📝 Paper Summary
Conversational personalization
Benchmark datasets
PersonaLens is a benchmark for evaluating personalized task-oriented assistants using diverse simulated user profiles, situational contexts, and an automated judge agent to assess personalization quality.
Core Problem
Existing personalization benchmarks focus on chit-chat or narrow domains, lacking the complex task-oriented structure and rich contextual history needed to evaluate modern AI assistants.
Why it matters:
- Current benchmarks like PersonaChat lack the goal-oriented nature of real assistants, while others like PENS cover only narrow domains like movie recommendations
- Evaluating personalization requires checking if assistants adapt to user history and preferences while successfully completing tasks, which static datasets struggle to capture
- Human-in-the-loop evaluation is costly and hard to scale for complex multi-turn interactions
Concrete Example:
A user might want to book a trip involving flights, hotels, and cars. A generic assistant asks for details from scratch, whereas a personalized assistant should recall the user's budget, preference for window seats, and loyalty programs from past interactions to streamline the booking.
Key Novelty
PersonaLens: Multi-Agent Evaluation Framework for Personalized Task-Oriented Dialogue
- Simulates 1,500 diverse user profiles with rich attributes (demographics, preferences, histories) based on real-world data (PRISM Alignment)
- Generates dynamic situational contexts (location, device, time) specific to 111 tasks across 20 domains to test adaptability
- Uses a dual-agent setup: a User Agent that simulates realistic behavior and a Judge Agent that evaluates personalization and task success without human intervention
Architecture
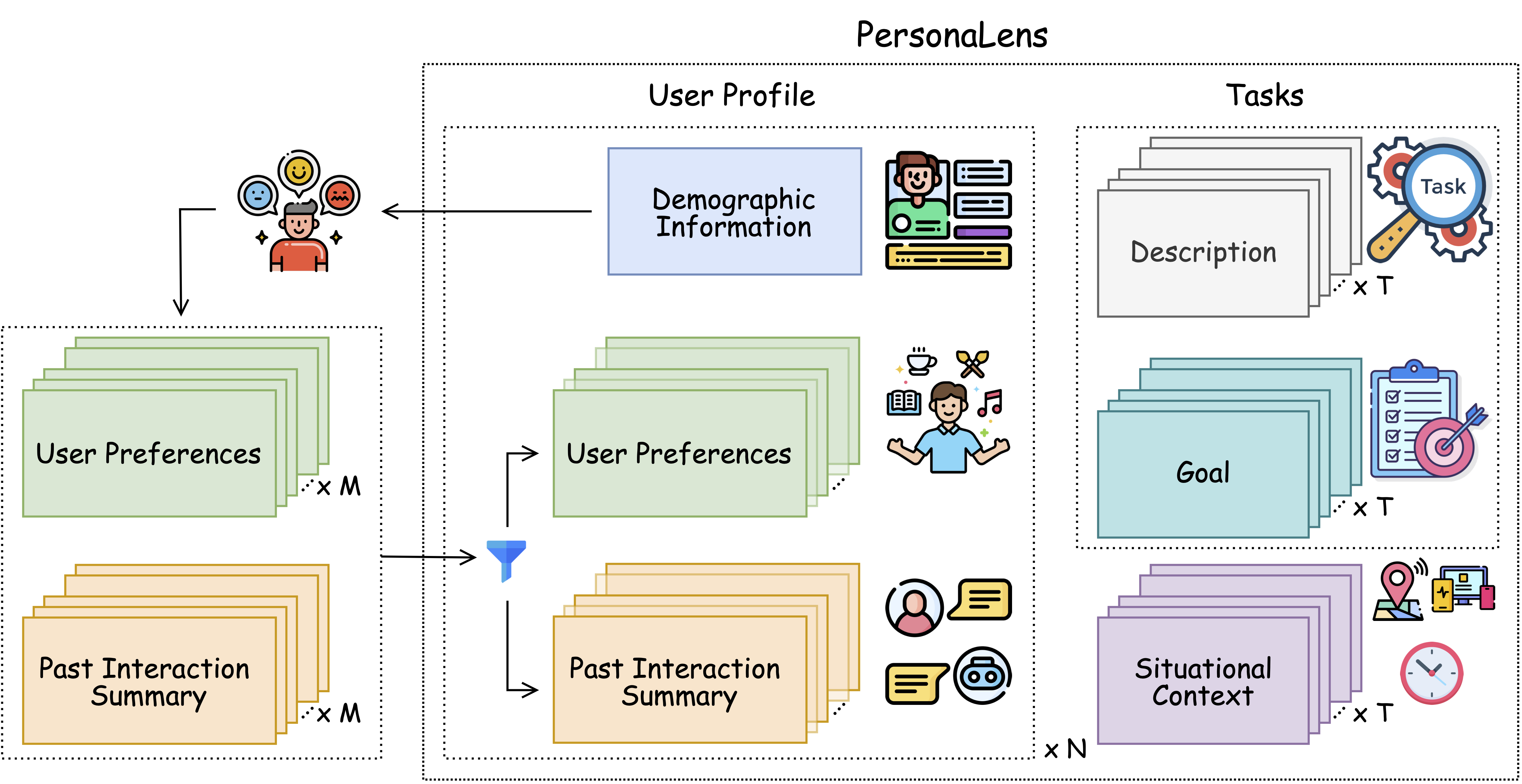
Overview of the PersonaLens benchmark components and flow
Evaluation Highlights
- Benchmark contains 1,500 user profiles and 111 tasks across 20 diverse domains
- Includes 86 single-domain tasks and 25 multi-domain tasks requiring cross-domain reasoning
- Validates internal consistency using an LLM-based checker and manual inspection, confirming high lexical diversity compared to existing datasets
Breakthrough Assessment
8/10
Significantly advances personalization evaluation by moving beyond chit-chat/recommendation into complex task-oriented dialogue with a scalable, automated agent-based framework.