📝 Paper Summary
Context length extrapolation
Efficient context computation
InfLLM enables standard LLMs to process extremely long sequences (up to 1 million tokens) without training by offloading distant contexts to a CPU memory and retrieving relevant blocks using representative tokens.
Core Problem
LLMs pre-trained on short sequences fail on long inputs due to out-of-domain issues and attention distraction, while continual pre-training is computationally expensive and can degrade short-context performance.
Why it matters:
- LLM-driven agents and applications require processing continuous streaming inputs (e.g., historical logs, long documents) far exceeding typical context windows (4K-8K tokens)
- Fine-tuning for long contexts requires massive compute and high-quality long datasets, which are often unavailable
- Naive sliding window approaches discard distant information, making it impossible to capture long-range dependencies essential for comprehensive understanding
Concrete Example:
When a model trained on 4K tokens tries to answer a question based on a specific detail found at token 100,000 in a book, standard models crash or hallucinate. Sliding window methods (like StreamingLLM) 'forget' that early token. InfLLM retrieves the block containing the detail from memory.
Key Novelty
Training-Free Block-Level Context Memory
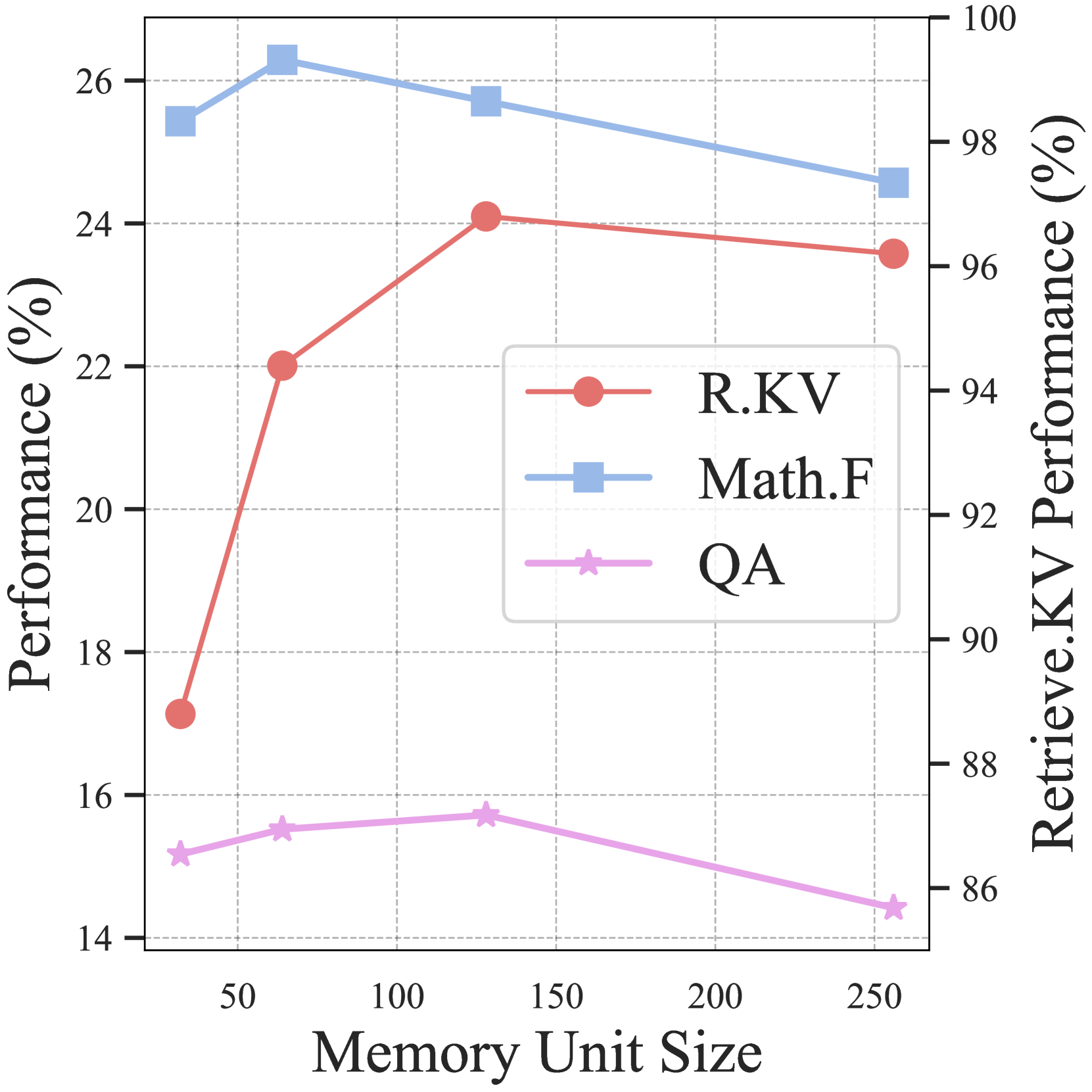
- Instead of storing every token's history in GPU memory, InfLLM groups past Key-Value (KV) vectors into blocks and offloads them to CPU
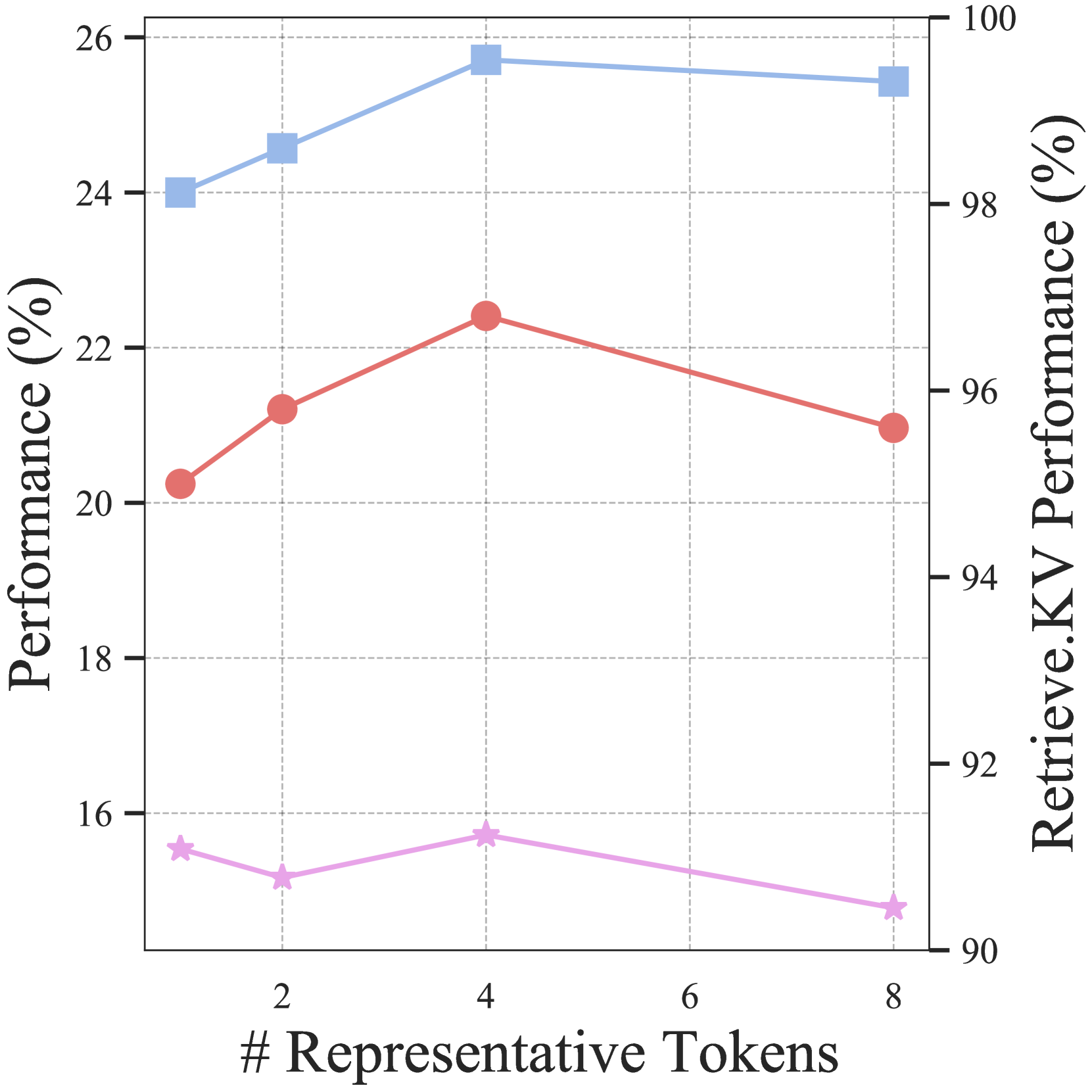
- Each block is represented by a few 'representative tokens' (those that received the highest attention locally), avoiding the need for a separate trained encoder
- During inference, the model retrieves only the most relevant blocks based on similarity to current tokens, combined with a local sliding window
