📝 Paper Summary
LLM Serving Systems
KV Cache Optimization
Memory Management
vLLM introduces PagedAttention to manage KV cache using virtual memory concepts, enabling non-contiguous storage and flexible memory sharing to significantly increase serving throughput.
Core Problem
Existing LLM serving systems require contiguous memory allocation for the Key-Value (KV) cache, leading to severe fragmentation and waste because request lengths are unknown and dynamic.
Why it matters:
- KV cache is the dominant memory consumer in LLM serving; inefficient management limits batch size and throughput
- Pre-allocating memory for maximum sequence length wastes 60-80% of reserved space (internal fragmentation)
- Contiguous requirements prevent memory sharing between parallel samples or beam search candidates
Concrete Example:
A request to the 13B OPT model might reserve 1.6 GB for a potential 2048 tokens. If it only generates 50 tokens, the vast majority of that reserved contiguous block is wasted and cannot be used by other requests.
Key Novelty
PagedAttention & vLLM
- Treats KV cache like operating system virtual memory: divides cache into fixed-size blocks that can be stored in non-contiguous physical memory
- Uses a block table to map logical token sequences to physical GPU memory blocks, allowing dynamic allocation on demand
- Enables zero-copy memory sharing for advanced decoding (beam search, parallel sampling) via reference counting (similar to copy-on-write)
Architecture
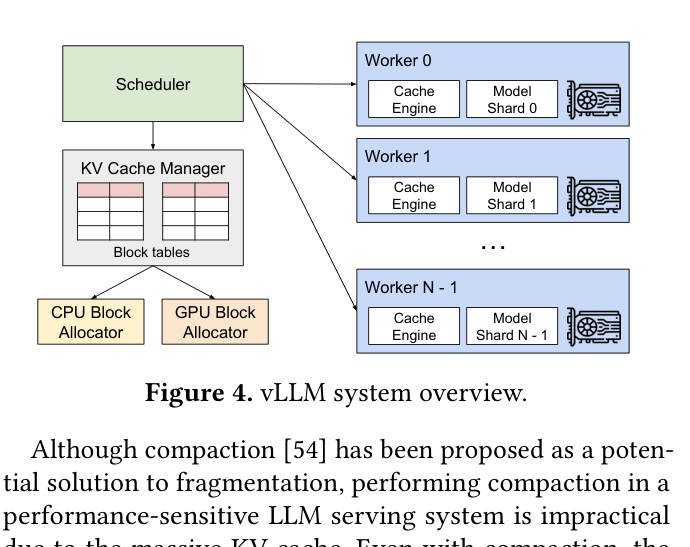
System architecture of vLLM showing the interaction between the centralized Scheduler, the KV Cache Manager, and distributed GPU Workers.
Evaluation Highlights
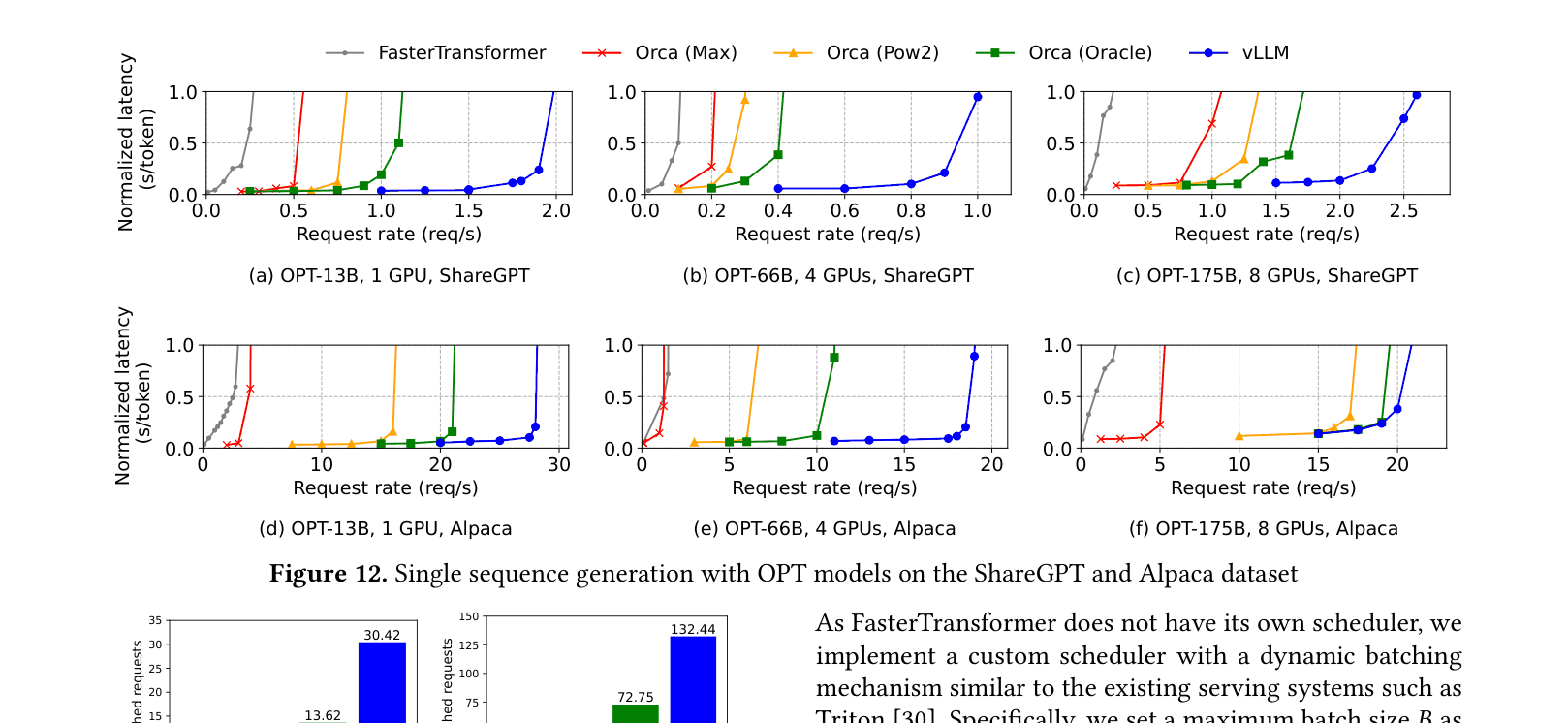
- Improves serving throughput by 2-4x compared to Orca and FasterTransformer with same latency level
- Reduces KV cache memory waste to near-zero (under 4% internal fragmentation) vs 60-80% in existing systems
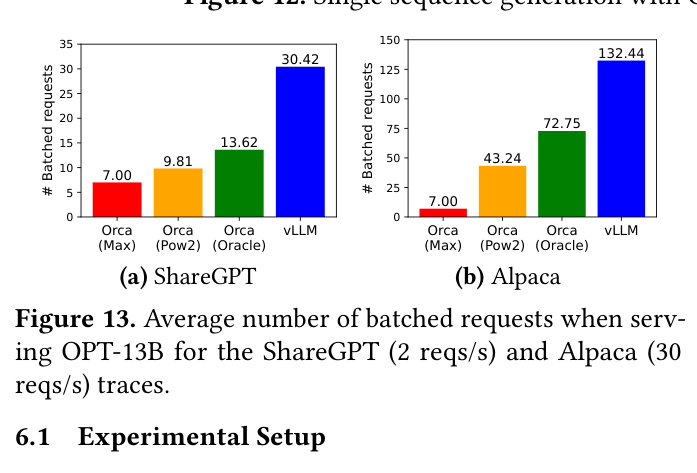
- Enables significantly larger batch sizes: ~132 requests/batch for vLLM vs ~73 for Orca (Oracle) on Alpaca dataset with OPT-13B
Breakthrough Assessment
9/10
Fundamental architectural shift in how LLM memory is managed. PagedAttention has become the industry standard for high-performance inference (adopted by TGI, TensorRT-LLM, etc.).