📝 Paper Summary
Efficient Vision Transformers
Mobile Vision
EfficientViT accelerates vision transformers by replacing memory-bound attention layers with feed-forward networks in a sandwich layout and decomposing attention heads via cascaded feature splitting to reduce redundancy.
Core Problem
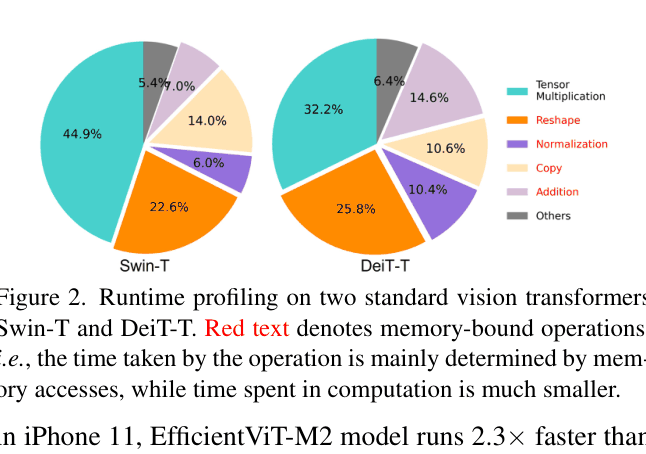
Vision Transformers (ViTs) suffer from slow wall-clock inference speed on edge devices despite low FLOP counts, primarily due to memory access overhead and computational redundancy.
Why it matters:
- High theoretical efficiency (low FLOPs) in existing lightweight ViTs often does not translate to actual speedups on GPUs/CPUs due to memory-bound operations
- Real-time applications (e.g., mobile) require high throughput, but standard ViTs like Swin or DeiT are hindered by frequent tensor reshaping and element-wise functions
- Redundancy in attention maps means compute resources are wasted calculating similar features across different heads
Concrete Example:
In standard Multi-Head Self-Attention (MHSA), all heads process the full input feature, requiring expensive reshaping and copying. The paper shows that reducing MHSA layers (which are memory-bound) to just 20-40% of the network and substituting them with FFNs (Feed Forward Networks) reduces runtime significantly without hurting accuracy.
Key Novelty
Sandwich Layout & Cascaded Group Attention
