📝 Paper Summary
Robotic Manipulation
Visual Foundation Models
Memory-based Policy Learning
SAM2Act integrates Segment Anything 2 features into a robotic transformer for precise manipulation, while SAM2Act+ adds a memory bank to solve tasks requiring recall of past observations.
Core Problem
Robotic policies often fail at tasks requiring spatial memory because they rely on the Markov assumption (current observation is sufficient), and standard visual encoders struggle with precise generalization.
Why it matters:
- Many real-world tasks (e.g., cooking, cleaning) require remembering past states (e.g., 'Did I already add salt?') rather than just reacting to the current view.
- Existing 3D manipulation models (PerAct, RVT) lack explicit memory mechanisms, forcing them to guess randomly when the current scene is visually ambiguous regarding past actions.
- Standard benchmarks (RLBench) do not isolate or stress-test spatial memory, masking the inability of agents to perform long-horizon tasks dependent on history.
Concrete Example:
In the 'reopen_drawer' task, a robot must open a specific drawer, close it, press a button (resetting the scene), and then reopen the *same* drawer. Since all drawers look identical after closing, a memory-less agent cannot know which one to reopen and fails, whereas a human remembers the location.
Key Novelty
SAM2Act+ (Memory-Augmented Multi-View Transformer)
- Leverages SAM2 (Segment Anything 2) image embeddings via a 'Multi-Resolution Upsampling' module to inject rich, object-centric visual features into a coarse-to-fine robotic policy.
- Introduces explicit memory components (Memory Bank, Encoder, Attention) into the policy's coarse branch, allowing the robot to condition current actions on features stored from previous timesteps.
- Proposes MemoryBench, a suite of tasks specifically designed to violate the Markov property, forcing agents to rely on history rather than just current visual input.
Architecture
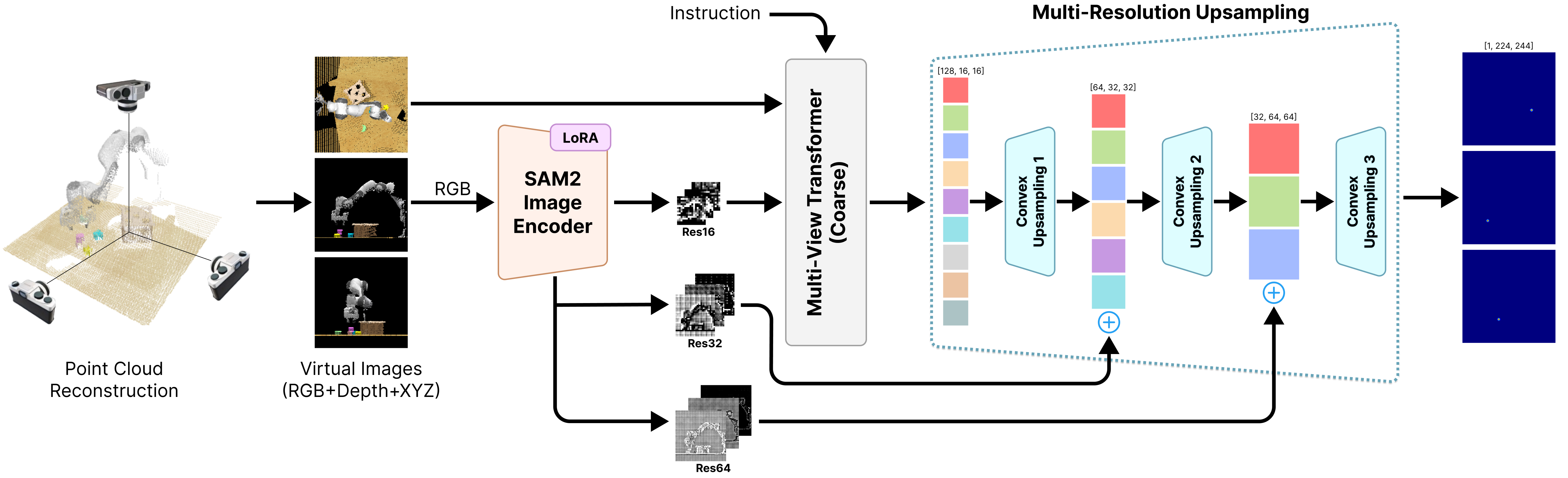
The integration of SAM2 into the RVT backbone (Fig 4) and the memory-augmented SAM2Act+ architecture (Fig 3).
Evaluation Highlights
- SAM2Act achieves 86.8% average success rate across 18 RLBench tasks, establishing a new state-of-the-art.
- SAM2Act+ achieves 94.3% success on MemoryBench tasks, outperforming the next best baseline by a massive margin of 39.3%.
- Demonstrates robust generalization on The Colosseum benchmark with only a 4.3% performance drop under environmental perturbations.
Breakthrough Assessment
9/10
Introduces a highly effective memory architecture for manipulation that solves a critical deficiency (spatial memory) in prior SOTA methods like RVT, with convincing results on a new, targeted benchmark.