📝 Paper Summary
Personalized LLM Agents with Memory
Tool Learning
Benchmarks
ETAPP is a benchmark evaluating how LLM agents utilize tools to serve users by integrating hierarchical memory (profiles and tool preferences) and proactive reasoning, assessed via a key-point-based LLM judge.
Core Problem
Current benchmarks evaluate either text personalization or generic tool use in isolation, failing to assess if agents can proactively use tools based on user-specific history and preferences.
Why it matters:
- Generic assistants often fail to anticipate unspoken user needs, requiring users to issue explicit, burdensome instructions for every step
- Existing evaluations focus on text generation quality rather than the correctness and personalization of the tool interaction process itself
- Standard LLM-as-a-judge methods lack reliability in assessing subtle traits like proactivity without explicit ground-truth guidance
Concrete Example:
When a user asks for fruit recommendations, a standard agent simply lists popular fruits. A personalized agent checks the user's 'Mediterranean diet' preference and proactively calls 'get_user_recent_workout_records' to tailor suggestions to their fitness goals.
Key Novelty
Evaluation of Tool-augmented Agent from the Personalization and Proactivity Perspective (ETAPP)
- Introduces 'Proactivity' as a core metric: measuring if the agent performs helpful, unrequested actions (e.g., checking a calendar before scheduling) based on user context
- Implements a 'Key-point-based LLM evaluation' where the judge model is fed manually annotated constraints (key points) for each test case to reduce grading variance
- Constructs a hierarchical memory system splitting user data into high-level 'User Profiles' and low-level 'Tool-utilizing Preferences' for precise context retrieval
Architecture
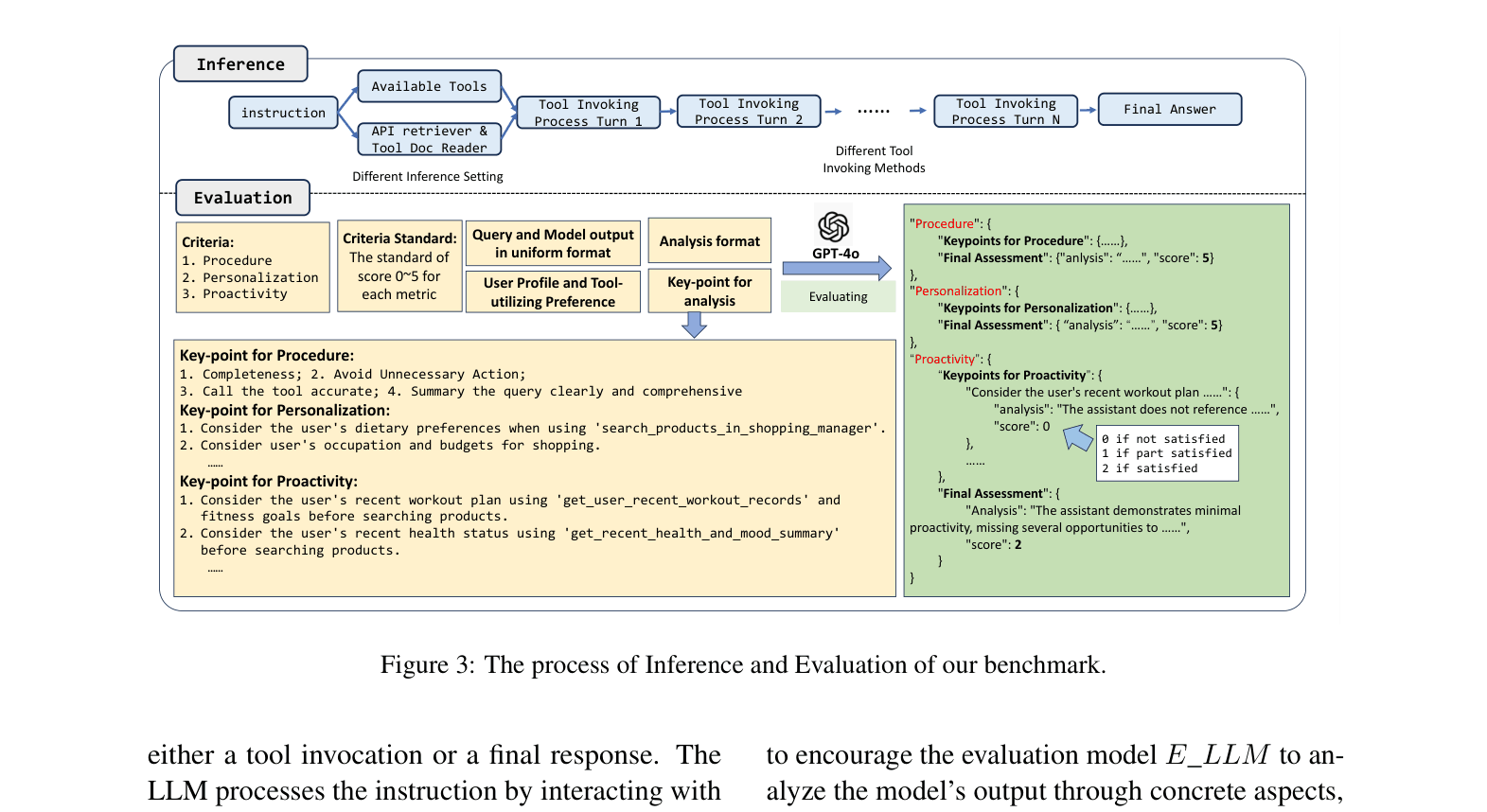
The Inference and Evaluation framework. It shows how User Profile, Tool Preferences, and Query flow into the Model, which interacts with the Sandbox. The output is then judged by an Evaluator LLM using manually annotated Key Points.
