📝 Paper Summary
Robotic Manipulation
Vision-Language-Action (VLA) Models
Memory Systems in Robotics
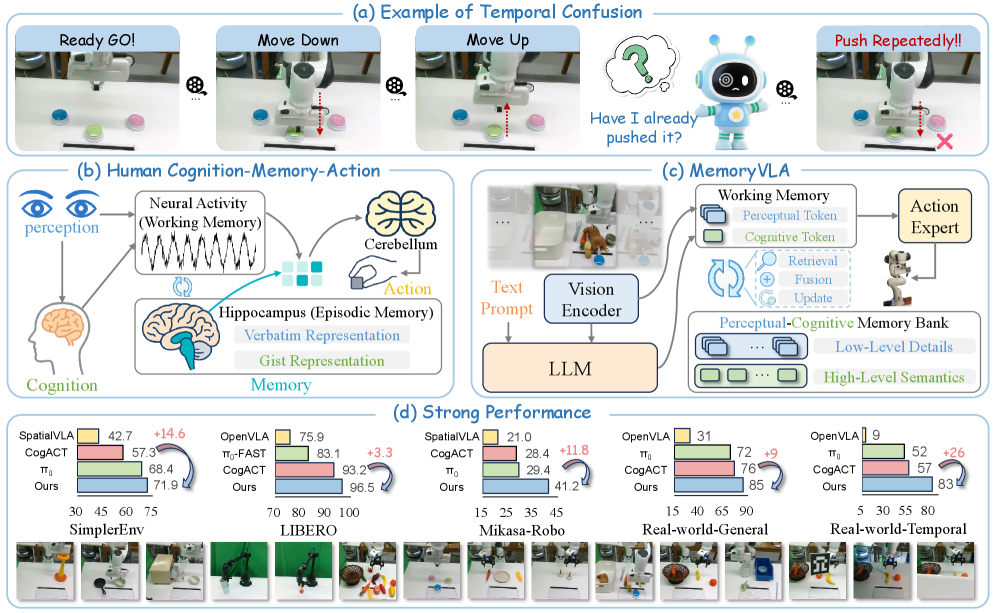
MemoryVLA integrates a dual-stream memory bank (storing both fine-grained visual details and high-level semantics) into a diffusion-based control policy to enable robots to solve long-horizon, non-Markovian tasks.
Core Problem
Mainstream VLA models rely on single-frame observations, failing to capture temporal dependencies required for non-Markovian tasks where past actions determine current state.
Why it matters:
- Many manipulation tasks are visually ambiguous without history (e.g., a button looks the same before and after pressing), leading to execution failures.
- Naive solutions like concatenating frame histories are computationally expensive (quadratic attention complexity) and misaligned with single-frame pretraining paradigms.
- Current state-of-the-art models like OpenVLA and pi0 struggle significantly with long-horizon tasks due to this lack of explicit temporal modeling.
Concrete Example:
In a 'Push Buttons' task (Fig. 1a), the visual observation of a button is identical before and after the push. Without memory of the 'push' action occurring, a standard VLA cannot determine if the sub-goal is complete, leading it to repeat the action or stall.
Key Novelty
Perceptual-Cognitive Memory Bank (PCMB) with Consolidation
- Maintains a dual-stream external memory: 'Perceptual' stream for fine-grained visual details and 'Cognitive' stream for high-level semantic summaries derived from a VLM.
- Mimics biological memory consolidation by merging temporally adjacent and semantically similar entries when the buffer is full, preserving essential history without memory bloat.
- Uses a 'Working Memory' (current frame tokens) to query the long-term PCMB, retrieving and fusing only decision-relevant historical context via a gating mechanism.
Architecture
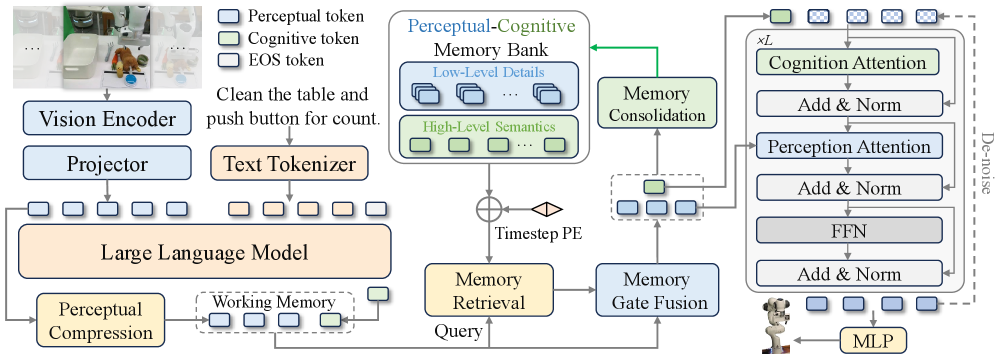
The end-to-end framework of MemoryVLA, detailing the flow from observation to action via the memory bank.
Evaluation Highlights
- +26% improvement over CogACT on real-world long-horizon temporal tasks (83% vs 57%), demonstrating superior temporal reasoning.
- Achieves 96.5% success rate on the LIBERO simulation benchmark, outperforming both CogACT and pi0.
- Outperforms pi0 by +11.8 points on the challenging Mikasa-Robo benchmark (41.2% vs 29.4%).
Breakthrough Assessment
8/10
Strong conceptual novelty in applying cognitive science memory theories (dual-store, consolidation) to VLA architectures. Demonstrates significant empirical gains on long-horizon tasks against top-tier baselines like pi0.