📝 Paper Summary
Memory organization
Self-evolving Agentic reasoning
Dynamic Cheatsheet improves LLM performance on recurring tasks by maintaining a self-curated, evolving textual memory of strategies and code snippets without modifying model parameters.
Core Problem
LLMs typically process queries in isolation, resetting their context for each new problem, which causes them to repeatedly re-derive solutions or repeat the same mistakes instead of learning from experience.
Why it matters:
- Models fail to carry over successful strategies (like efficient code scripts) to subsequent similar problems, leading to stagnant performance
- Naive approaches like appending full conversation history result in context ballooning and noise, distracting the model rather than helping it
- Current methods to fix this require expensive fine-tuning or static retrieval, which lack the flexibility to adapt on the fly to new test distributions
Concrete Example:
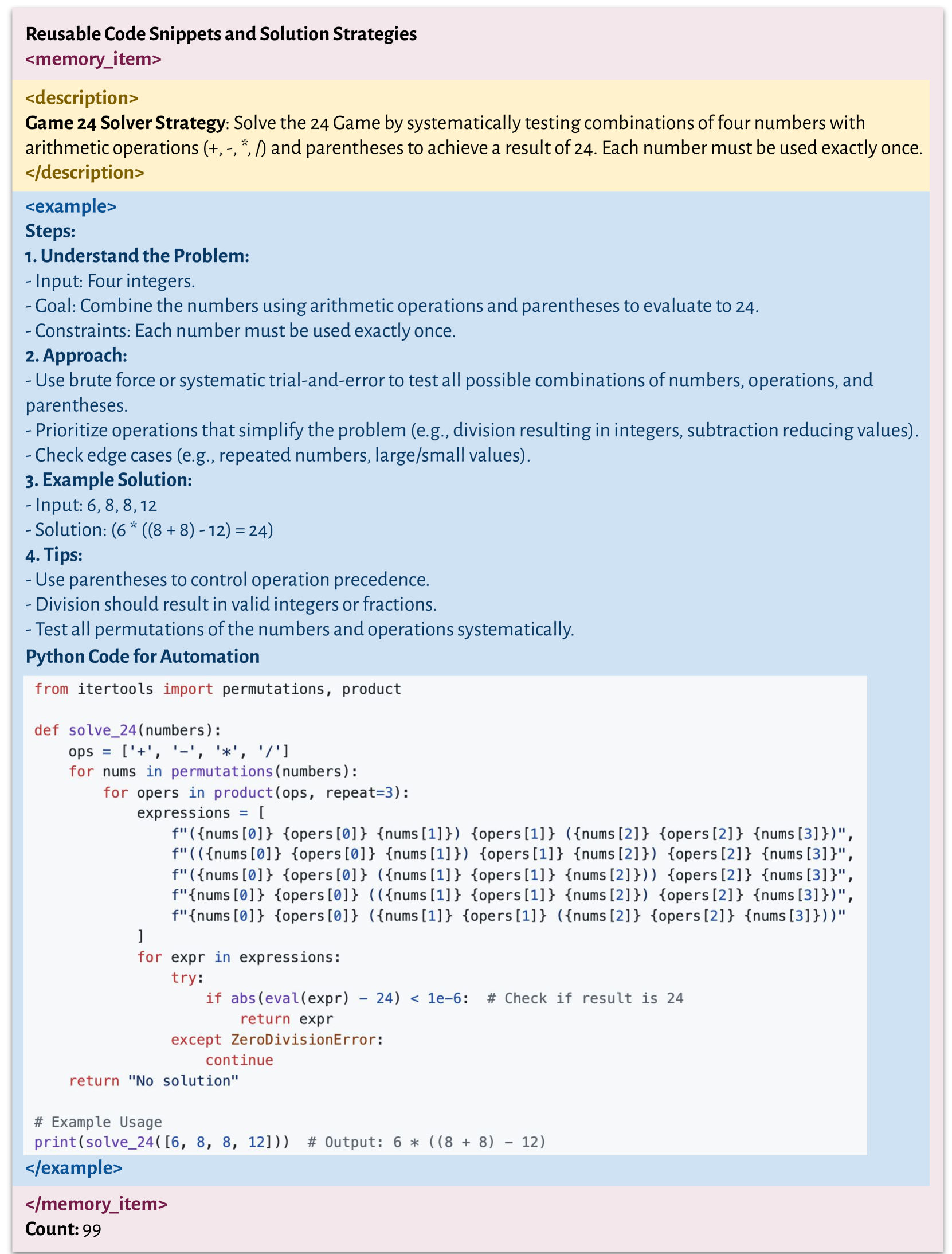
In the 'Game of 24' puzzle, GPT-4o initially fails (10% accuracy) by manually guessing arithmetic combinations. However, once it discovers a Python brute-force script, DC allows it to store this snippet in memory. For all subsequent queries, it simply retrieves and executes the code, jumping to 99% accuracy—something isolated inference never achieves.
