📝 Paper Summary
Memory recall
User-profile based personalization
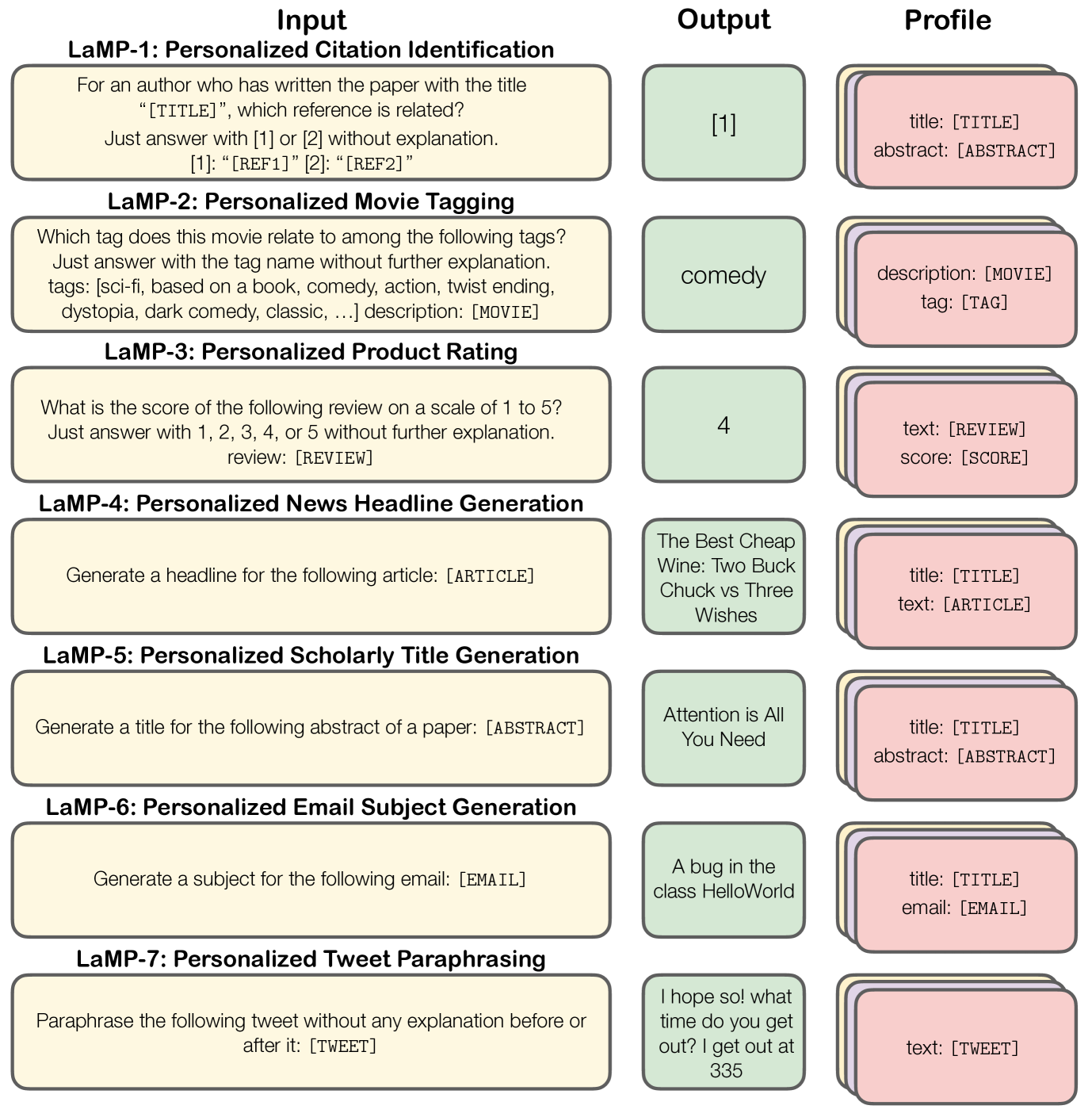
LaMP introduces a comprehensive benchmark for personalized LLMs and demonstrates that retrieving user-specific history for prompt augmentation significantly improves performance across seven diverse classification and generation tasks.
Core Problem
Existing NLP benchmarks like GLUE enforce a 'one-size-fits-all' evaluation, failing to assess how well Large Language Models adapt to individual user histories and preferences.
Why it matters:
- Real-world applications (search, email, recommendations) require tailoring outputs to unique user needs, not just generic correctness
- Current LLMs have limited context windows, making it difficult to process large, comprehensive user profiles directly in the prompt
- Personalization in LLMs remains understudied due to a lack of diverse, standardized datasets for training and evaluation
Concrete Example:
When asking an LLM to generate a news headline, a generic model produces a standard summary. However, a personalized model should mimic the specific stylistic patterns of a journalist based on their past articles, which standard benchmarks do not measure.
