📝 Paper Summary
Graph-based RAG pipeline
This paper systematically evaluates three KG-RAG methods (RoG, ToG, G-Retriever) by simulating KG incompleteness via random deletion and reasoning path disruption, finding that while they outperform retrieval-free baselines, they are highly sensitive to missing direct evidence.
Core Problem
Existing KG-RAG evaluations typically assume complete Knowledge Graphs (KGs) where answers are directly inferable, failing to reflect real-world scenarios where KGs are often incomplete.
Why it matters:
- KGs in practice are often sparse and missing critical links.
- Current benchmarks do not test whether KG-RAG methods can reason over incomplete data or if they fail brittlely when direct evidence is missing.
Key Novelty
Systematic Robustness Evaluation of KG-RAG under Incompleteness
- Introduces specific deletion strategies: 'Random Triple Deletion' (general sparsity) and 'Reasoning Path Disruption' (targeting critical reasoning chains).
- Assesses whether LLMs can compensate for missing KG links using their internal parametric knowledge or alternative paths.
Architecture
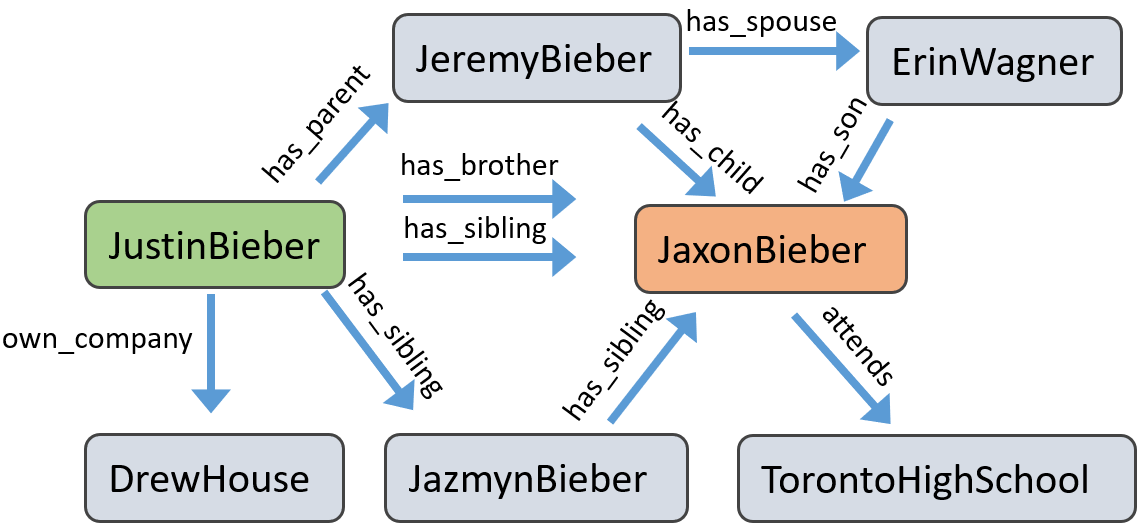
An illustration of the 'Reasoning Path Disruption' concept using Justin Bieber's brother example, showing how removing a direct link forces (or fails to force) the model to use an alternative multi-hop path.
Evaluation Highlights
- RoG on WebQSP: Accuracy drops from 76.75% (no deletion) to 72.15% (20% random deletion) and sharply to 65.43% (-14.7%) under reasoning path disruption.
- ToG on WebQSP: Accuracy drops from 44.19% to 41.61% (20% random deletion) and to 38.25% under reasoning path disruption.
- G-Retriever on WebQSP: Accuracy drops from 53.43% to 50.88% (20% random deletion) and to 49.36% under reasoning path disruption.
- Despite drops, all methods still outperform 'No Retrieval' baselines (e.g., RoG no-retrieval is 50.46%).
- Models often fail to switch to alternative valid reasoning paths when the primary/shortest path is broken.
Breakthrough Assessment
3/10
It is a solid evaluation paper that highlights a weakness in current methods, but it does not propose a new method to solve the problem, serving primarily as a diagnostic study.