📝 Paper Summary
World Models
Video Generation
Memory Forcing trains video diffusion models to dynamically balance temporal context for exploration and geometry-indexed spatial memory for revisitation, ensuring consistency in Minecraft environments.
Core Problem
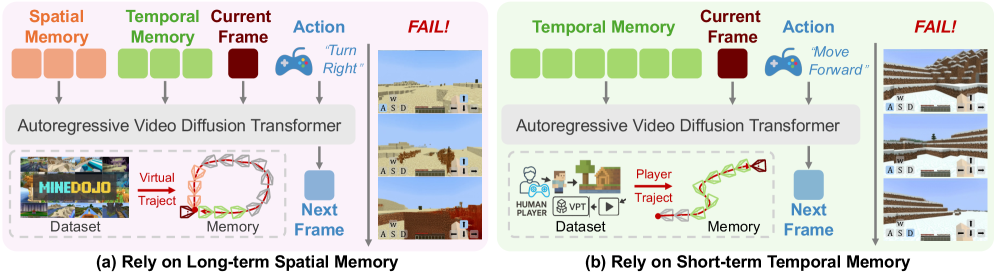
Autoregressive video models face a trade-off: temporal-only memory enables smooth exploration but fails on revisits (inconsistency), while spatial-heavy memory preserves consistency but degrades generation in novel scenes due to missing context.
Why it matters:
- Interactive world models must handle both unlimited exploration of new terrain and consistent rendering of previously built structures
- Prior methods using teacher-forcing underestimate inference-time drift, leading to over-reliance on short-term cues and ignoring retrieved memory
Concrete Example:
A temporal-only model exploring a Minecraft world will generate a house, walk away, and upon returning find the house has changed or disappeared. A spatial-only model might fail to generate coherent terrain when walking into a completely new, unvisited area.
Key Novelty
Memory Forcing Training Framework & Geometry-indexed Memory
- Hybrid Training pairs distinct data regimes: temporal conditioning for exploration (human play) and spatial conditioning for revisits (synthetic trajectories), teaching the model to switch strategies.
- Chained Forward Training (CFT) trains on the model's own past predictions (rollouts) rather than ground truth, forcing it to rely on spatial memory to correct accumulated drift.
- Geometry-indexed Spatial Memory replaces appearance-based retrieval with 3D point-to-frame mapping, ensuring retrieved frames are geometrically relevant to the current view.
Architecture
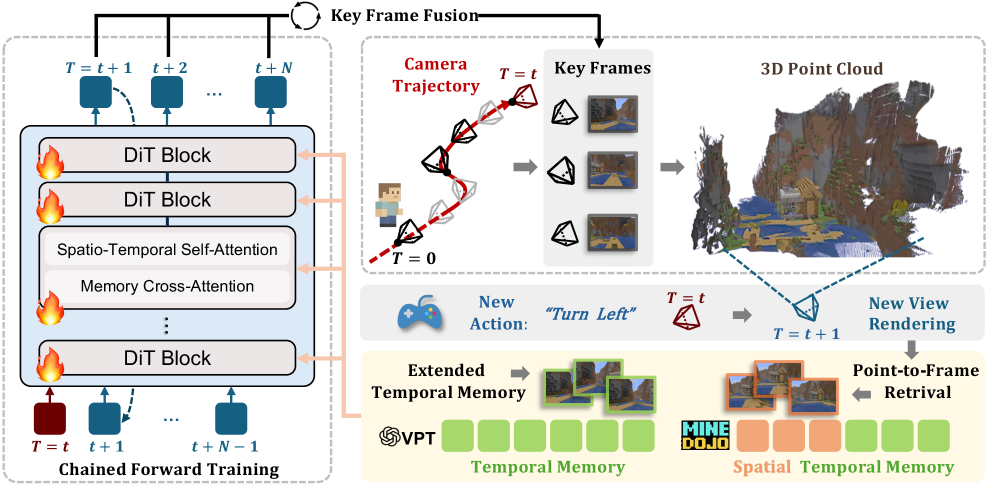
The overall model architecture including the DiT backbone, memory cross-attention, and the spatial memory extraction pipeline via VGGT.
Evaluation Highlights
- 98.2% reduction in memory storage compared to frame-based baselines by storing only distinct keyframes and geometry
- 7.3x faster retrieval speed than appearance-based methods due to O(1) complexity of point-to-frame lookup
- Qualitatively superior consistency on revisits and generation quality in new environments (numeric quality metrics not extractable from provided text)
Breakthrough Assessment
8/10
Addresses the critical stability-plasticity dilemma in world models (consistent revisits vs. novel generation) with a principled training curriculum and geometry-aware architecture.