Key Novelty
LaMP Benchmark & Retrieval-Augmented Personalization
- Constructs a massive benchmark of 7 diverse tasks (e.g., citation prediction, email subject generation) where the correct output depends on a specific user's history
- Proposes a retrieval-based personalization framework where relevant items from a user's potentially huge profile are fetched and injected into the LLM context only when needed
Architecture
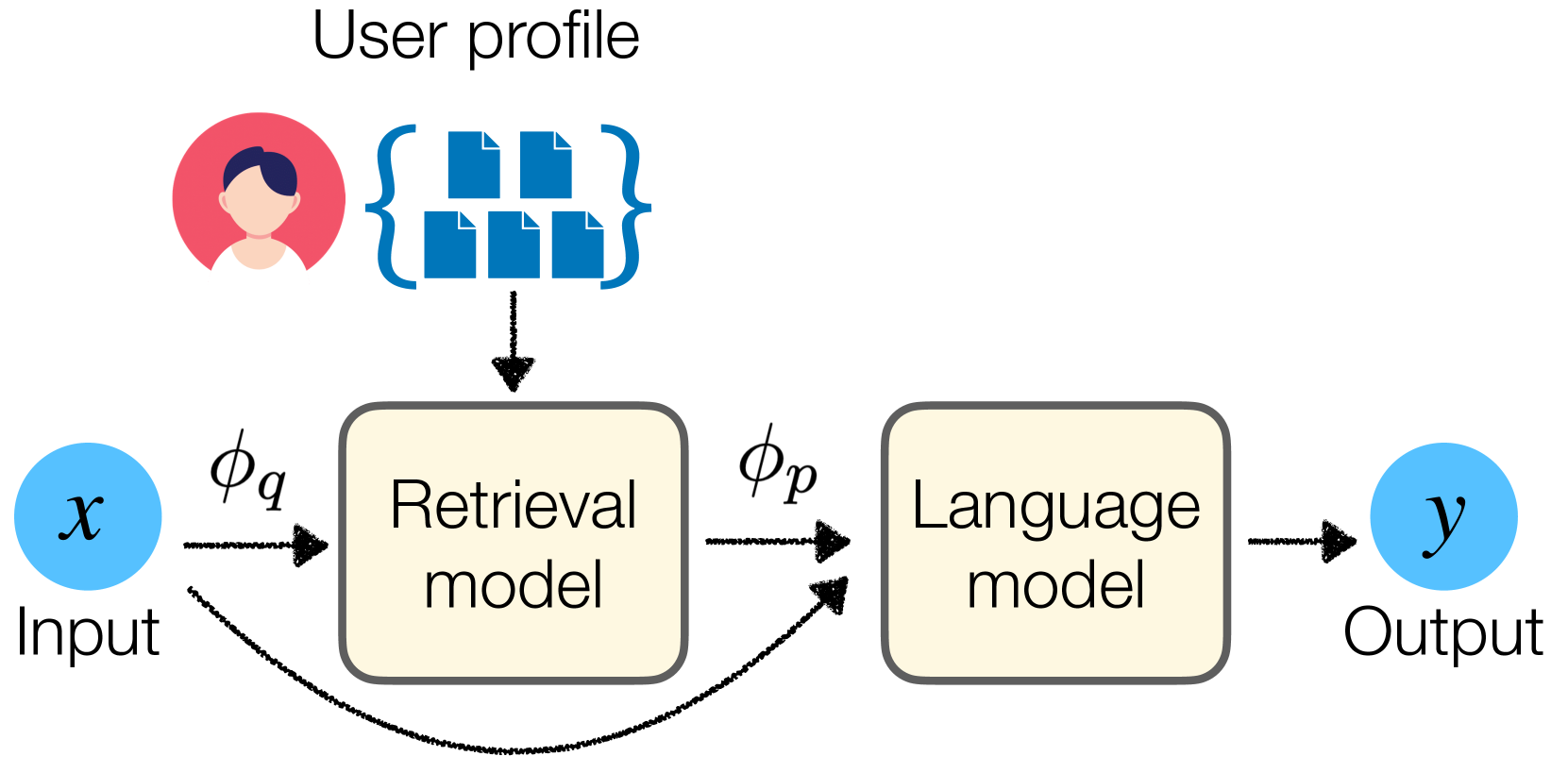
The retrieval augmentation framework for personalizing LLMs. It illustrates how a user profile is processed to retrieve relevant historical items, which are then used to augment the input prompt for the LLM.
Evaluation Highlights
- +23.5% relative average improvement across the benchmark when fine-tuning language models with the proposed personalized augmentation technique
- +12.2% relative average improvement in zero-shot settings (e.g., FlanT5-XXL) when using the proposed retrieval augmentation method
- Retrieval-augmented personalization consistently outperforms non-personalized baselines across both text classification and generation tasks
Breakthrough Assessment
9/10
Establishes the standard benchmark for personalized LLMs (LaMP), filling a critical gap. The proposed retrieval methods are practical and effective, offering a clear path for future research.