📝 Paper Summary
Hardware-software co-design
Memory bottlenecks in AI
The gap between rapidly growing AI compute requirements and slow-scaling memory bandwidth is creating a critical bottleneck, especially for decoder-only models like GPT.
Core Problem
Hardware compute capabilities (FLOPS) have scaled far faster than memory bandwidth, making memory data transfer the primary bottleneck for modern AI, particularly for generative LLMs.
Why it matters:
- Peak server hardware FLOPS scaled 60,000× over 20 years, while DRAM bandwidth only scaled 100×, creating a massive disparity.
- Decoder models like GPT are increasingly bandwidth-bound due to low arithmetic intensity in auto-regressive generation.
- Scaling model size is becoming exponentially expensive and inefficient if hardware utilization remains limited by memory transfer.
Concrete Example:
Despite having similar model configurations and total FLOPs, GPT-2 inference is significantly slower than BERT-Large because GPT-2's auto-regressive nature involves memory-heavy matrix-vector operations with low arithmetic intensity, whereas BERT uses compute-heavy matrix-matrix operations.
Key Novelty
Comprehensive 'Memory Wall' Analysis for Transformers
- Quantifies the historical divergence between compute scaling (3.0×/2yrs) and bandwidth scaling (1.6×/2yrs) specifically in the context of modern AI hardware.
- Demonstrates via profiling that decoder-only Transformers (GPT) are hit much harder by the memory wall than encoder models (BERT) due to the low arithmetic intensity of token-by-token generation.
Architecture
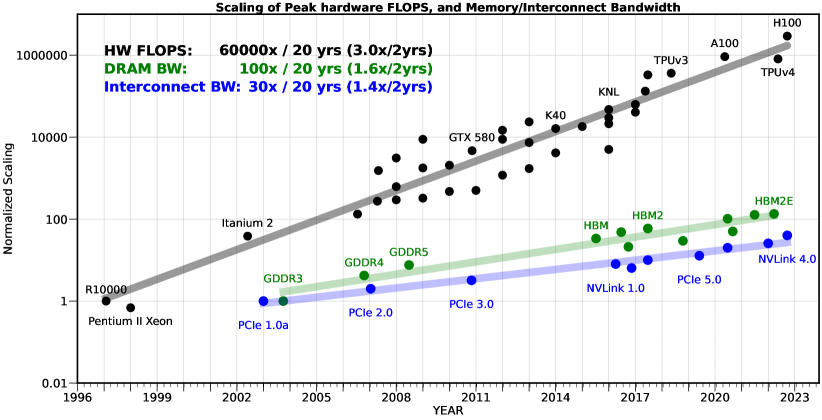
Historical scaling trends of Hardware Peak FLOPS vs. Bandwidth (DRAM & Interconnect) over 20 years.
Evaluation Highlights
- Peak server hardware FLOPS scaled at 3.0×/2yrs over 20 years, while DRAM bandwidth only scaled at 1.6×/2yrs.
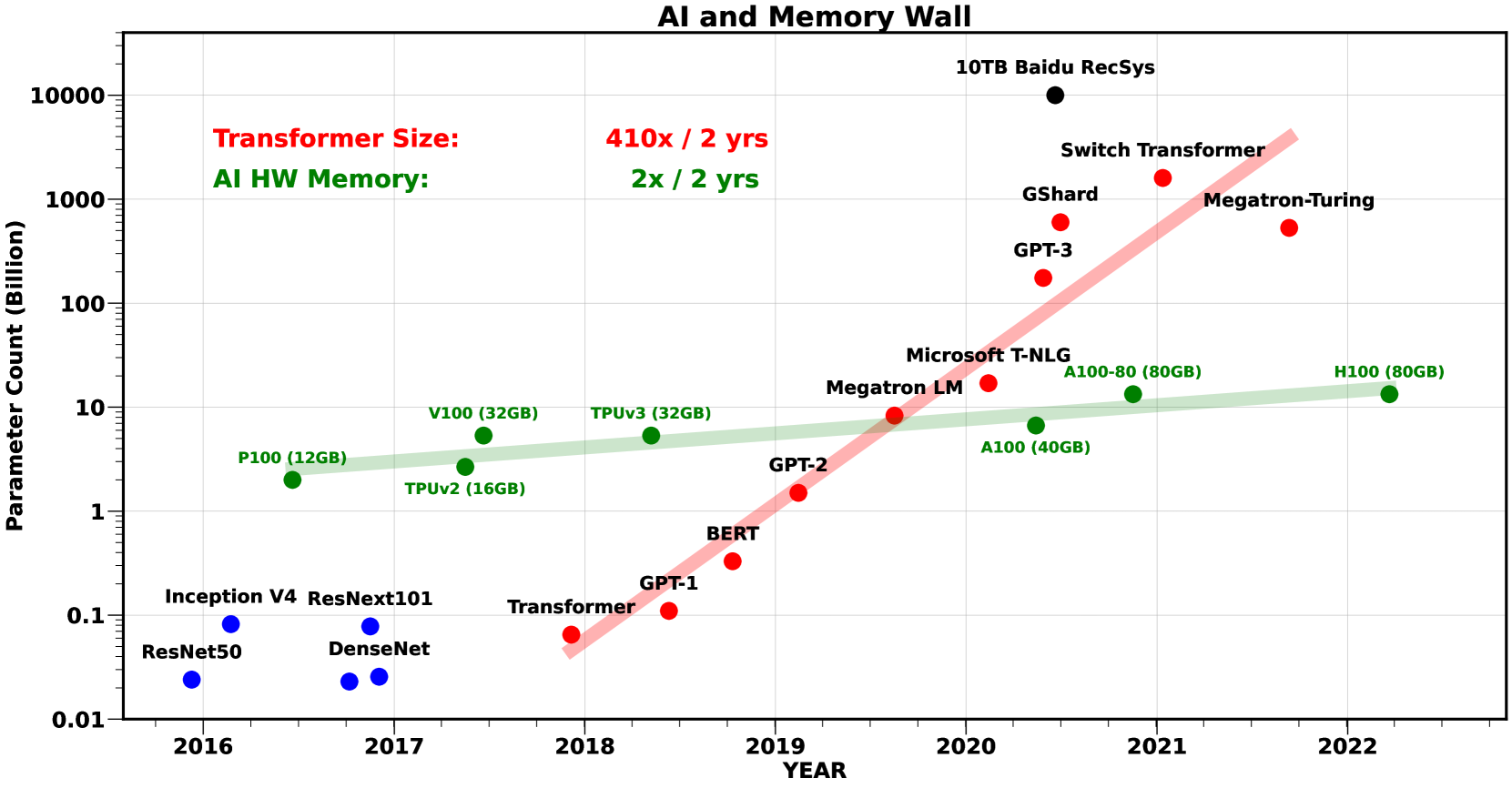
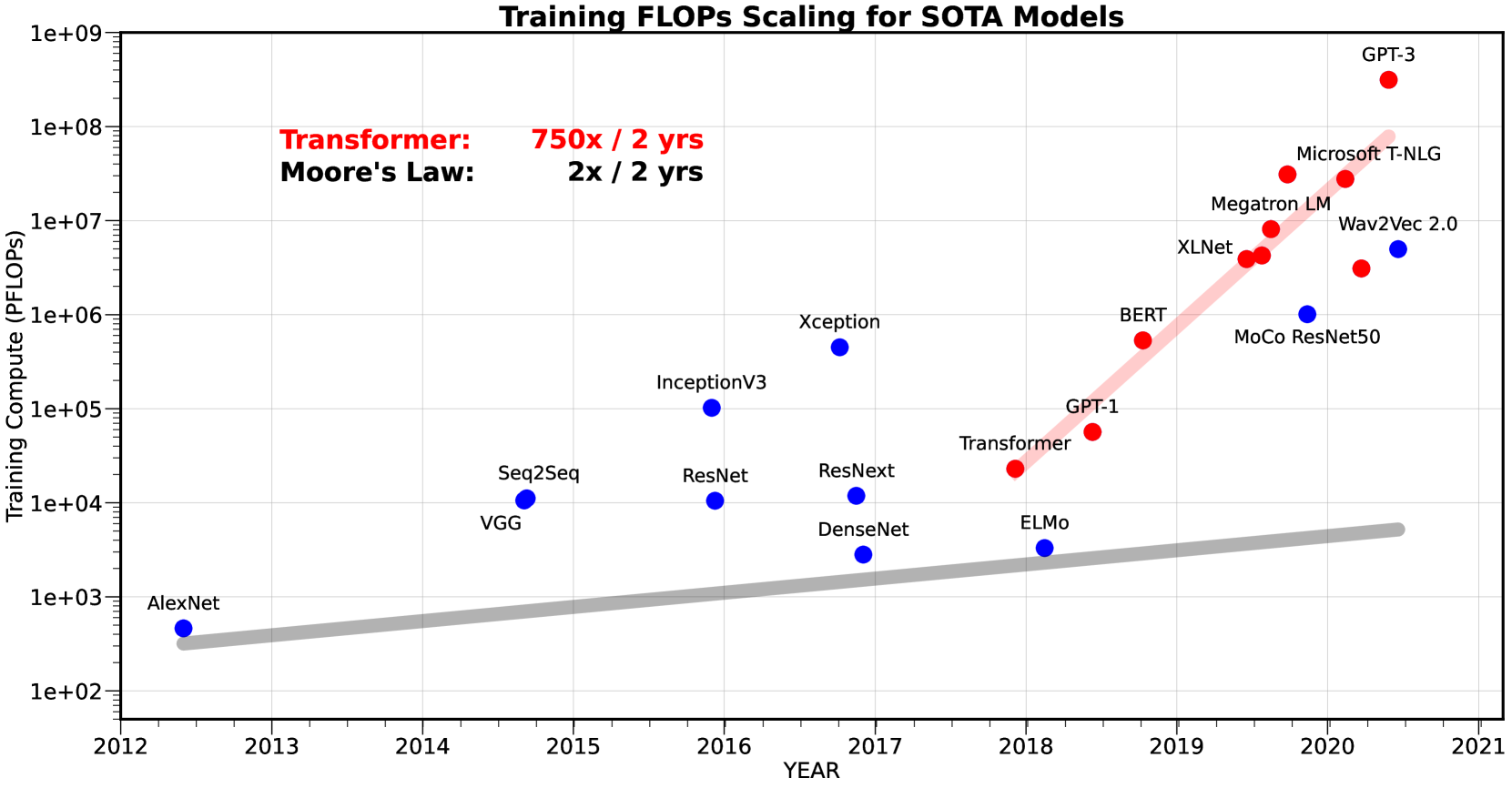
- Training compute for SOTA models grew 750×/2yrs (2018-2022), while model size grew 410×/2yrs, vastly outpacing hardware improvements.
- In profiling, GPT-2 showed significantly higher latency than BERT-Large despite similar FLOP counts, directly attributable to lower arithmetic intensity.
Breakthrough Assessment
8/10
A foundational position paper that quantifies the critical 'Memory Wall' bottleneck for the LLM era, effectively arguing why current scaling laws are unsustainable without architectural shifts.