📝 Paper Summary
Personalized Assistants (PAs)
Memory Utilization in LLMs
The paper introduces RPEval to benchmark 'irrational personalization' in LLMs and proposes RP-Reasoner, a pragmatic inference module that selectively integrates memory by estimating query likelihood and intent priors.
Core Problem
Current LLM-based assistants practice 'Literal Personalization' (L1), indiscriminately appending retrieved memories to context even when irrelevant or conflicting with the user's current intent.
Why it matters:
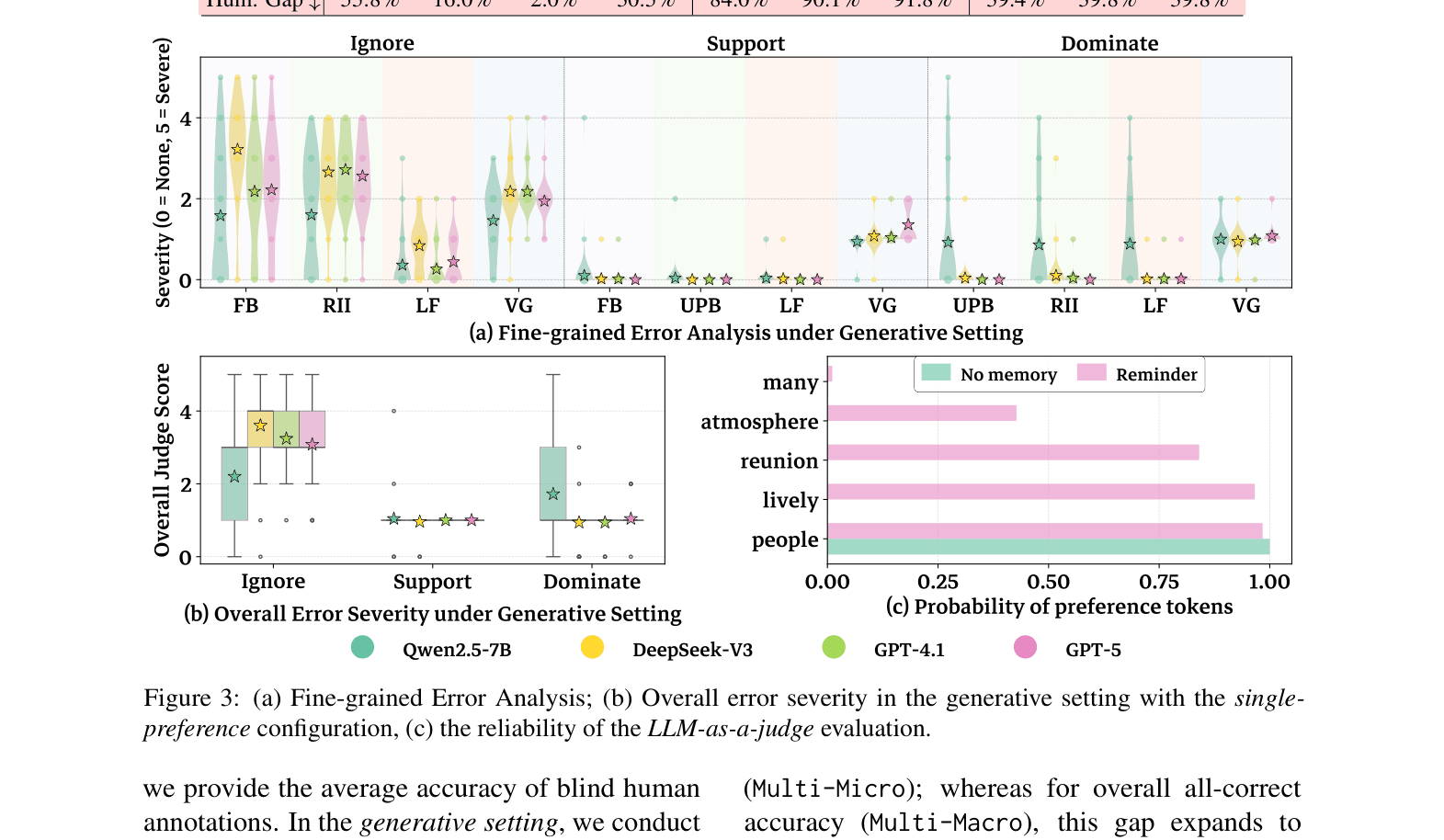
- Irrelevant memory injection leads to 'Filter Bubbles' where general needs are ignored in favor of niche preferences (e.g., recommending rock music for a relaxing lunch break)
- Existing benchmarks assume memory is always dominant, failing to test the assistant's ability to suppress irrelevant information
- Real-world queries are often under-specified, requiring assistants to actively reason about whether to apply sparse, fragmented user profiles
