📝 Paper Summary
Long-term conversational memory
Multi-modal dialogue generation
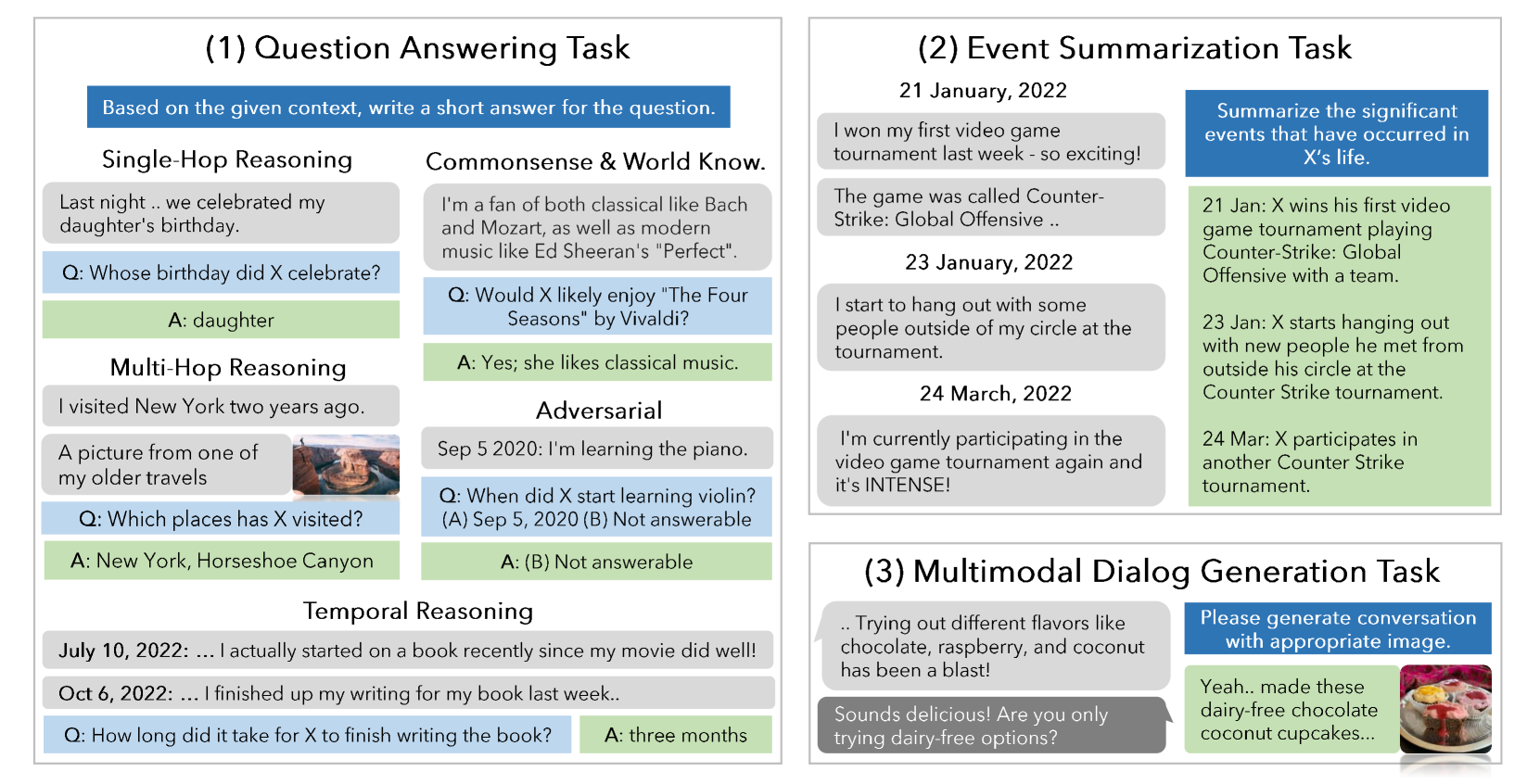
The paper introduces LoCoMo, a dataset and benchmark for very long-term multi-modal dialogue, generated via a human-machine pipeline to evaluate how well agents maintain consistency over simulated months.