- Sandwich Layout: Places a single memory-expensive self-attention layer between multiple memory-efficient FFN layers, reducing memory access overhead while maintaining channel communication
- Cascaded Group Attention (CGA): Splits input features into chunks and feeds a different split to each attention head, then cascades the output of one head to the next, reducing redundancy
- Parameter Reallocation: Redistributions parameters based on Taylor pruning analysis, expanding critical value projections while shrinking less important hidden dimensions in FFNs
Architecture
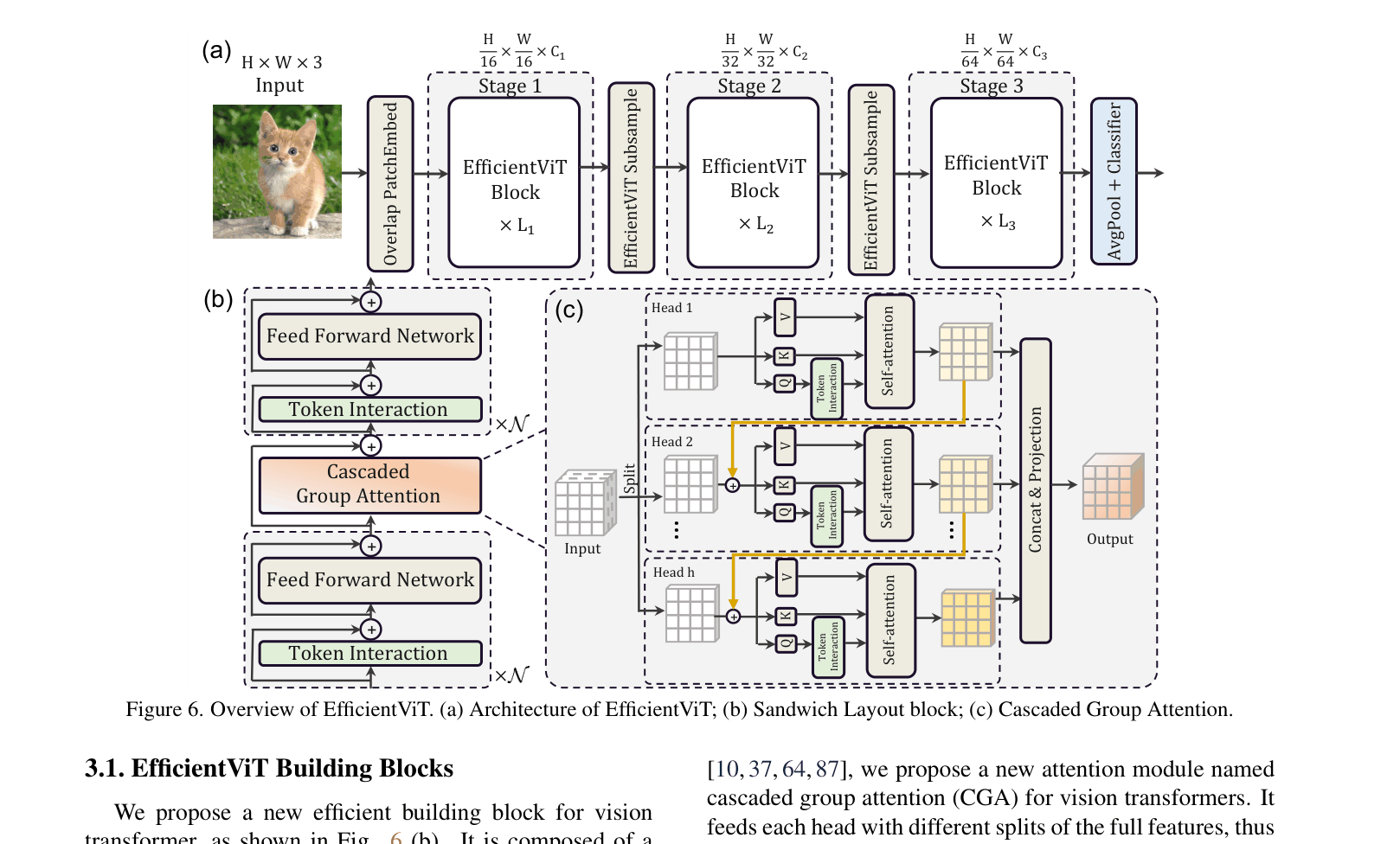
Overview of EfficientViT architecture, the Sandwich Layout block, and Cascaded Group Attention (CGA) module.
Evaluation Highlights
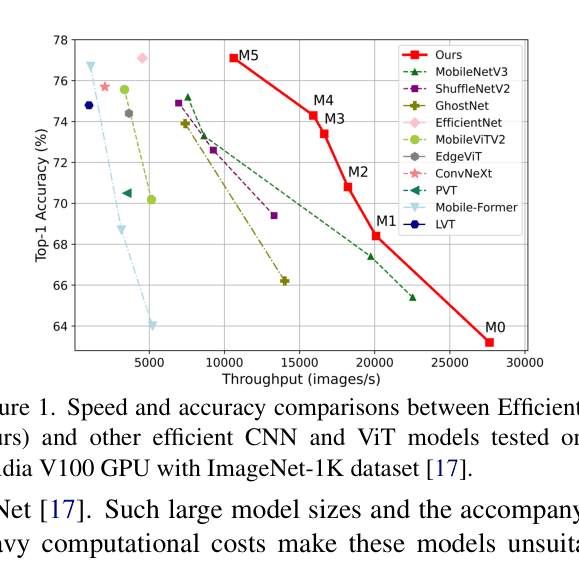
- EfficientViT-M5 achieves 77.1% accuracy on ImageNet-1K, surpassing MobileNetV3-Large by 1.9% while running 40.4% faster on V100 GPU
- EfficientViT-M2 outperforms MobileViT-XXS by 1.8% in accuracy while running 5.8x faster on V100 GPU and 3.7x faster on Intel Xeon CPU
- Converted to ONNX format, EfficientViT-M2 runs 7.4x faster than MobileViT-XXS on CPU
Breakthrough Assessment
7/10
Strong engineering contribution. While the components (group conv concepts applied to attention) are evolutionary, the systematic analysis of memory-bound bottlenecks and the resulting speed/accuracy Pareto frontier shift are significant for practical deployment.