Concrete Example:
A user with a preference for 'strong rhythm music' asks for 'relaxing audio for school'. A standard assistant mistakenly incorporates the preference, recommending 'Game Soundtrack Dark Horse', which conflicts with the relaxing intent. RP-Reasoner infers the conflict and correctly ignores the memory.
Key Novelty
Rational Personalization (L2) via Pragmatic Reasoning
- Reframes personalization as a Bayesian inference task where the assistant must reverse-engineer the user's latent intent from their surface-level query
- Uses 'Counterfactual Elimination': if the user truly wanted to use a specific preference, they would have likely phrased the query differently to trigger it
- Separates memory usage into 'Query Likelihood' (does the query imply the preference?) and 'Intent Prior' (is the preference generally likely?) to score applicability
Architecture
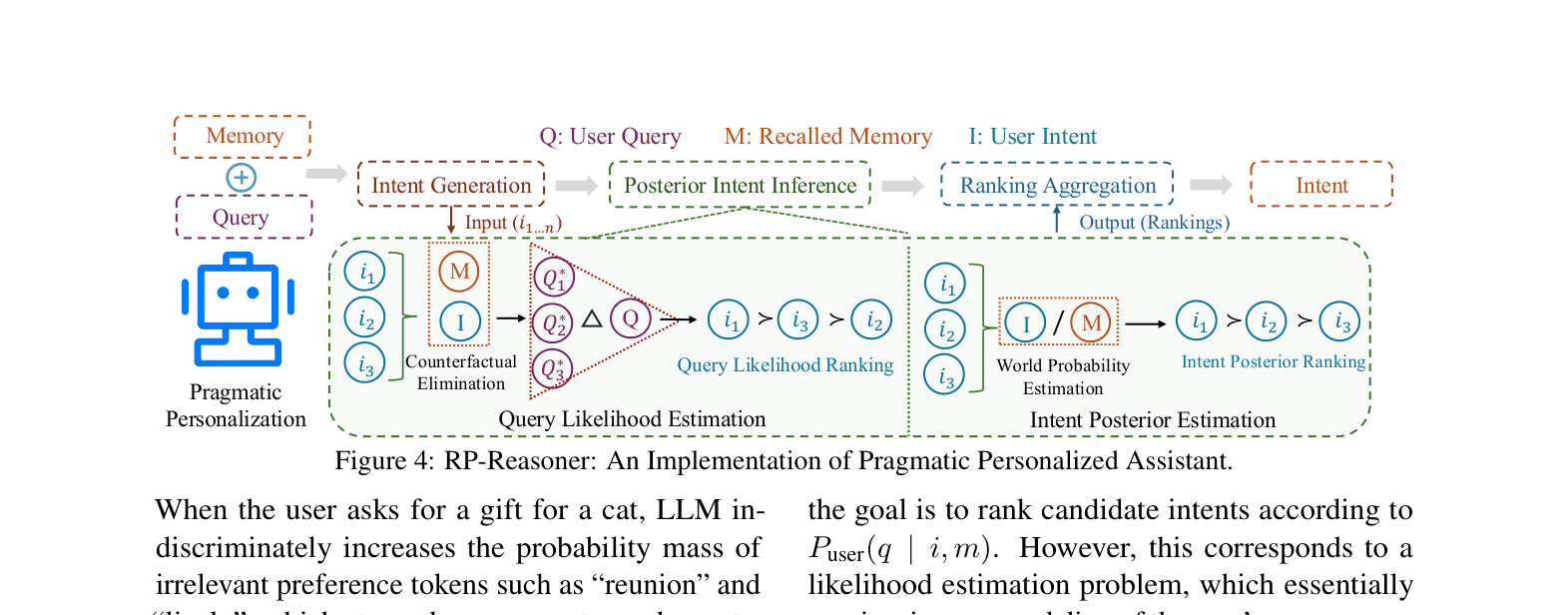
The inference pipeline of RP-Reasoner, detailing how it selects the best intent from candidates.
