📝 Paper Summary
Latent-Space Memory
Long-Context LLMs
M+ extends MemoryLLM by offloading older latent memory states to a CPU-based long-term storage and using a co-trained retriever to fetch relevant information during generation, enabling context retention beyond 160k tokens.
Core Problem
Existing latent-space memory models like MemoryLLM compress context into a fixed-size GPU memory pool, causing information loss after roughly 20k tokens as older states are discarded.
Why it matters:
- Retaining information from the distant past is critical for long-book understanding and extended conversations
- Current approaches either drop information (sliding windows) or use separate, high-latency retrievers for every query head (like SnapKV)
- Scaling context windows usually incurs prohibitive GPU memory costs
Concrete Example:
MemoryLLM effectively handles sequences up to 16k tokens, but when processing a 160k token sequence, it fails to recall knowledge injected at the beginning because the fixed-size memory pool (1B parameters) forces the eviction of early information.
Key Novelty
Scalable Latent-Space Long-Term Memory with Co-Trained Retrieval
- Instead of deleting tokens evicted from the GPU short-term memory, M+ moves them to a CPU-based long-term memory (LTM), preserving them indefinitely.
- Integrates a lightweight retriever trained jointly with the LLM to fetch relevant latent states from the CPU LTM back to the GPU during generation.
- Uses separate LoRA adapters for the memory 'update' (writing/compressing) and 'generate' (reading/loading) phases to optimize each distinct task.
Architecture
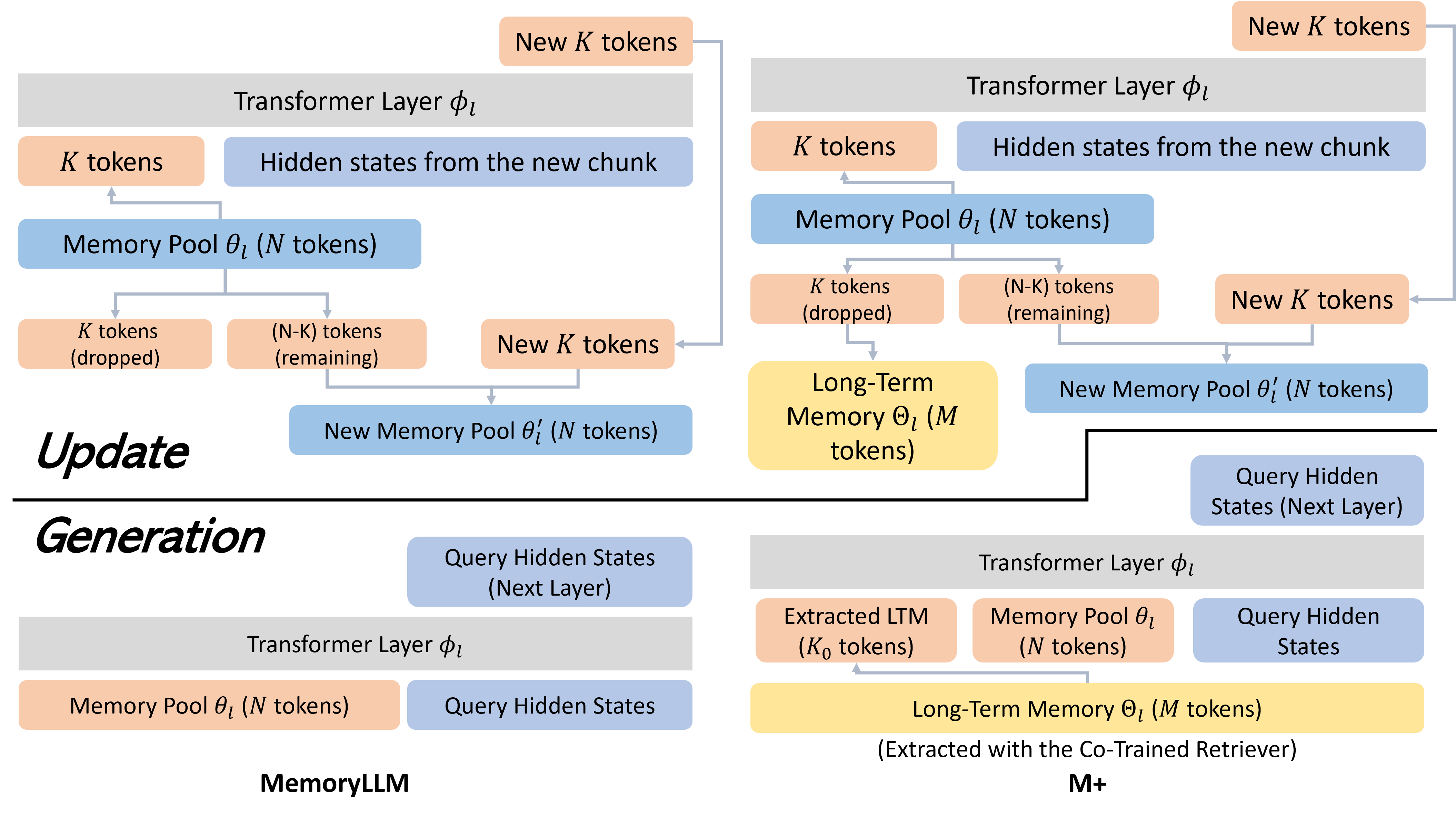
The Update and Generate processes of M+. It illustrates how tokens dropped from the GPU Short-Term Memory (STM) during the Update phase are moved to the CPU Long-Term Memory (LTM). It also shows the Generate phase where relevant tokens are retrieved from LTM and concatenated with STM.
Evaluation Highlights
- Extends effective knowledge retention from <20k tokens (MemoryLLM) to >160k tokens.
- Maintains similar GPU memory overhead to MemoryLLM by storing long-term history on CPU.
- Retrieves memory once per layer for all heads, improving efficiency compared to per-head retrieval methods like H2O or SnapKV.
Breakthrough Assessment
8/10
Significantly extends the utility of latent-space memory models by solving the 'forgetting' problem via CPU offloading, bridging the gap between fixed-context models and RAG.