📝 Paper Summary
Personalized generation evaluation
LLM-as-a-Judge
LLMs often fail as personalized judges due to insufficient persona information, but incorporating verbal uncertainty estimation significantly improves reliability by identifying high-confidence samples.
Core Problem
Standard LLM-as-a-Judge approaches for personalization are unreliable (low agreement with ground truth) because available persona descriptions often lack predictive power for specific preferences, a phenomenon termed 'persona sparsity'.
Why it matters:
- Current alignment processes assume homogeneous human preferences, ignoring individual values crucial for global user bases
- Researchers increasingly rely on LLM-as-a-Judge for personalization tasks without validating if the model can actually infer preferences from the given persona profiles
- Persona descriptions (e.g., 'I am a doctor') often do not provide enough context to determine specific preferences (e.g., favorite beverage), leading to hallucinations or random guesses by the judge
Concrete Example:
Knowing a user is a doctor doesn't help predict their beverage preference. In the Empathetic Conversation task, models fail (<60% accuracy) because general persona traits don't reliably predict how a specific user would respond to a negative news article.
Key Novelty
Certainty-Enhanced LLM-as-a-Personalized-Judge
- Introduce a verbal uncertainty estimation step into the judging pipeline, asking the LLM to rate its confidence (1-100) alongside its preference prediction
- Use this confidence score to filter out 'persona sparsity' cases where the provided profile is insufficient to make a grounded judgment, retaining only high-certainty samples
Architecture
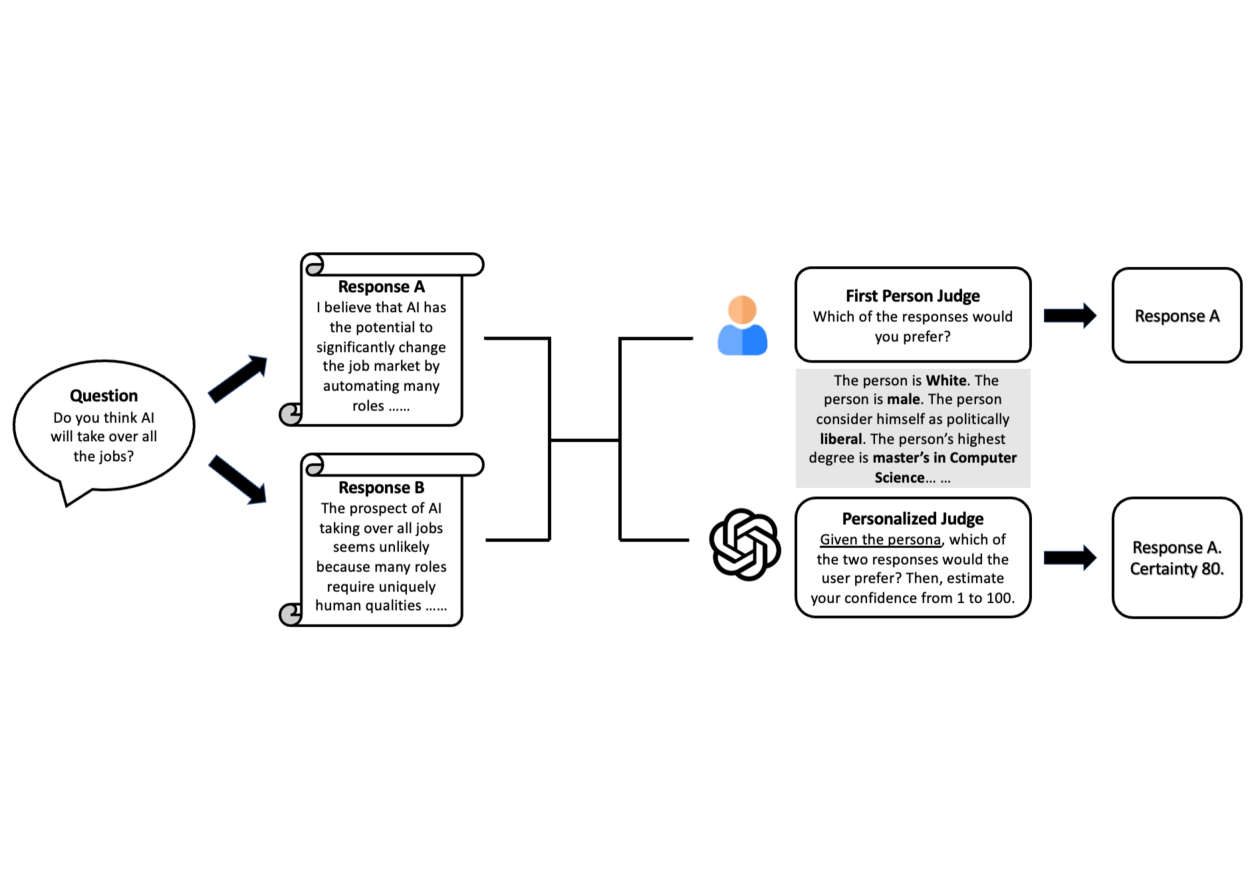
Workflow of the Certainty-Enhanced LLM-as-a-Personalized-Judge
Evaluation Highlights
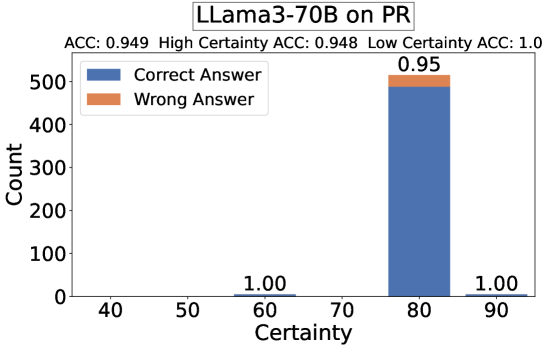
- Standard LLM-as-a-Personalized-Judge achieves only 72.5% accuracy on binary tasks, significantly lower than the 80%+ typically reported for general LLM-as-a-Judge tasks
- Filtering for high-certainty samples (score ≥ 80) improves GPT-4's agreement with human ground truth to ~80% across tasks
- On high-certainty samples, GPT-4 outperforms third-person human annotators (79.2% vs 71.4%) on the OpinionQA dataset
Breakthrough Assessment
7/10
Identifies a critical flaw in current personalization evaluation (persona sparsity) and provides a simple, effective solution (uncertainty estimation) that restores reliability to the metric.