow illustrating the three-step process: Episode Pagination, Memory Gisting, and Interactive Lookup.
Evaluation Highlights
- Outperforms retrieval baselines on NarrativeQA (Gutenberg) by 31.98% in ROUGE-L and ~13% in LLM Rating, while handling books up to 343k words
- Extends effective context window by 3.5x to 20x compared to processing raw text, achieving higher accuracy with fewer tokens consumed
- Surpasses full-context performance on QuALITY (87.17% vs 85.83%) even when the full text fits in context, showing that compressing distracting information improves reasoning
Breakthrough Assessment
8/10
Simple, elegant solution that mimics human cognition to solve a major LLM limitation. Strong empirical results across diverse long-context tasks without requiring model training.