📝 Paper Summary
Conversational personalization
RAG-based personalization
Large Reasoning Models unexpectedly underperform general LLMs on retrieval-intensive personalization tasks due to divergent thinking, but the R2P framework fixes this via structured reasoning templates and dynamic intervention.
Core Problem
Despite superior reasoning capabilities, Large Reasoning Models (LRMs) fail to consistently outperform general-purpose LLMs in personalization tasks, particularly when retrieval (RAG) is involved.
Why it matters:
- Current assumptions that 'reasoning capabilities' automatically translate to better user adaptation are flawed, wasting computational resources on unoptimized models.
- LRMs struggle with 'divergent thinking' (exploring creative hypotheses) required for capturing nuanced user preferences, unlike the convergent tasks (math/code) they are optimized for.
- LRMs tend to ignore retrieved user history in favor of internal logic, leading to hallucinations or generic responses that fail to adhere to specific output formats.
Concrete Example:
When asked to paraphrase a tweet in a specific user's style using retrieved history, an LRM might ignore the style constraints to generate a 'logically correct' but generic paraphrase, whereas a standard LLM copies the style more effectively.
Key Novelty
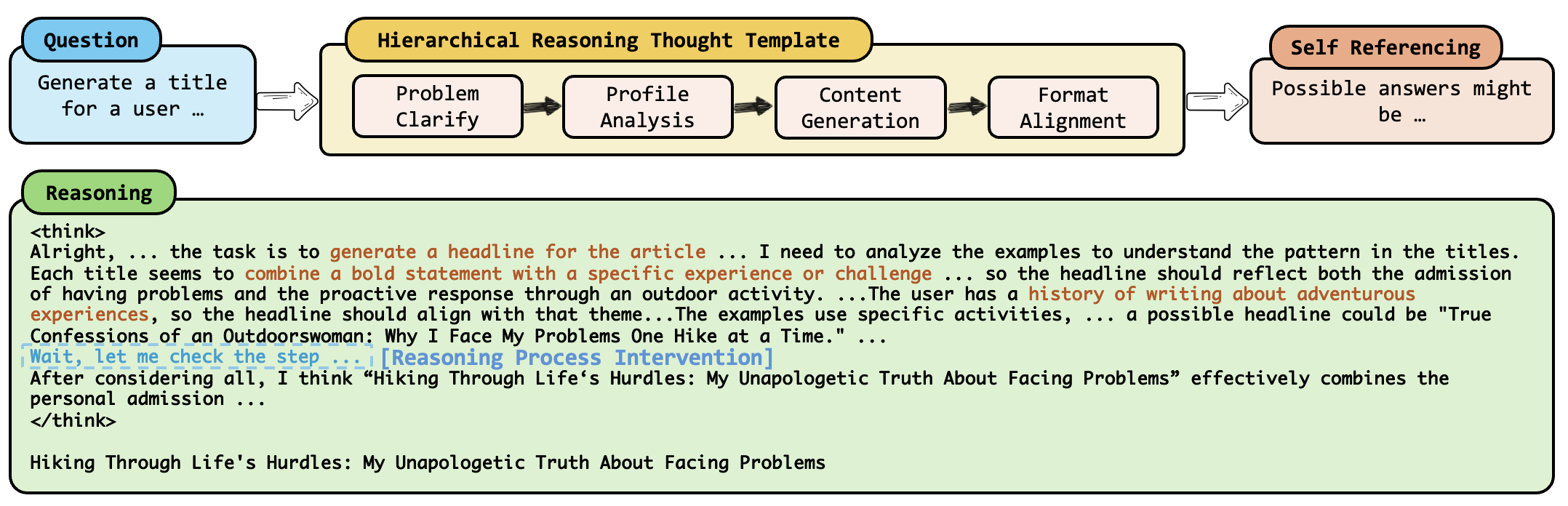
Reinforced Reasoning for Personalization (R2P)
- Imposes a 'Hierarchical Reasoning Thought' template on LRMs to structure their thinking process: analyze requirements -> synthesize user profile -> generate response.
- Introduces 'Reasoning Process Intervention' (RPI), a feedback loop that halts generation if the model skips a required reasoning step (like profile analysis) and forces a revision.
- Uses a 'Self-Referencing Module' where the model generates multiple candidate reasoning paths and synthesizes them into a final consistent output.
Architecture
The pipeline of the Reinforced Reasoning for Personalization (R2P) framework.
Evaluation Highlights
- In LaMP-1 (Citation Identification) with RAG (k=4), standard Llama-3-8B outperforms DeepSeek-R1-Distill-Llama-8B (0.760 vs 0.712 accuracy), highlighting LRM struggles.
- Proposed R2P framework achieves superior performance compared to baseline LRMs across LaMP benchmarks (quantitative improvement implied as 'significantly outperforms' but specific delta not explicitly tabulated in text summary).
- Analysis reveals larger general LLMs produce longer responses, whereas larger LRMs tend to generate shorter, more focused reasoning paths.
Breakthrough Assessment
7/10
Provides the first systematic evaluation showing LRMs are not a silver bullet for personalization and proposes a practical, training-free intervention framework to fix specific LRM pathologies (divergence, format drift).