📝 Paper Summary
Parameter-Efficient Fine-Tuning (PEFT)
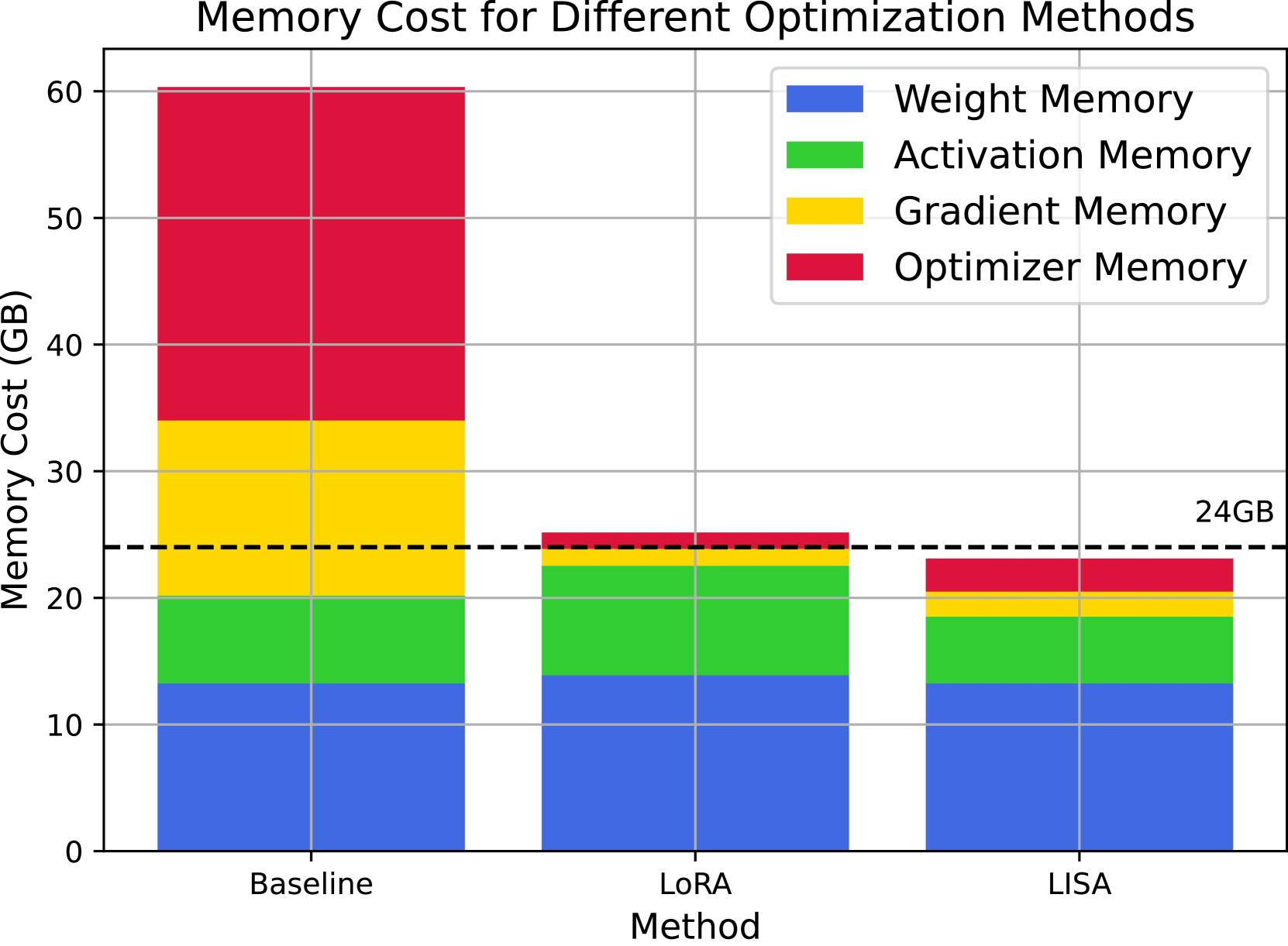
Memory-Efficient Optimization
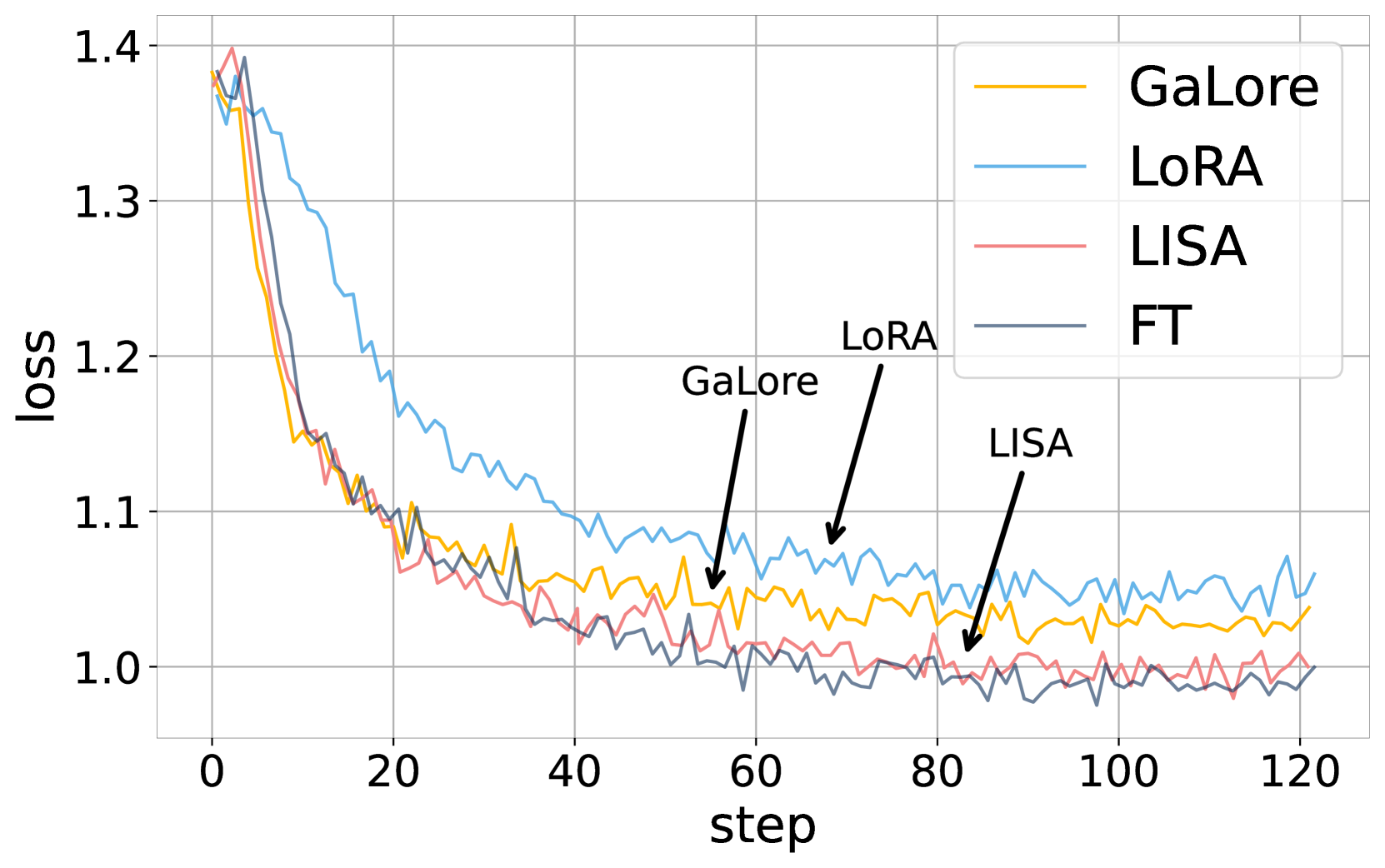
LISA randomly unfreezes different layers of an LLM during fine-tuning based on importance sampling probabilities derived from LoRA's weight norms, matching full-parameter performance with LoRA-level memory costs.
