📝 Paper Summary
Community Question Answering (cQA)
Personalized Information Retrieval
SE-PQA introduces a large-scale, real-world dataset for personalized community question answering, featuring over 1 million questions with rich user interaction metadata, and demonstrates that simple personalization models significantly improve retrieval effectiveness.
Core Problem
Existing datasets for personalized search are either synthetic, lack rich user-level features, or have severe privacy/ethical issues (e.g., AOL logs), hindering the development of deep learning models for personalization.
Why it matters:
- Lack of high-quality, large-scale public data prevents robust evaluation of neural personalization models.
- Privacy concerns and anonymization in existing query logs often strip away the user context necessary for training effective personalizers.
- Synthetically enriched datasets (like PERSON or Amazon product search) rely on strong assumptions that may not reflect real-world user behavior.
Concrete Example:
In current datasets like AOLIA, user relevance is inferred from clicks without text content, or synthetic queries are generated from product hierarchies (e.g., 'photo digital camera lenses'). SE-PQA provides actual user questions and explicit 'best answer' selections, allowing models to distinguish which answer a specific user prefers among multiple correct ones.
Key Novelty
Large-Scale Real-World cQA Personalization Benchmark
- Curates a massive dataset from 50 StackExchange communities with over 1 million questions, preserving rich social metadata (votes, tags, badges, user history).
- Defines a 'Personalized TAG model' baseline that ranks answers higher if the answerer's history shares topical tags with the questioner's history, modeling interest alignment.
Architecture
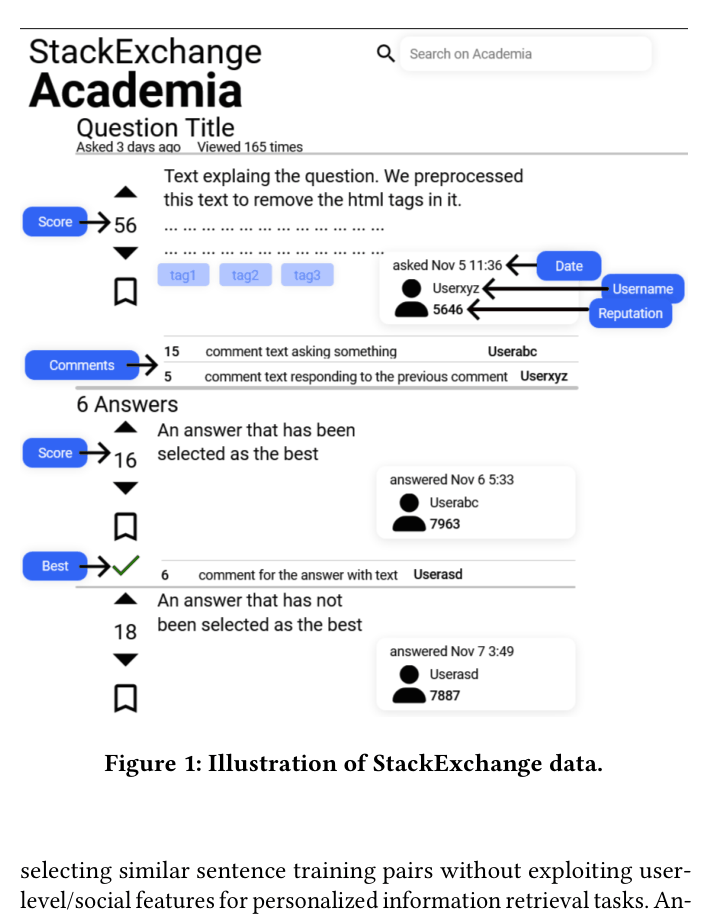
Conceptual illustration of the StackExchange data structure used to build SE-PQA, highlighting relationships between Users, Questions, Answers, Votes, and Tags.
Evaluation Highlights
- +8% improvement in MAP@100 on the personalized test set when adding the simple TAG personalization model to a T5-base re-ranker.
- Personalization yields statistically significant gains for all tested neural models (DistilBERT, MiniLM, MonoT5) on the personalized dataset version.
- Multi-domain personalization (training across 50 communities) is more effective than single-domain personalization, which fails to improve performance in 25 out of 50 individual communities.
Breakthrough Assessment
7/10
Significant contribution as a resource paper filling a major gap in public personalized IR datasets. The modeling contribution (TAG) is simple but effective, serving primarily to validate the dataset's utility.