Key Novelty
Dynamic Cheatsheet (DC)
- Treats the LLM's context as a mutable 'cheatsheet' that is explicitly curated after every interaction
- Introduces a 'Curator' step that summarizes successful strategies and removes failed ones, preventing context overflow while retaining high-value heuristics
- Enables 'Test-Time Learning' where a frozen model effectively gets smarter over a sequence of tasks by refining its external memory buffer
Architecture
The workflow of the Dynamic Cheatsheet (DC-Cu) framework showing the interaction between the Generator and the Curator.
Evaluation Highlights
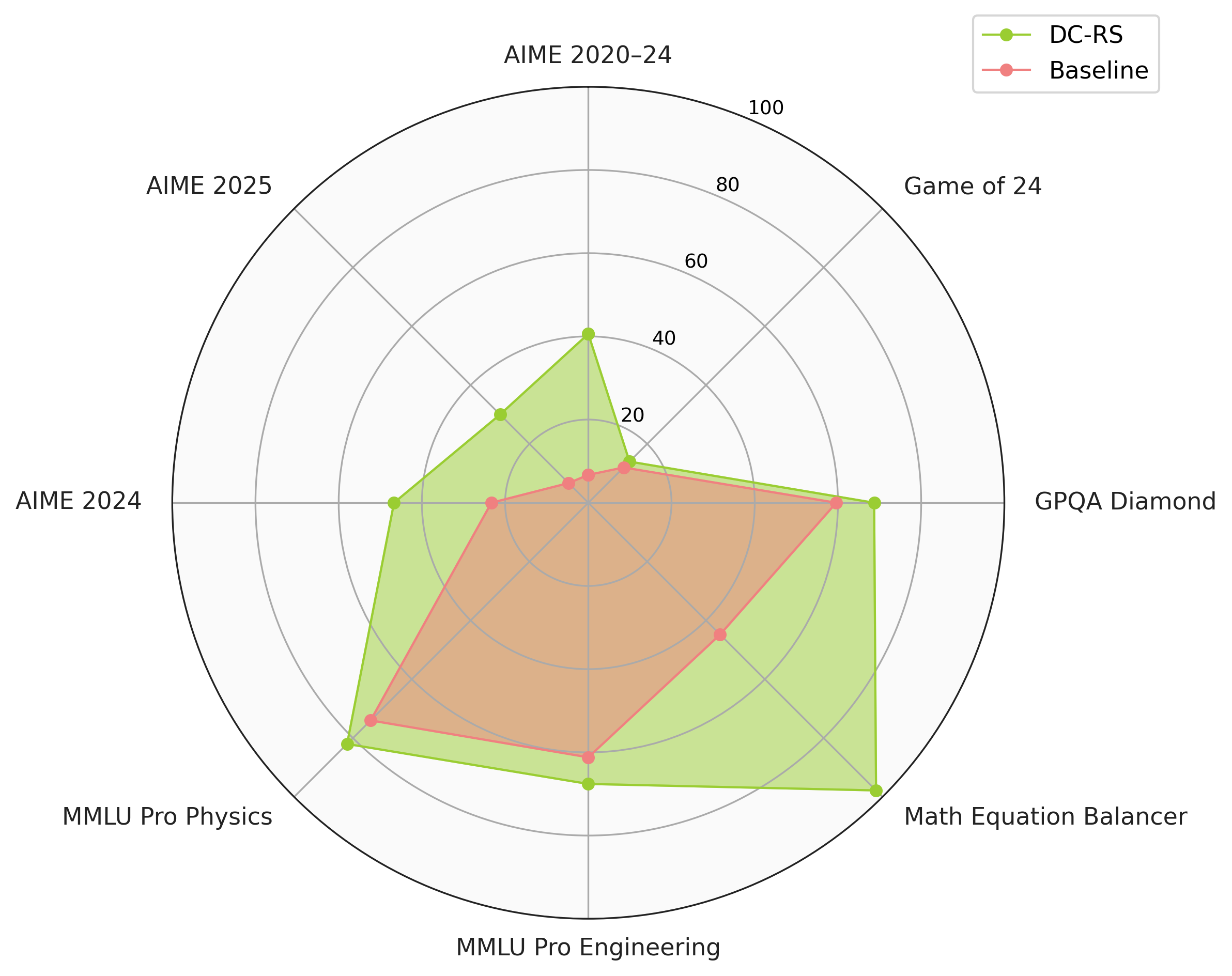
- Accuracy on Game of 24 (GPT-4o) increased from 10% to 99% by retaining a Python solver script
- Claude 3.5 Sonnet's accuracy on AIME 2024 math exams more than doubled (23% to 50%) by accumulating algebraic insights
- Achieved a +9% improvement on GPQA-Diamond (science QA) with Claude 3.5 Sonnet by recalling domain-specific formulas and facts
Breakthrough Assessment
8/10
Demonstrates massive gains on reasoning tasks without parameter updates. The shift from 'stateless inference' to 'stateful, curated memory' is a significant practical advance for deploying agents.