📝 Paper Summary
World Simulation
Long-term Video Generation
Visual Memory
WorldMem achieves consistent long-term world simulation by augmenting autoregressive video generation with an external token-level memory bank and state-aware attention to retrieve and reconstruct past scenes.
Core Problem
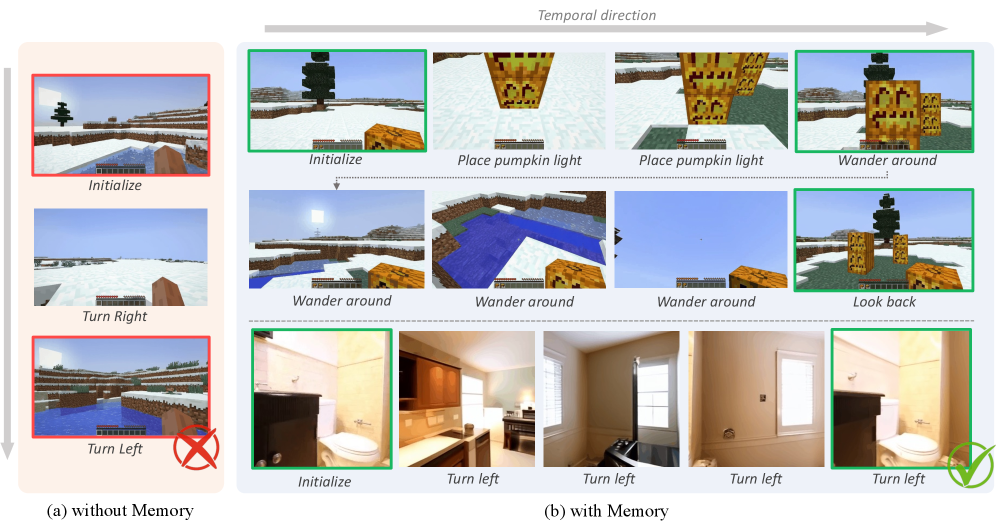
Video generative models suffer from limited context windows, causing 'amnesia' where the model hallucinates inconsistent details when revisiting previously generated locations (e.g., a room layout changes upon return).
Why it matters:
- Autonomous agents training in simulated worlds require permanence; if the world shifts when the camera turns away, navigation and planning policies fail to generalize to reality.
- Traditional 3D reconstruction is rigid and struggles with dynamic environments, while pure video generation lacks the long-term coherence needed for extended simulations.
Concrete Example:
In a Minecraft simulation, if an agent builds a structure, walks away until the structure leaves the context window, and then returns, standard video diffusion models will generate a completely different terrain or missing structure because the original frames were discarded.
Key Novelty
State-Aware Token Memory Bank
- Maintains an external bank of compressed visual tokens paired with explicit state cues (3D pose, timestamp) to extend the model's horizon beyond its active context window.
- Uses 'State-Aware Attention' where the generation process attends to memory tokens modulated by their spatial and temporal embeddings, enabling geometric reasoning (reprojecting past views) without explicit 3D reconstruction.
Architecture
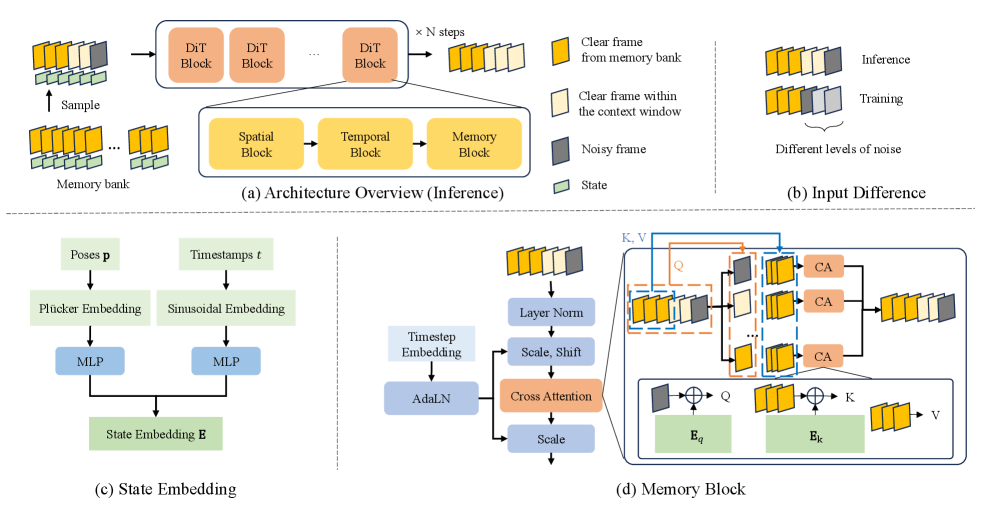
The overall WorldMem pipeline including the memory retrieval process and the conditional Diffusion Transformer architecture.
Evaluation Highlights
- +11.15 dB PSNR improvement over Diffusion Forcing baseline on Minecraft 'Beyond Context' evaluation (revisiting scenes after 600 frames).
- Outperforms ViewCrafter by +2.61 dB PSNR on RealEstate10K long-trajectory generation (37-60 frames), demonstrating superior consistency in real-world scenes.
- Reduces perceptual error (LPIPS) by 77% compared to Diffusion Forcing in long-term Minecraft simulation (0.08 vs 0.35).
Breakthrough Assessment
8/10
Significant jump in long-term consistency for video generation without relying on expensive explicit 3D reconstruction. The ability to recall scenes from 600 frames ago with high fidelity addresses a major bottleneck in world models.