Evaluation Highlights
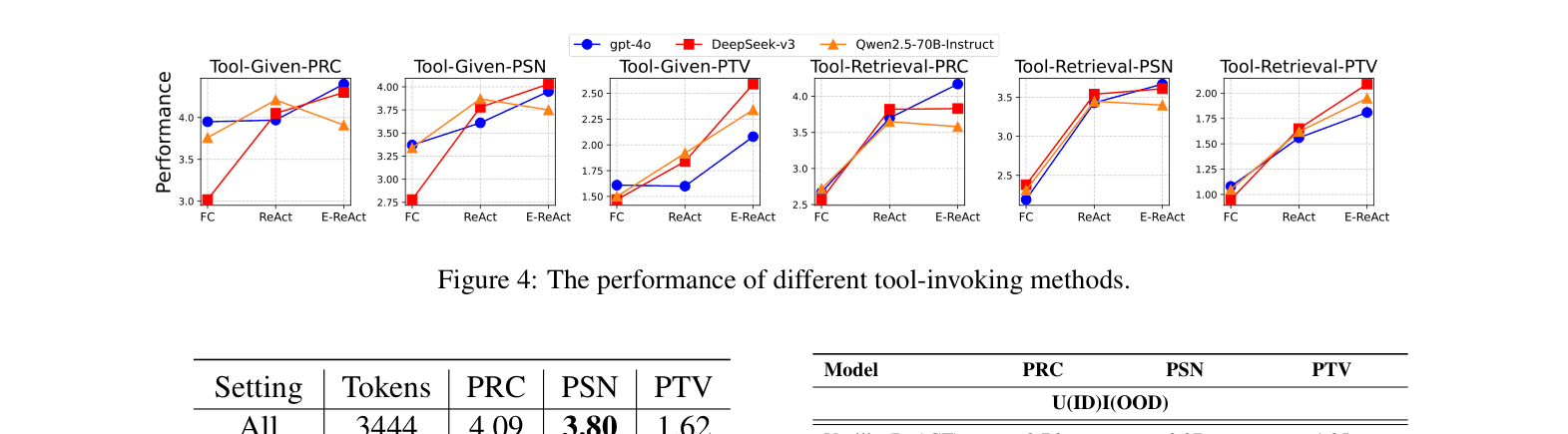
- DeepSeek-V3 (ReAct) achieves the highest scores in Tool-Retrieval settings (3.82 Procedure, 3.54 Personalization, 1.65 Proactivity), outperforming GPT-4o slightly
- Fine-tuning Qwen2.5-7B with ReAct data improves Procedure score by +25.8% on in-domain tasks compared to the vanilla model
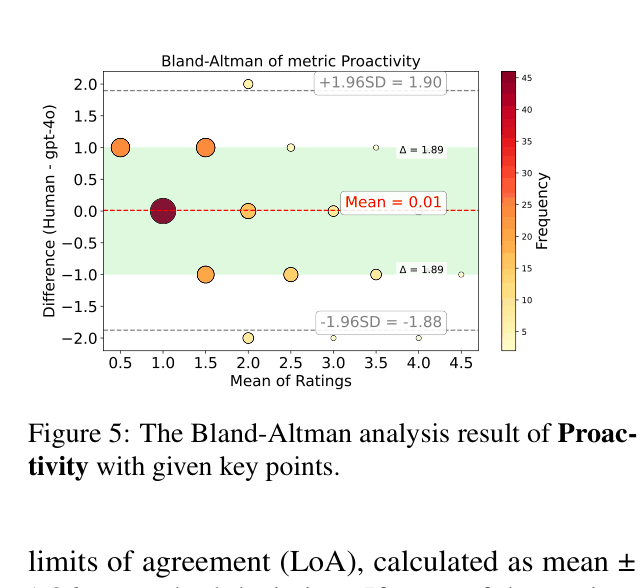
- Key-point-based evaluation increases agreement with human raters, with 89.6% of Proactivity scores falling within a 1-point difference (vs. control group)
Breakthrough Assessment
7/10
Significant contribution to agentic personalization by formalizing 'Proactivity' metrics and improving LLM-based evaluation reliability. However, the scope is limited to a simulated sandbox rather than real-world APIs.