📝 Paper Summary
Robot Personalization
Constraint-based Planning
Active Learning
CBTL enables robots to personalize safely by learning user-specific preferences as constraints that operate strictly within the valid solution space of pre-defined safety and competency rules.
Core Problem
Robots face a tension between safety and flexibility: over-constrained systems cannot adapt to user preferences, while under-constrained systems risk dangerous behavior.
Why it matters:
- Generalist robots in homes or hospitals must adapt to unique user needs (e.g., dietary restrictions, mobility limits) without requiring expert reprogramming.
- Existing personalization methods often sacrifice safety guarantees or require users to fully specify preferences upfront rather than learning continually over time.
- Current approaches struggle to balance exploration (finding what the user likes) with the strict requirements of physical safety.
Concrete Example:
In an assisted feeding scenario, a robot needs to know that a user loves tacos but hates cilantro, or has a limited range of motion. A standard robot might treat all solutions (e.g., any edible bite) as equal, potentially serving unwanted food or moving the arm in a way that startles the user.
Key Novelty
Coloring Between the Lines (CBTL)
- Treats the set of all safe plans (the 'null space' of safety constraints) as a canvas for personalization, selecting only the safe options that also satisfy learned user preferences.
- Uses active learning to purposely select plans that maximize uncertainty about the user's preferences, rapidly narrowing down the personalized constraints without violating safety rules.
Architecture
Overview of the Coloring Between the Lines (CBTL) approach.
Evaluation Highlights
- Web-based user study (N=60) shows participants significantly prefer CBTL choices over a non-personalized baseline (p < 0.005, Wilcoxon-Signed Rank test).
- Demonstrates zero-shot generalization on a real robot: occlusion preferences learned during feeding were successfully applied to a new drinking task without additional training.
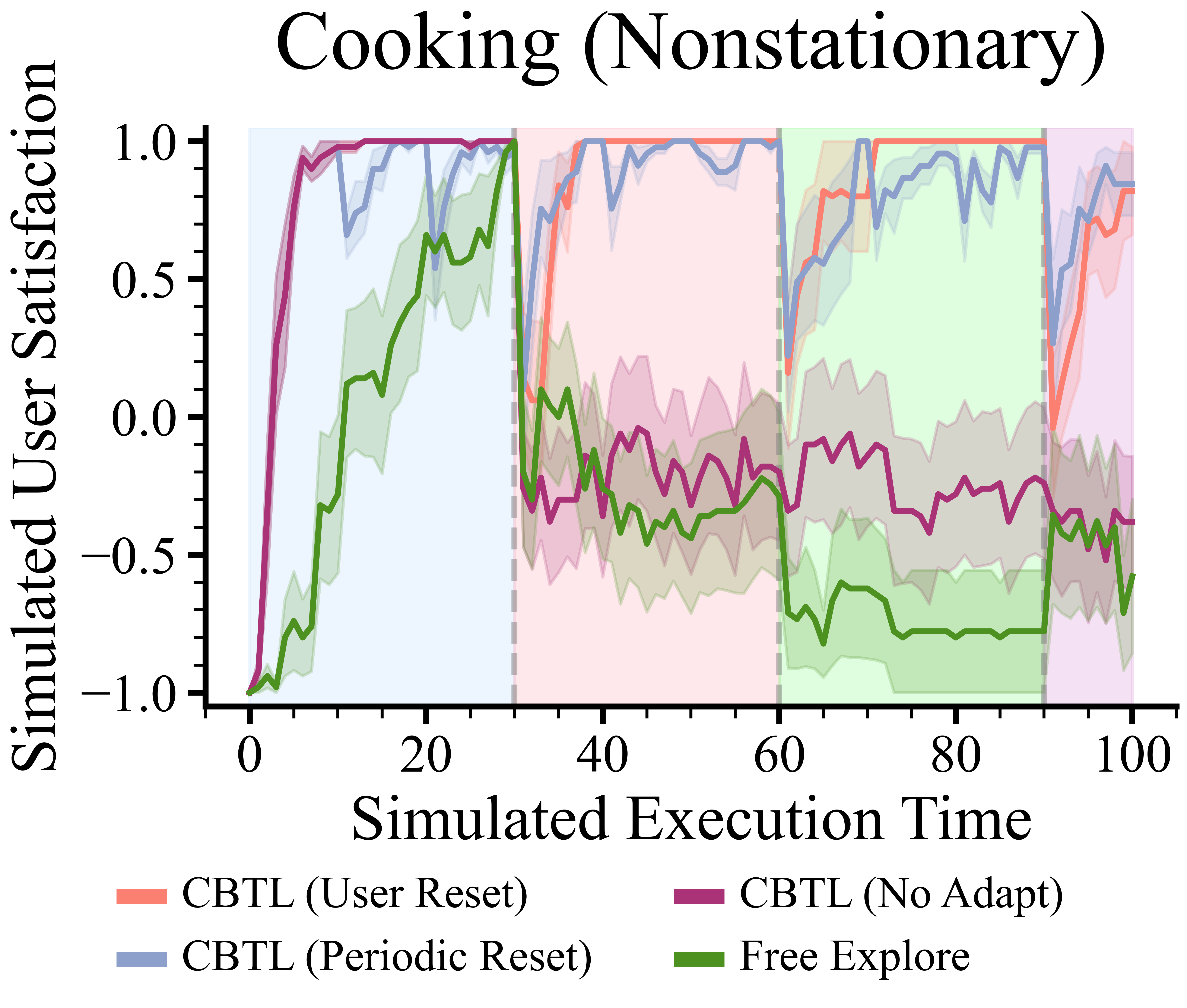
- Consistently achieves more effective personalization with fewer interactions than baselines (Free Explore, Epsilon-Greedy) across three simulation environments (Cooking, Cleaning, Books).
Breakthrough Assessment
8/10
A strong conceptual advance unifying safety and personalization via constraint null spaces. Effectively combines TAMP, LLMs, and active learning for practical robotics.