📝 Paper Summary
Memory organization
Self-evolving Agentic reasoning
Evo-Memory introduces a benchmark for streaming agent tasks and proposes ReMem, an agent that continually refines its memory via a dedicated reasoning action to reuse experience across tasks.
Core Problem
Current LLM memory systems are static, focusing on recalling past dialogue rather than learning strategies from experience, causing agents to repeatedly make the same mistakes in sequential tasks.
Why it matters:
- Agents in real-world environments (e.g., coding assistants) face continuous task streams but often fail to adapt strategies, solving similar problems from scratch every time
- Existing benchmarks measure factual retention (conversational recall) but ignore whether the agent actually learns to solve problems better (experience reuse)
- Standard RAG (Retrieval-Augmented Generation) retrieves context passively but lacks a mechanism to evolve or abstract reasoning strategies over time
Concrete Example:
A long-term coding assistant might recall a user's previous library preference (context recall) but fail to remember the specific debugging strategy that fixed a recurring error in that library, forcing it to re-derive the solution in every session.
Key Novelty
ReMem: An Action-Think-Refine Agent Loop
- Extends the standard ReAct (Reason + Act) loop by adding a 'Refine' action, allowing the agent to explicitly reason about and update its own memory state
- treats memory management not as a hard-coded background process but as a decision-making step within the agent's action space
- Introduces a streaming evaluation framework (Evo-Memory) that restructures static datasets into sequential streams to measure improvement over time
Architecture
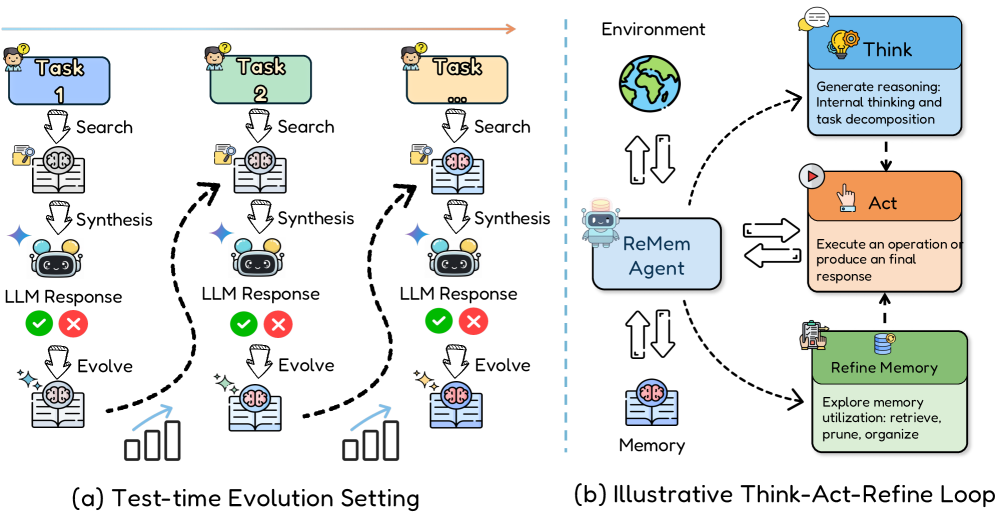
Conceptual framework of Evo-Memory and the ReMem agent architecture.
Evaluation Highlights
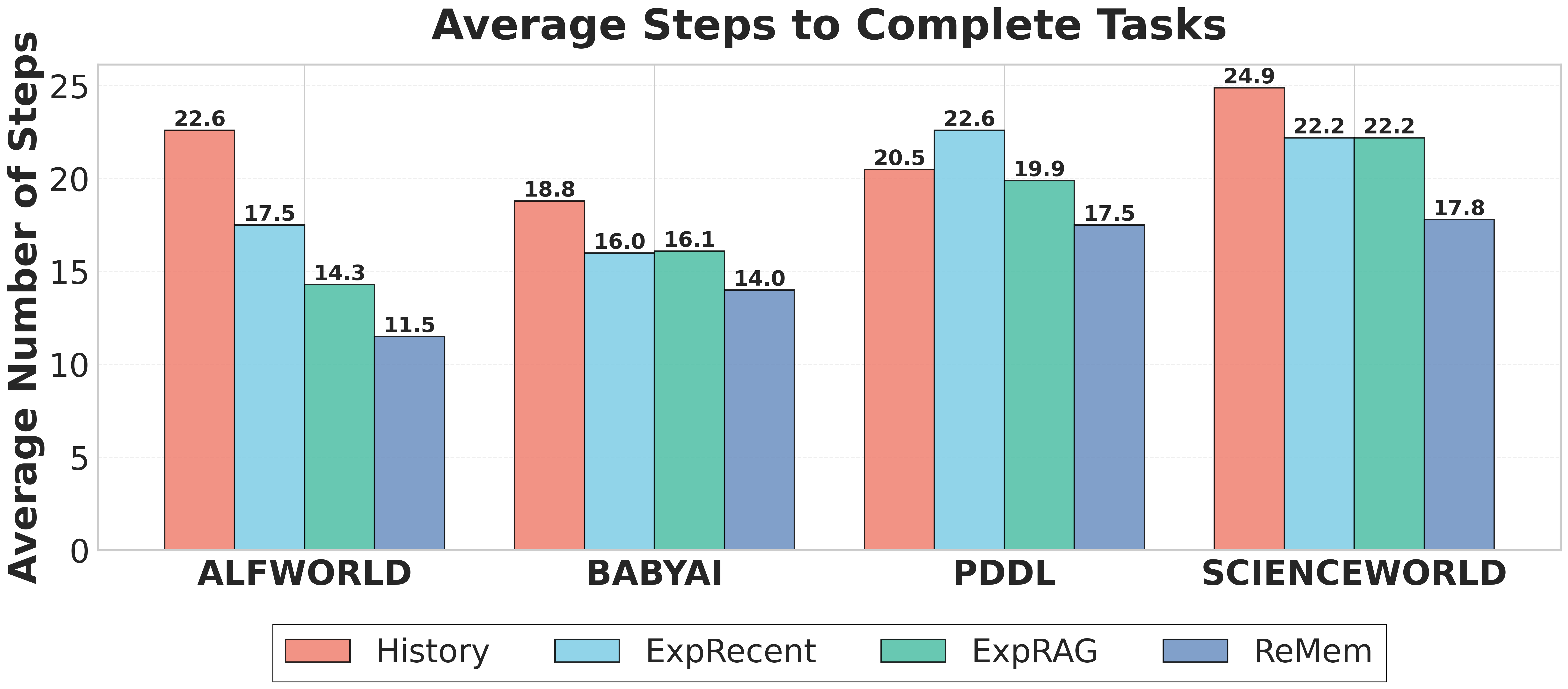
- ReMem achieves 0.92 success rate on the BabyAI multi-turn navigation benchmark using Gemini-2.5 Flash, demonstrating strong procedural learning
- In single-turn reasoning (AIME, GPQA), ReMem reaches 0.65 average exact match with Gemini-2.5 Flash, consistently improving over static baselines
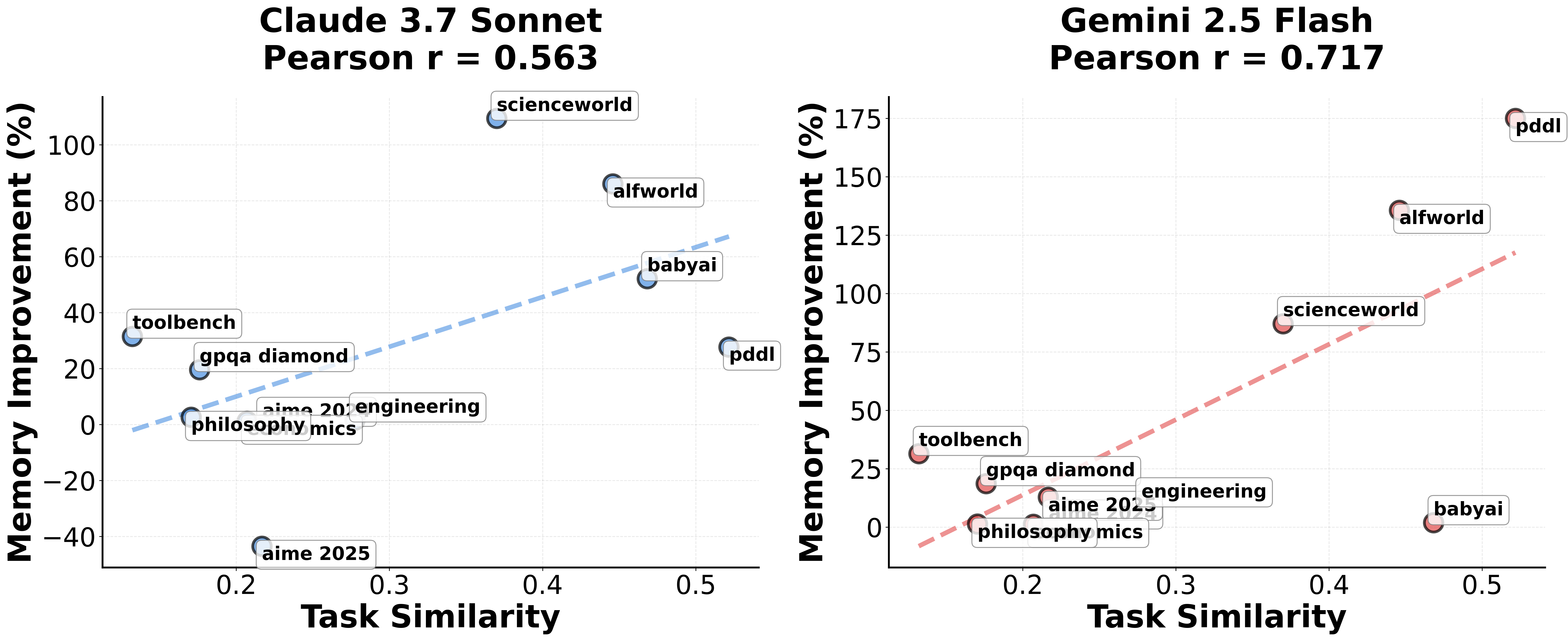
- Performance gains show strong correlation (Pearson r=0.717) with task similarity, confirming that the method effectively exploits structural similarities between tasks
Breakthrough Assessment
8/10
Addresses a critical gap in agentic memory (experience reuse vs. simple recall) with a novel unified framework. The shift from passive RAG to active memory refinement is a significant methodological step.