📝 Paper Summary
RNN scaling
Efficient sequence modeling
xLSTM revitalizes the LSTM architecture by introducing exponential gating and a matrix memory structure, enabling parallelization and scaling to large language modeling tasks competitive with Transformers.
Core Problem
Original LSTMs suffer from inability to revise storage decisions, limited scalar memory capacity for rare tokens, and lack of parallelizability due to sequential memory mixing.
Why it matters:
- Standard LSTMs cannot compete with Transformers at scale due to sequential processing bottlenecks and memory compression issues
- Transformers have quadratic complexity in context length, creating a need for linear-complexity alternatives that still maintain high performance
- Current linear attention and SSM approaches often lack the state tracking capabilities provided by explicit memory mixing in RNNs
Concrete Example:
In a Nearest Neighbor Search task, a standard LSTM struggles to revise a stored value when a more similar vector appears later in the sequence (high MSE), whereas xLSTM can overwrite the value using exponential gating.
Key Novelty
xLSTM (Extended LSTM) with sLSTM and mLSTM blocks
- Introduces exponential gating (replacing sigmoid) to allow sharper focus and the ability to revise storage decisions (exponential decay/update)
- Expands memory from scalar to matrix form (mLSTM) using a covariance update rule (outer product of key-value), enabling high-capacity storage similar to key-value pairs in Transformers
- Eliminates hidden-hidden connections in the matrix memory variant (mLSTM) to enable fully parallelizable training via matrix operations
Architecture
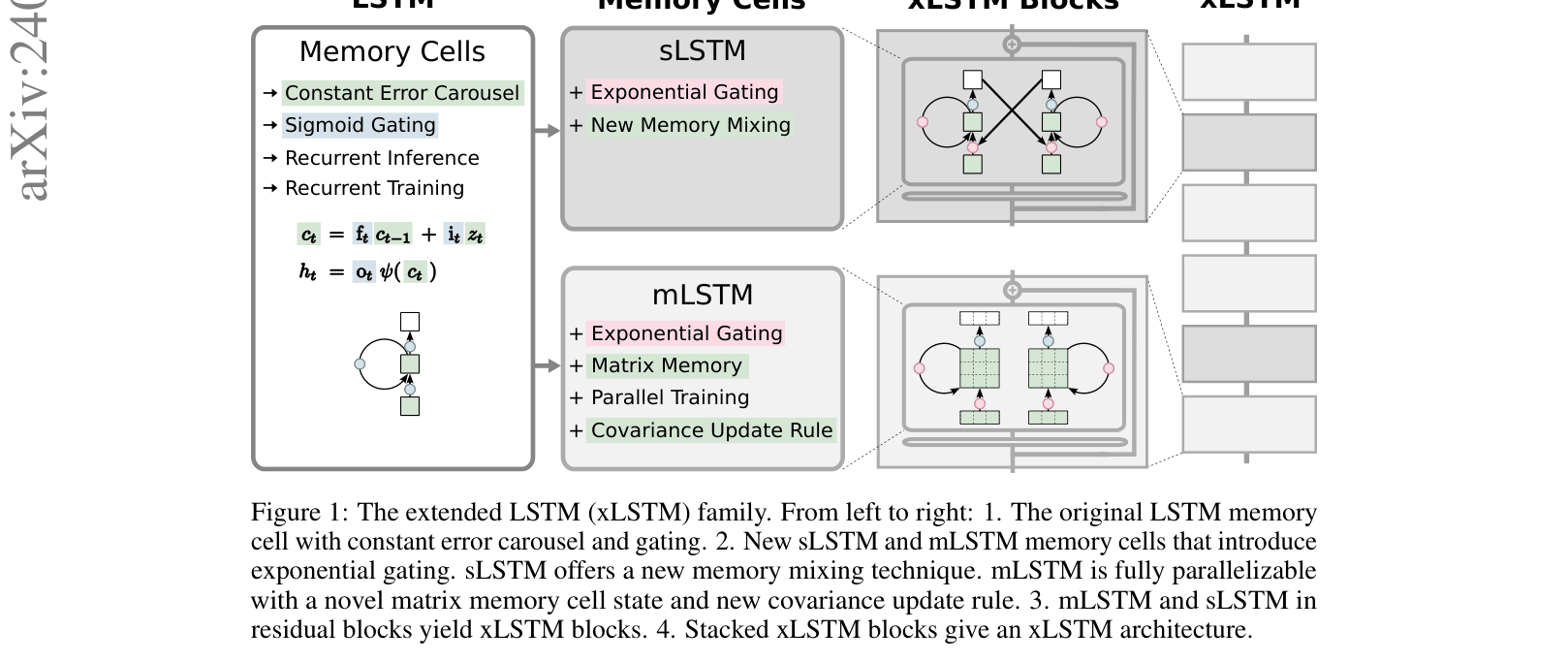
Evolution from original LSTM to xLSTM architecture. Shows the original cell, the new sLSTM and mLSTM cells, the residual blocks, and the stacked architecture.
Evaluation Highlights
- xLSTM[1:0] achieves 13.43 validation perplexity on SlimPajama (15B tokens), outperforming Mamba (13.70) and Llama (14.25) at comparable ~400M parameter sizes
- In length extrapolation tests (training on 2k, testing up to 16k), 1.3B xLSTM models maintain low perplexity (~8.92-9.01) while Llama degrades significantly (337.83)
- xLSTM[1:0] achieves lower perplexity than Mamba on 568 out of 571 (99.5%) text domains in the PALOMA benchmark
Breakthrough Assessment
9/10
Successfully modernizes the LSTM to be parallelizable and scalable, outperforming strong baselines like Mamba and Llama on language modeling tasks while retaining linear complexity.