Architecture
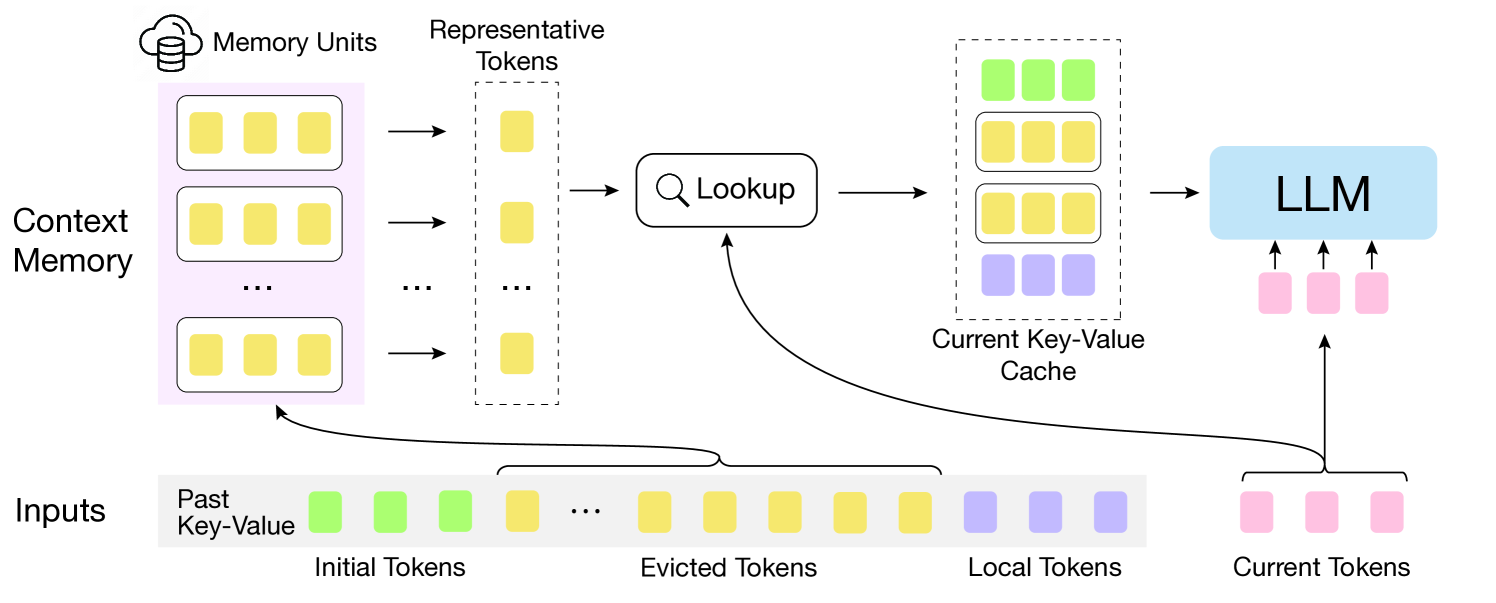
Overview of InfLLM processing a streaming sequence. It shows the division of context into Initial tokens, Evicted tokens (Memory), and Local tokens.
Evaluation Highlights
- Achieves comparable performance (22.82% avg score) to Llama-3-8B-Instruct-262k (22.86%) on the ∞-Bench benchmark despite using the base 8K-context model without fine-tuning
- Maintains 100% accuracy on 'Needle in a Haystack' passkey retrieval tasks extended up to 1,024K (1 million) tokens
- Outperforms StreamingLLM on LongBench average by +27.59 points (44.18 vs 16.59) using Mistral-7B-Instruct-v0.2
Breakthrough Assessment
8/10
Significantly extends effective context length to 1M tokens without ANY training, matching fine-tuned baselines. The block-level representative token mechanism is a clever, efficient heuristic.