📝 Paper Summary
Memory organization
Agentic AI
MemAgent enables LLMs to process effectively infinite context with linear complexity by using reinforcement learning to train a policy that iteratively compresses text chunks into a fixed-size memory.
Core Problem
Processing extremely long contexts (e.g., books, long-term agent memory) with standard Transformers incurs quadratic computational costs and performance degradation when extrapolating beyond training limits.
Why it matters:
- Existing length extrapolation methods suffer from performance drops and slow processing speeds due to O(n^2) complexity on extremely long text
- Sparse and linear attention mechanisms often require training from scratch or rely on rigid, human-defined patterns
- Context compression approaches typically struggle with extrapolation and require external modules that disrupt standard generation processes
Concrete Example:
When a standard LLM reads a 4 million token document, the attention mechanism becomes prohibitively expensive. MemAgent instead reads the document in segments, updating a small 'memory' note after each segment, similar to a human taking stenographic notes.
Key Novelty
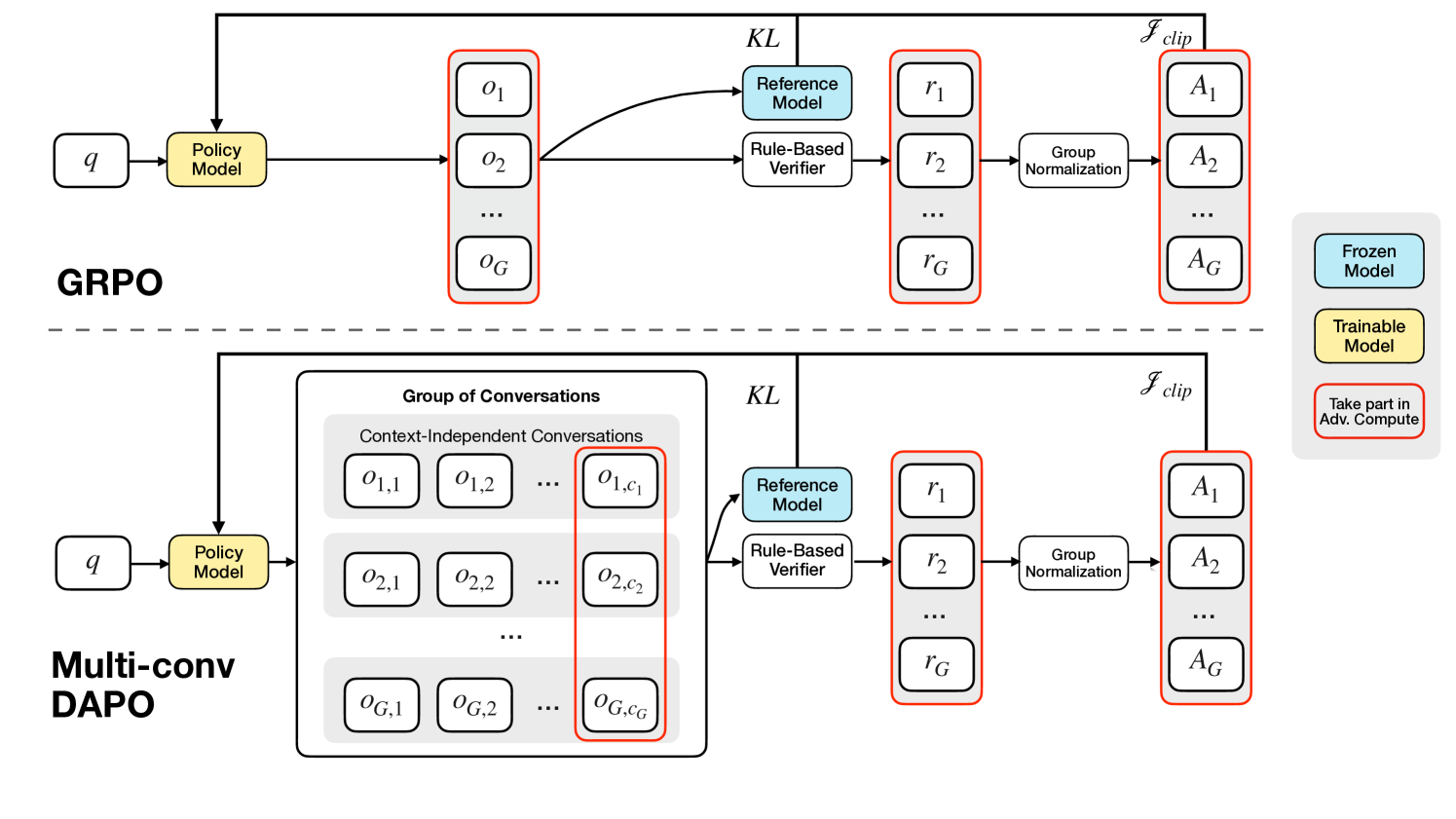
Reinforcement Learning-driven Memory Overwrite Mechanism
- Treats memory updates not as appending to a log, but as an 'overwrite' action where the model decides what to keep or discard from a fixed-size buffer
- Uses Multi-Conversation Reinforcement Learning to train the model to retain answer-critical information purely from outcome rewards (correct final answers), without human annotations for the memory content itself
Architecture
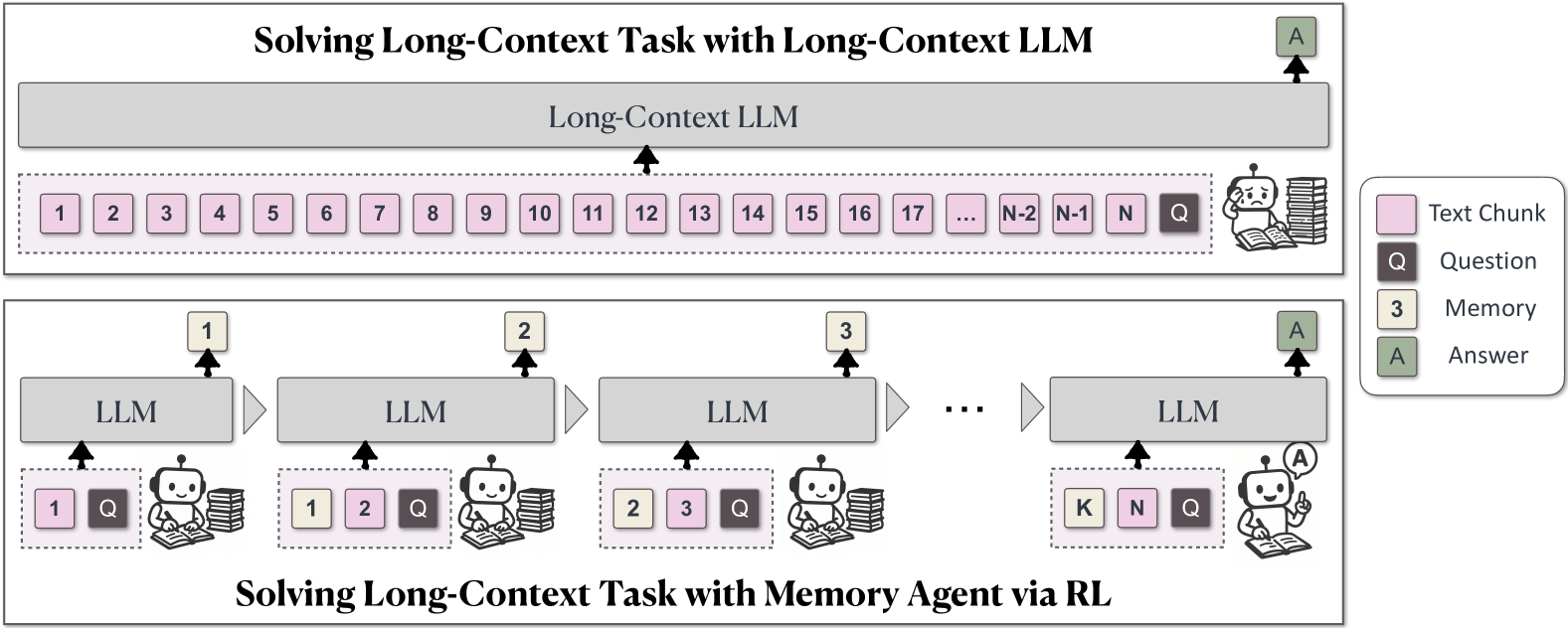
The MemAgent workflow showing the segment-by-segment processing stream.
Evaluation Highlights
- Achieves >95% accuracy on the 512K token RULER benchmark
- Extrapolates from an 8K training context to 3.5M token QA tasks with <5% performance loss
- Maintains strictly linear O(N) computational complexity and constant memory usage per step regardless of input length
Breakthrough Assessment
9/10
Proposes a fundamental shift from attention-based context extension to RL-based memory compression, achieving linear scaling for infinite context without architectural changes to the base LLM.