📊 Experiments & Results
Evaluation Setup
Multi-session personalized dialogue simulation.
Benchmarks:
- MSC (Multi-Session Chat) (Long-term personalized dialogue generation)
- LongMemEval (Long-term memory retrieval and QA)
Metrics:
- METEOR
- BERTScore
- Recall@K
- Accuracy (LLM Judge)
- Statistical methodology: Not explicitly reported in the paper
Key Results
| Benchmark | Metric | Baseline | This Paper | Δ |
|---|---|---|---|---|
| Main comparison on MSC dataset showing RMM outperforms baselines in text generation quality. | ||||
| MSC | METEOR(%) | 27.5 | 33.4 | +5.9 |
| MSC | BERT(%) | 52.1 | 57.1 | +5.0 |
| Main comparison on LongMemEval dataset evaluating retrieval and QA accuracy. | ||||
| LongMemEval | Recall@5(%) | 62.4 | 69.8 | +7.4 |
| LongMemEval | Acc.(%) | 63.6 | 70.4 | +6.8 |
| LongMemEval | Acc.(%) | 58.8 | 61.2 | +2.4 |
| LongMemEval | Acc.(%) | 59.6 | 61.2 | +1.6 |
Experiment Figures
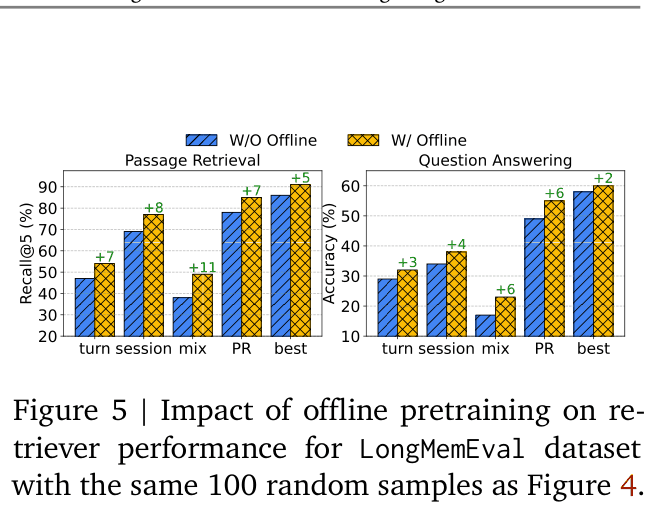
Comparison of different retrieval granularities (turn, session, mixed, PR, best) on LongMemEval.
Main Takeaways
- Topic-based granularity (Prospective Reflection) consistently outperforms fixed turn/session granularity, approaching oracle performance.
- Retrospective Reflection via RL is effective but requires the reranker; directly updating the retriever without a reranker degrades performance due to lack of data/stability.
- Stronger retrievers (GTE/Stella) yield better base performance, but RMM provides consistent gains regardless of the underlying retriever.
- Offline supervised pretraining of the retriever further boosts RMM performance, suggesting complementary benefits.