📝 Paper Summary
Memory-Efficient Training
Parameter-Efficient Fine-Tuning (PEFT)
GaLore reduces memory usage by projecting weight gradients into a low-rank form for the optimizer while keeping the main model weights full-rank, enabling 7B model training on consumer GPUs.
Core Problem
Training LLMs requires massive memory for optimizer states (often 2-3x the model size), making pre-training impossible on consumer hardware. Existing solutions like LoRA restrict the parameter search space, hurting pre-training performance.
Why it matters:
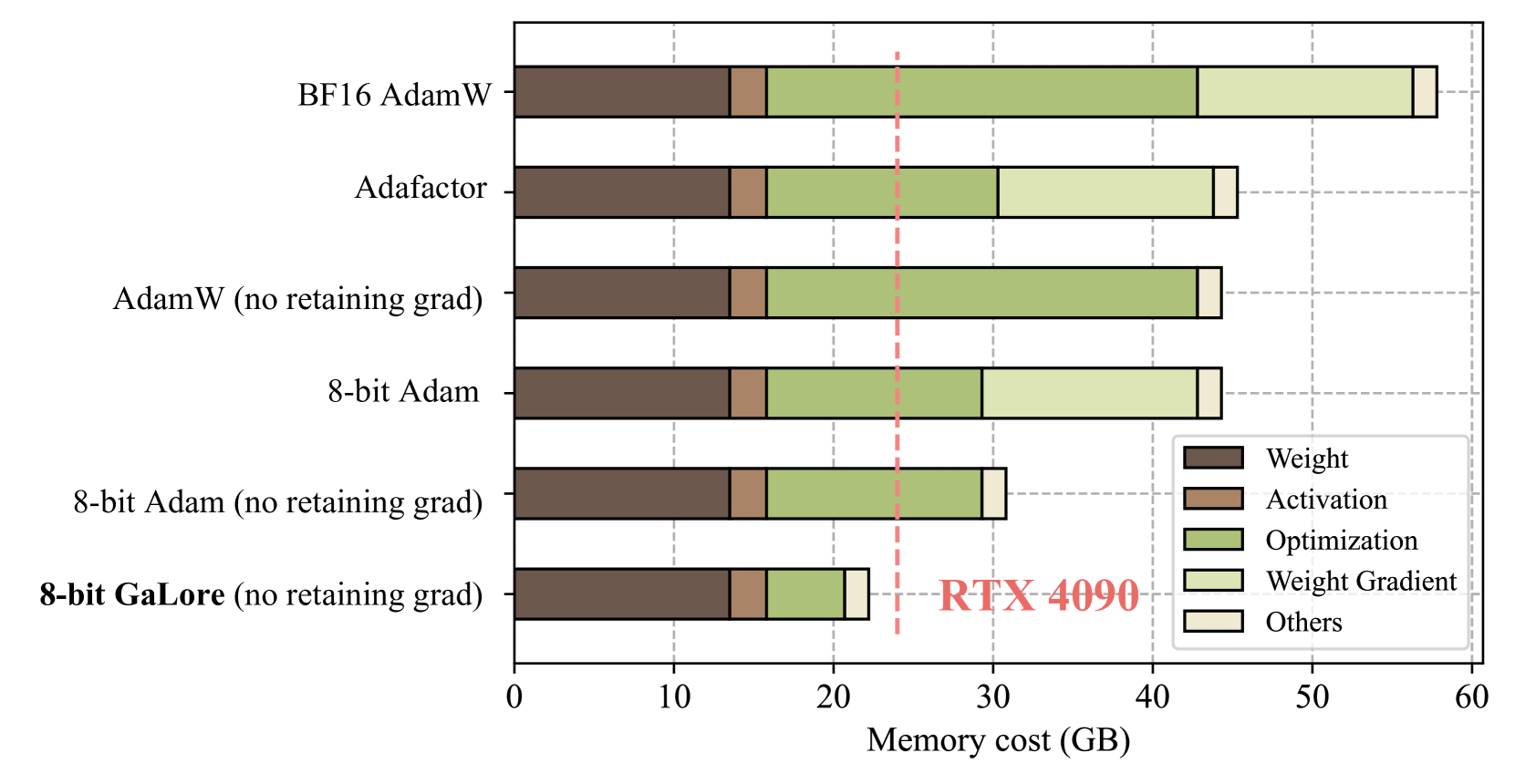
- Pre-training a LLaMA 7B model typically requires ~58GB of memory (14GB weights + 42GB optimizer states), exceeding the 24GB capacity of consumer GPUs like the RTX 4090.
- Low-rank adaptation methods (LoRA) change training dynamics and often underperform full-rank training or require a full-rank warm-up phase.
Concrete Example:
Training a 7B parameter model with Adam requires storing momentum and variance matrices matching the model size. On a 24GB NVIDIA RTX 4090, this causes Out-Of-Memory errors immediately, whereas GaLore compresses these states to fit within memory.