Core Problem
Full-parameter fine-tuning of large LLMs (e.g., 70B) is memory-prohibitive, while parameter-efficient methods like LoRA often fail to match full-parameter performance, especially in large-scale continual pre-training.
Why it matters:
- Fine-tuning 70B+ models typically requires massive GPU resources inaccessible to most researchers.
- Existing efficient methods like LoRA confine updates to a low-rank subspace, limiting representation power and performance on complex tasks like math reasoning.
- Bridging the gap between memory efficiency and full-parameter performance is critical for democratizing LLM adaptation.
Concrete Example:
When fine-tuning LLaMA-2-70B, full parameter training crashes on limited hardware (requires >160GB), while LoRA fits but lags by >10% on MT-Bench. LISA fits on the same hardware as LoRA but matches or exceeds full-parameter accuracy.
Key Novelty
Layerwise Importance Sampled AdamW (LISA)
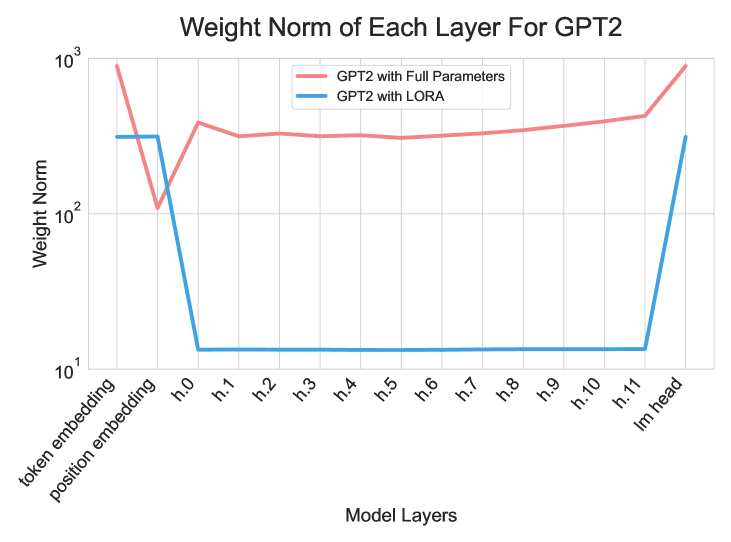
- Observes that LoRA updates are heavily skewed towards embedding and head layers, while middle layers have small weight norms, suggesting varying layer importance.
- Proposes randomly unfreezing a small subset of layers (e.g., 2) at each step while freezing the rest, with sampling probabilities based on these importance observations.
- Emulates the memory footprint of LoRA (by activating few layers) but the optimization trajectory of full-parameter tuning (by eventually touching all parameters).
Architecture
Pseudocode of the LISA algorithm describing the layerwise sampling and update process.
Evaluation Highlights
- Outperforms LoRA by 11-38% on MT-Bench across LLaMA-2-7B, Mistral-7B, and LLaMA-2-70B models.
- Surpasses LoRA on GSM8K (58.4% vs 52.8%) and PubMedQA (72.6% vs 51.0%) with LLaMA-2-70B.
- Matches or exceeds Full-Parameter Training performance on GSM8K and PubMedQA while using significantly less memory (e.g., 75GB vs >160GB for 70B models).
Breakthrough Assessment
9/10
Simple yet highly effective strategy that challenges the dominance of LoRA. It offers a 'free lunch'—full-parameter performance at LoRA memory costs—and is validated on 70B scale models.