📝 Paper Summary
User-profile based personalization
Prompt Optimization
Fermi personalizes LLMs by iteratively optimizing prompts using feedback from the model's own errors (mis-aligned responses) and dynamically selecting the best prompt for each query based on context.
Core Problem
Existing LLM personalization methods either rely on manual, suboptimal prompt engineering or require fine-tuning on shared user data, which raises privacy concerns.
Why it matters:
- LLMs often exhibit biases toward certain groups and fail to adapt to diverse individual needs without specific steering
- Manual prompt engineering is costly and fails to explore the search space effectively for each unique user
- Learning-based approaches (fine-tuning) often assume access to other users' data, violating privacy constraints
Concrete Example:
When a user asks a subjective question, a standard LLM might provide a generic or biased answer. Simple instructions like 'act as X' often fail. Fermi identifies these 'mis-aligned' responses (errors) on past questions and uses them to write a prompt that explicitly corrects the model's behavior for that user.
Key Novelty
Few-shot Personalization with Mis-aligned Responses (Fermi)
- Optimizes prompts by feeding the optimizer LLM not just scores, but also specific examples of 'mis-aligned responses' (where the model answered incorrectly), allowing it to diagnose and fix specific failure modes
- Uses 'Retrieval-or-Prompt' during inference: instead of using one fixed prompt, it retrieves relevant past user opinions for the current query and selects the prompt that performed best on those specific similar examples
Architecture
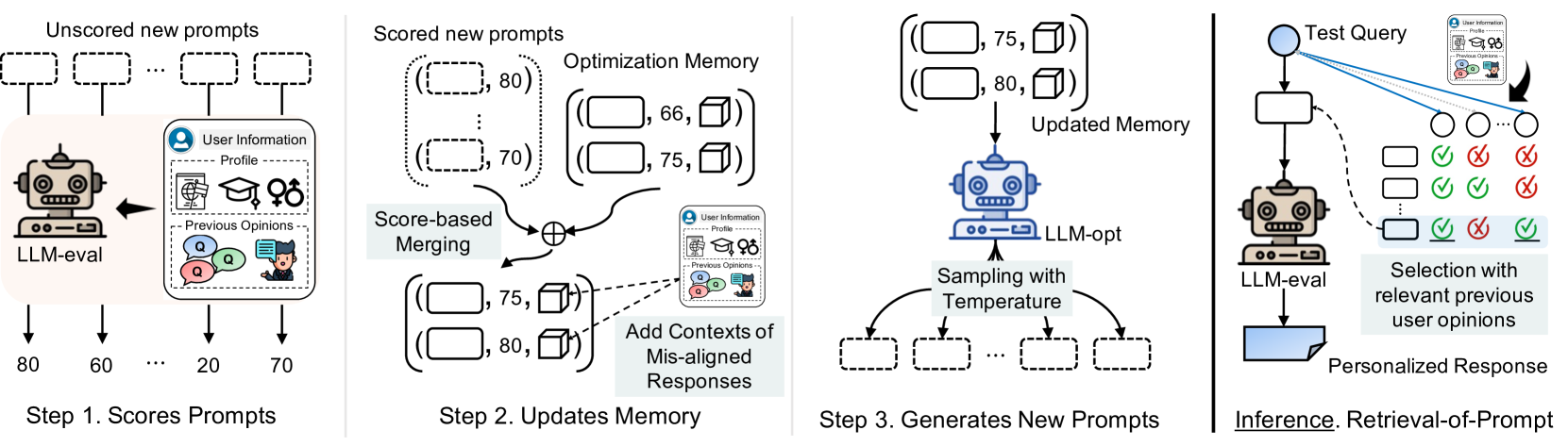
Overview of the Fermi framework, illustrating both the iterative optimization process (left) and the Retrieval-or-Prompt inference method (right).
Evaluation Highlights
- +6.8% average accuracy improvement on the first multiple-choice QA dataset compared to state-of-the-art prompt optimization baselines
- +4.1% average accuracy improvement on the second multiple-choice QA dataset compared to baselines
- Demonstrates that prompts personalized via one LLM transfer effectively to other LLMs (both API-based and open-source)
Breakthrough Assessment
7/10
Introduces a clever error-driven feedback loop for prompt optimization and a dynamic inference strategy. The gains are significant, though the core mechanism is an evolution of OPRO-style optimization.