Evaluation Highlights
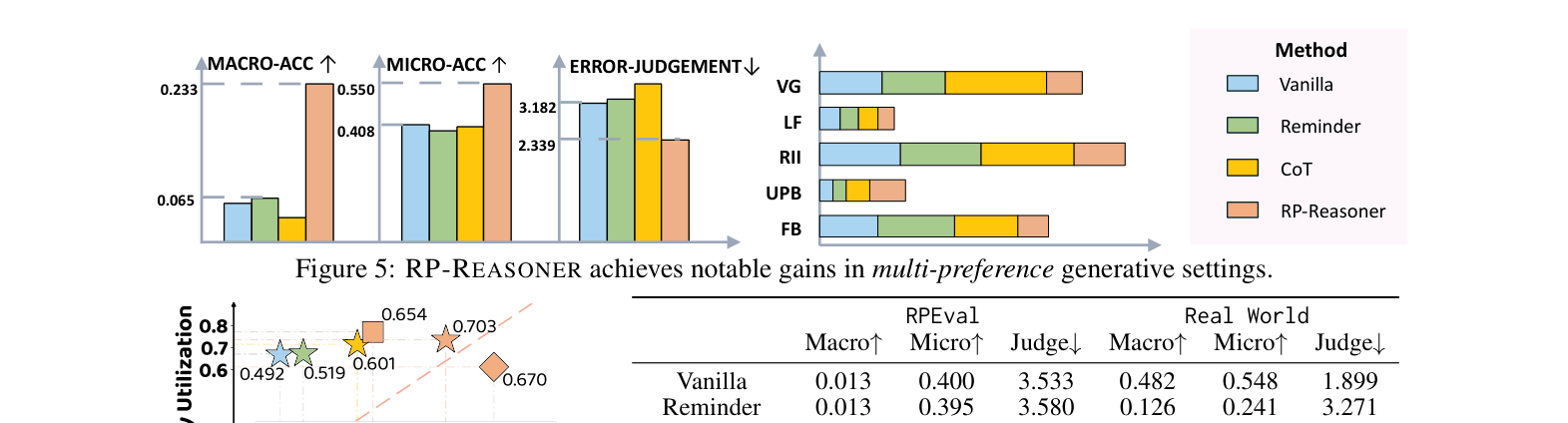
- RP-Reasoner achieves a ~35% improvement in Micro-Accuracy and reduces error severity by 26% on the RPEval benchmark compared to baselines
- Resolves 80% of bad cases in a large-scale commercial personalized assistant deployment
- Reveals an 'inverse scaling' effect where more capable models (like GPT-5) are actually worse at ignoring irrelevant preferences due to stronger attention mechanisms
Breakthrough Assessment
8/10
Identifies a critical, overlooked failure mode in personalized agents (irrational over-personalization) and provides both a solid benchmark and an effective, theoretically grounded inference-time solution.