📝 Paper Summary
Memory recall
Memory organization
LongMemEval benchmarks chat assistants on long-term memory abilities using generated chat histories, revealing significant deficits in current systems and demonstrating that specific indexing and retrieval optimizations can restore performance.
Core Problem
Current chat assistants and benchmarks fail to realistically model long-term memory, often ignoring task-oriented dialogues, memory updates, and temporal reasoning over extended timelines.
Why it matters:
- Failing to incorporate user background and preferences diminishes response accuracy and user satisfaction in long-term interactions
- Existing benchmarks use short, non-configurable contexts or focus on human-human conversations, missing the complexity of dynamic user-AI interactions
- Current commercial systems (e.g., ChatGPT, Coze) struggle to maintain consistency or recall indirectly provided information over long periods
Concrete Example:
In a pilot study, ChatGPT tended to overwrite crucial user information as the chat continued, while Coze often failed to record indirectly provided user details. Long-context LLMs reading the full history suffered a 30-60% performance drop compared to oracle settings.
Key Novelty
LongMemEval Benchmark & Unified Memory Framework
- A 'needle-in-a-haystack' style benchmark specifically for chat assistants, embedding answer evidence within hundreds of task-oriented sessions involving memory updates and temporal reasoning
- A unified framework proposing optimizations: decomposing history into rounds (granular units), augmenting index keys with extracted facts, and expanding retrieval queries with time-aware constraints
Architecture
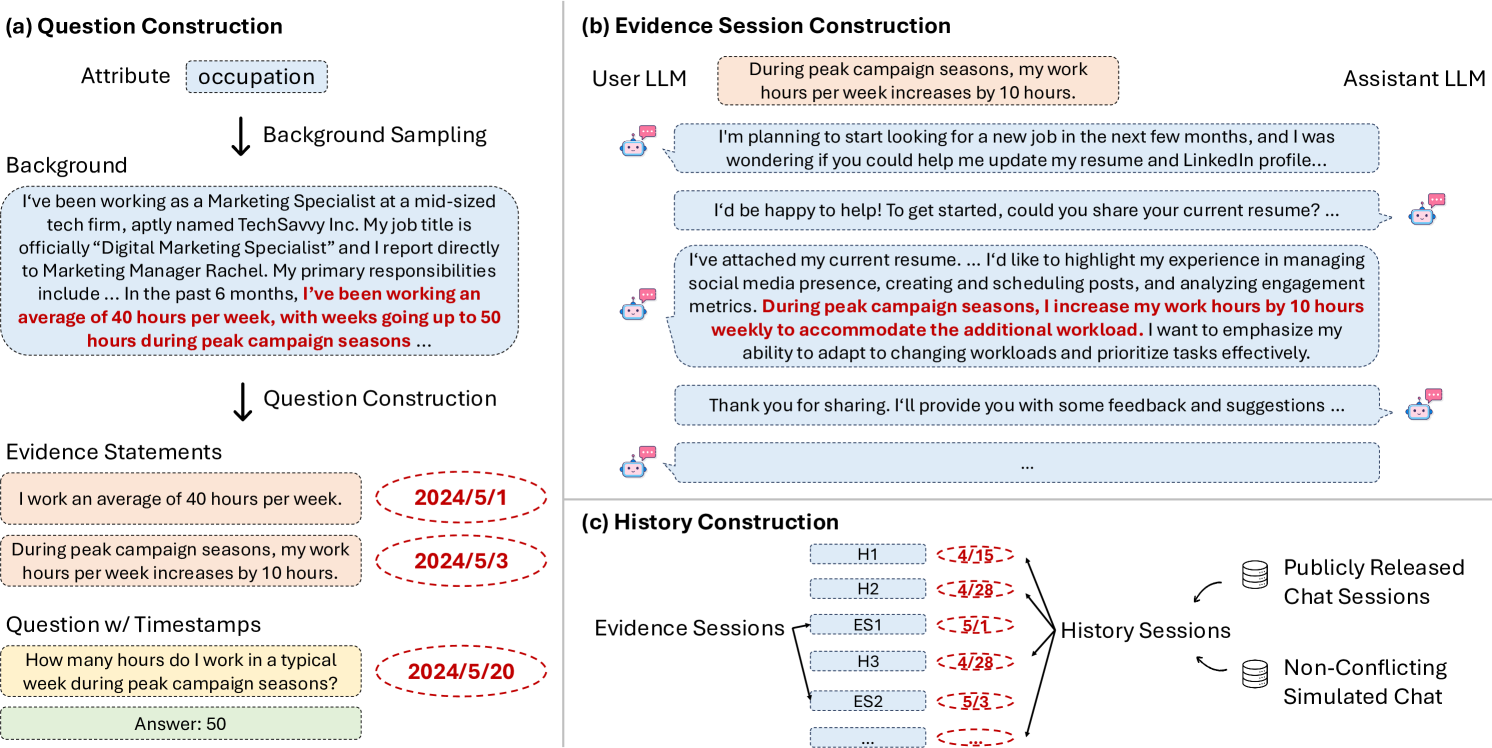
The data construction pipeline and implicitly the structure of the memory challenge. It shows how user attributes are converted to evidence sessions and embedded into a needle-in-a-haystack history.
Evaluation Highlights
- Fact-augmented key expansion improves memory recall@k by 9.4% and downstream question answering accuracy by 5.4%
- Time-aware query expansion improves recall for temporal reasoning questions by 6.8% to 11.3% when using a strong LLM
- State-of-the-art commercial systems and long-context LLMs show a 30% to 60% accuracy drop on LongMemEval compared to oracle retrieval baselines
Breakthrough Assessment
8/10
Provides a critical, realistic benchmark for a major LLM capability (long-term memory) and offers concrete, empirically validated architectural improvements.