Core Problem
Existing open-domain dialogue studies are limited to short contexts (approx. 5 sessions) and fail to evaluate an agent's ability to maintain consistency, empathy, and causal reasoning over very long timeframes.
Why it matters:
- Real-world relationships evolve over months/years, requiring chatbots to recall distant past interactions to be truly engaging and useful
- Current evaluation metrics (lexical overlap) do not measure long-term comprehension or temporal reasoning capabilities
- RAG (Retrieval-Augmented Generation) and long-context LLMs have not been rigorously tested on effectively handling months of conversational history
Concrete Example:
In a 35-session dialogue, if a user references an event from Session 2 (months ago in simulation), current models often hallucinate or fail to retrieve the correct detail due to the dense, noisy history.
Key Novelty
Machine-Human Generation Pipeline for Long-Term Memory (LoCoMo)
- Utilizes a pipeline where LLM agents generate dialogues grounded in pre-constructed 'Temporal Event Graphs' (causally linked life events) to ensure narrative consistency
- Integrates multi-modal capabilities by allowing agents to share and react to images via a search-and-caption mechanism
- Employs human annotators to verify grounding and fix long-range inconsistencies, resulting in a dataset significantly longer (300 turns avg.) than prior benchmarks
Architecture
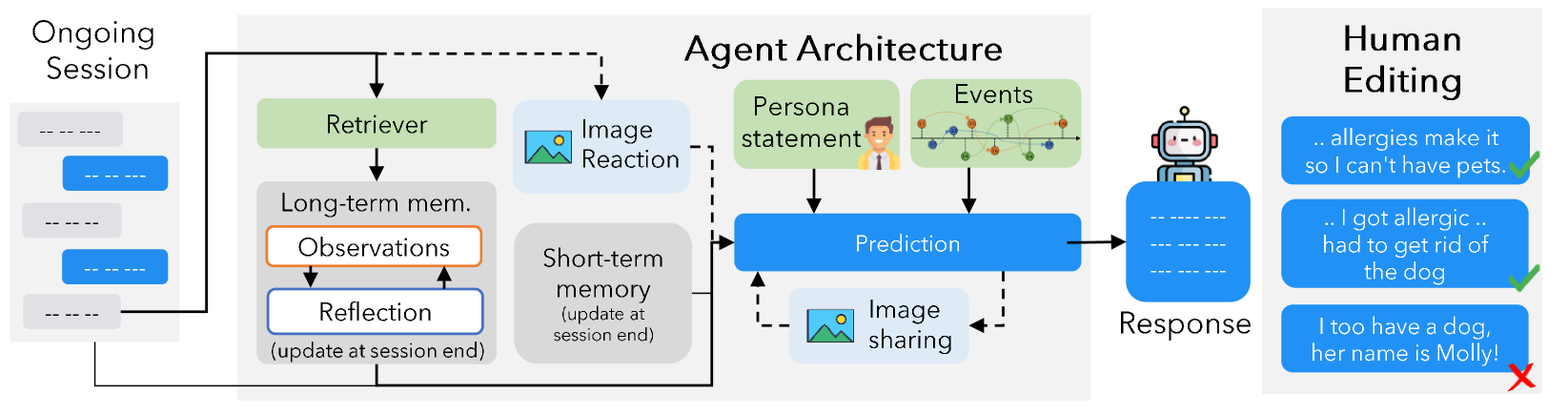
The Machine-Human Pipeline for generating the LoCoMo dataset.
Evaluation Highlights
- Long-context LLMs lag behind human performance by 56% in memory QA tasks despite context window improvements
- In temporal reasoning tasks, model performance lags behind humans by 73%, showing a failure to grasp causal dynamics
- Long-context models perform 83% worse on adversarial questions compared to base models, indicating high susceptibility to hallucination in long contexts
Breakthrough Assessment
8/10
Significant contribution to the field by providing a much-needed benchmark for *very* long-term memory (months vs days), revealing severe limitations in current SOTA methods.