Key Novelty
Gradient Low-Rank Projection (GaLore)
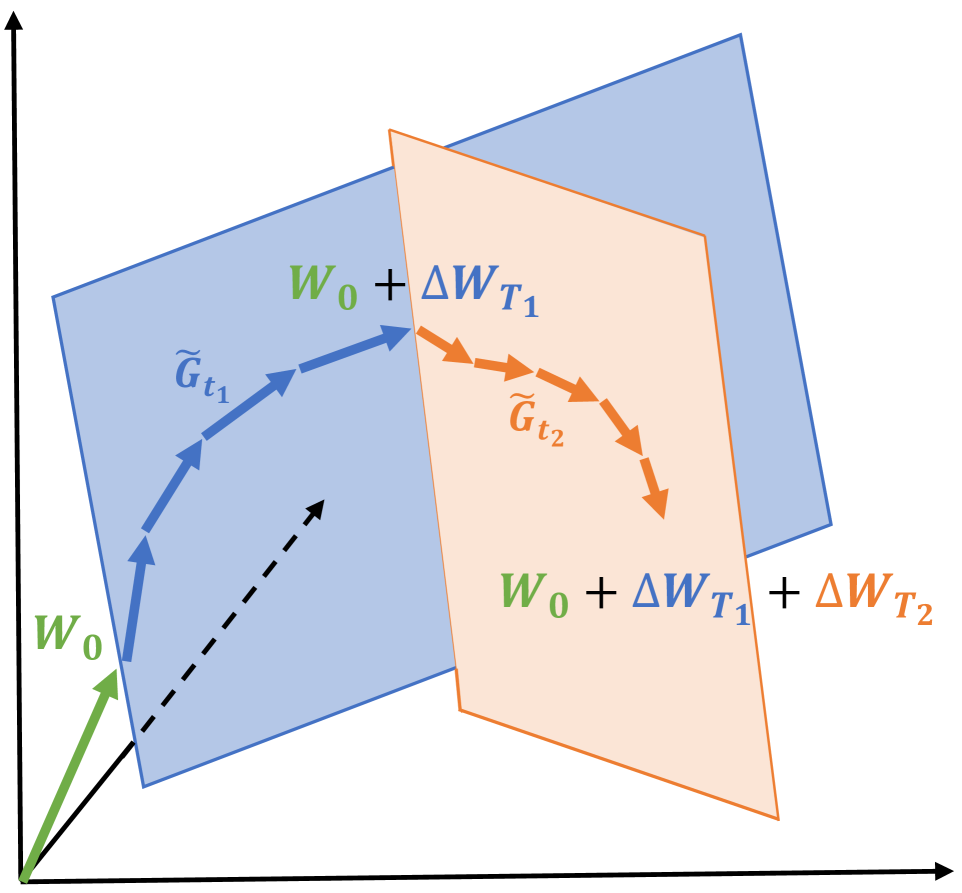
- Instead of restricting the weight matrices to be low-rank (like LoRA), GaLore observes that the *gradients* naturally become low-rank during training.
- It projects the gradient matrix into a small low-rank subspace before the optimizer step, drastically reducing the size of optimizer states (momentum/variance), then projects the update back to full rank for the weight update.
Architecture
The step-by-step training loop of GaLore.
Evaluation Highlights
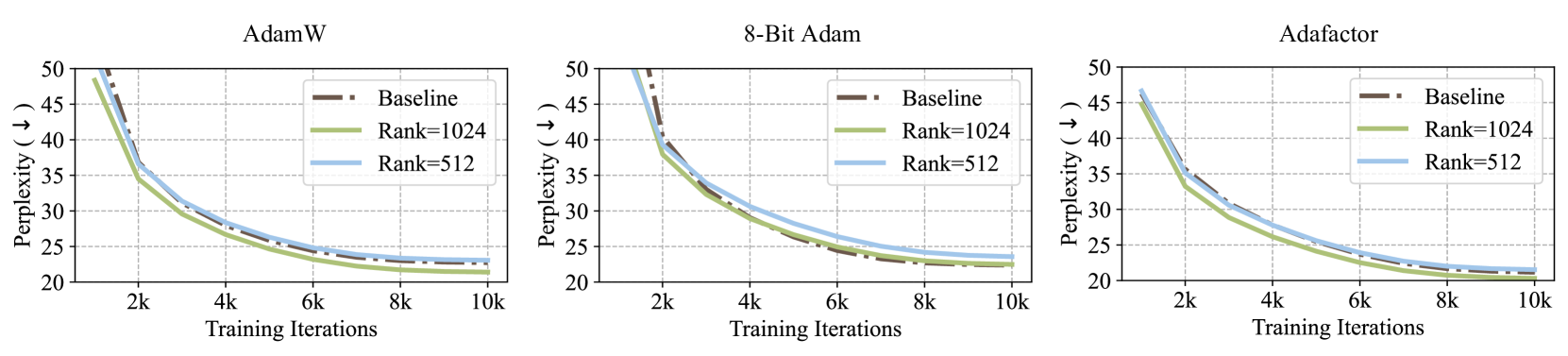
- Reduces optimizer state memory by up to 65.5% compared to full-rank BF16 baselines during LLaMA pre-training.
- Enables pre-training a LLaMA 7B model on a single 24GB consumer GPU (NVIDIA RTX 4090) without model parallelism or offloading.
- Achieves a GLUE score of 85.89 when fine-tuning RoBERTa-Base, outperforming LoRA's score of 85.61.
Breakthrough Assessment
9/10
Significantly lowers the barrier to entry for LLM pre-training by making it feasible on consumer hardware without performance compromises common in prior methods like LoRA.